OTTER: A Vision-Language-Action Model with Text-Aware Visual Feature Extraction
作者: Huang Huang, Fangchen Liu, Letian Fu, Tingfan Wu, Mustafa Mukadam, Jitendra Malik, Ken Goldberg, Pieter Abbeel
分类: cs.RO, cs.CV
发布日期: 2025-03-05 (更新: 2025-12-30)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出OTTER以解决视觉语言行动模型的特征提取问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言行动 特征提取 零样本泛化 机器人控制 多模态学习
📋 核心要点
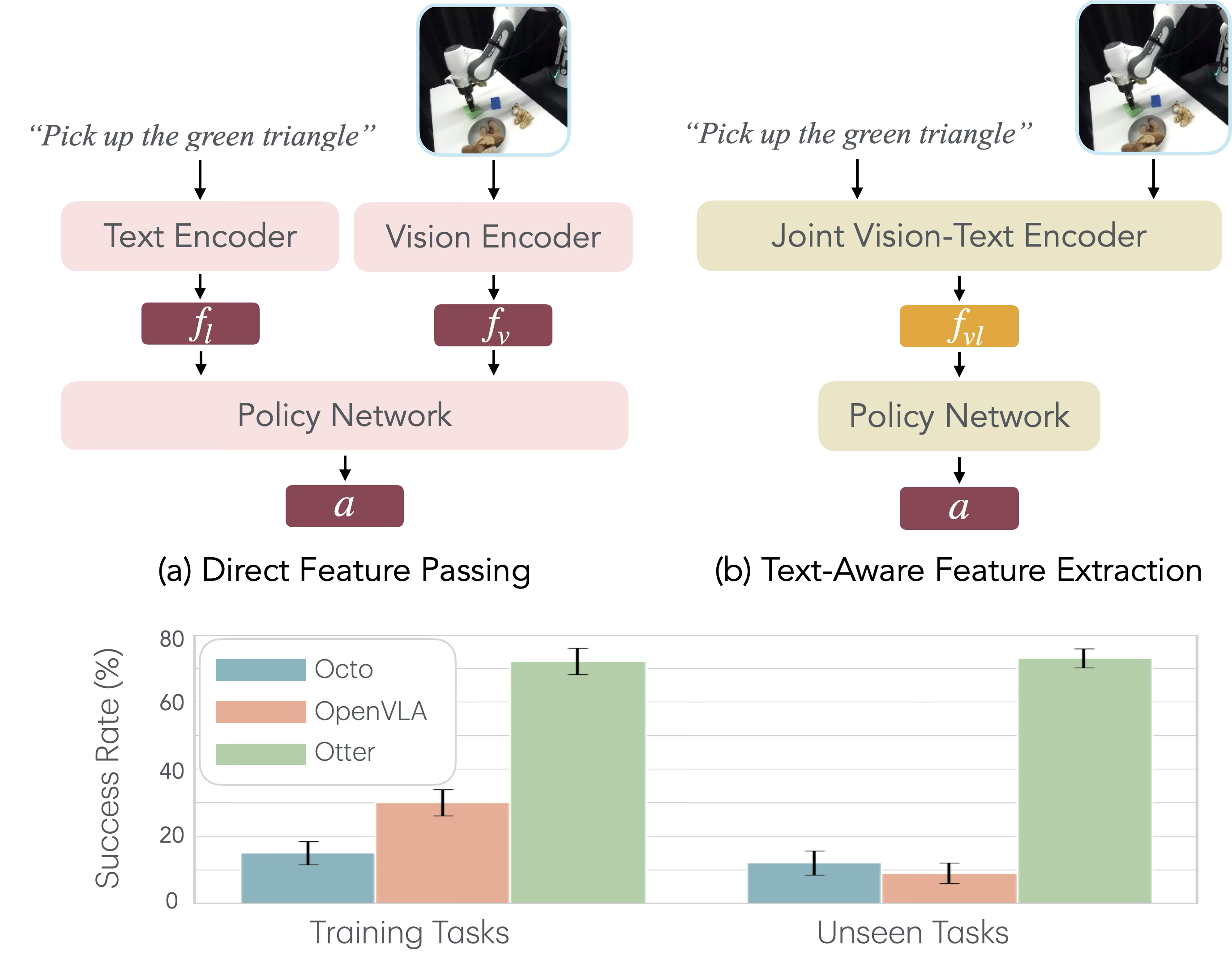
- 现有的视觉语言行动模型在特征提取上存在不足,导致预训练的语义对齐被破坏。
- OTTER通过显式的文本感知视觉特征提取,选择性地提取与任务相关的视觉特征,保持预训练模型不变。
- 实验结果表明,OTTER在模拟和真实环境中显著优于现有模型,展现出强大的零样本泛化能力。
📝 摘要(中文)
视觉语言行动(VLA)模型旨在根据视觉观察和语言指令预测机器人动作。现有方法需要对预训练的视觉语言模型(VLMs)进行微调,导致视觉和语言特征独立输入下游策略,从而降低了预训练的语义对齐。本文提出OTTER,一种新颖的VLA架构,通过显式的文本感知视觉特征提取来利用现有的对齐。OTTER选择性地提取与任务相关的视觉特征,并将其传递给策略变换器,从而保持预训练的视觉语言编码器不变。这使得OTTER能够保留和利用从大规模预训练中学习到的丰富语义理解,展现出强大的零样本泛化能力。在模拟和真实世界实验中,OTTER显著优于现有的VLA模型,展示了对新物体和环境的强大零样本泛化能力。
🔬 方法详解
问题定义:本文旨在解决现有视觉语言行动模型在特征提取过程中的不足,尤其是如何有效利用预训练的视觉语言模型而不破坏其语义对齐。现有方法通常需要对预训练模型进行微调,导致视觉和语言特征的独立输入,从而降低了模型的性能。
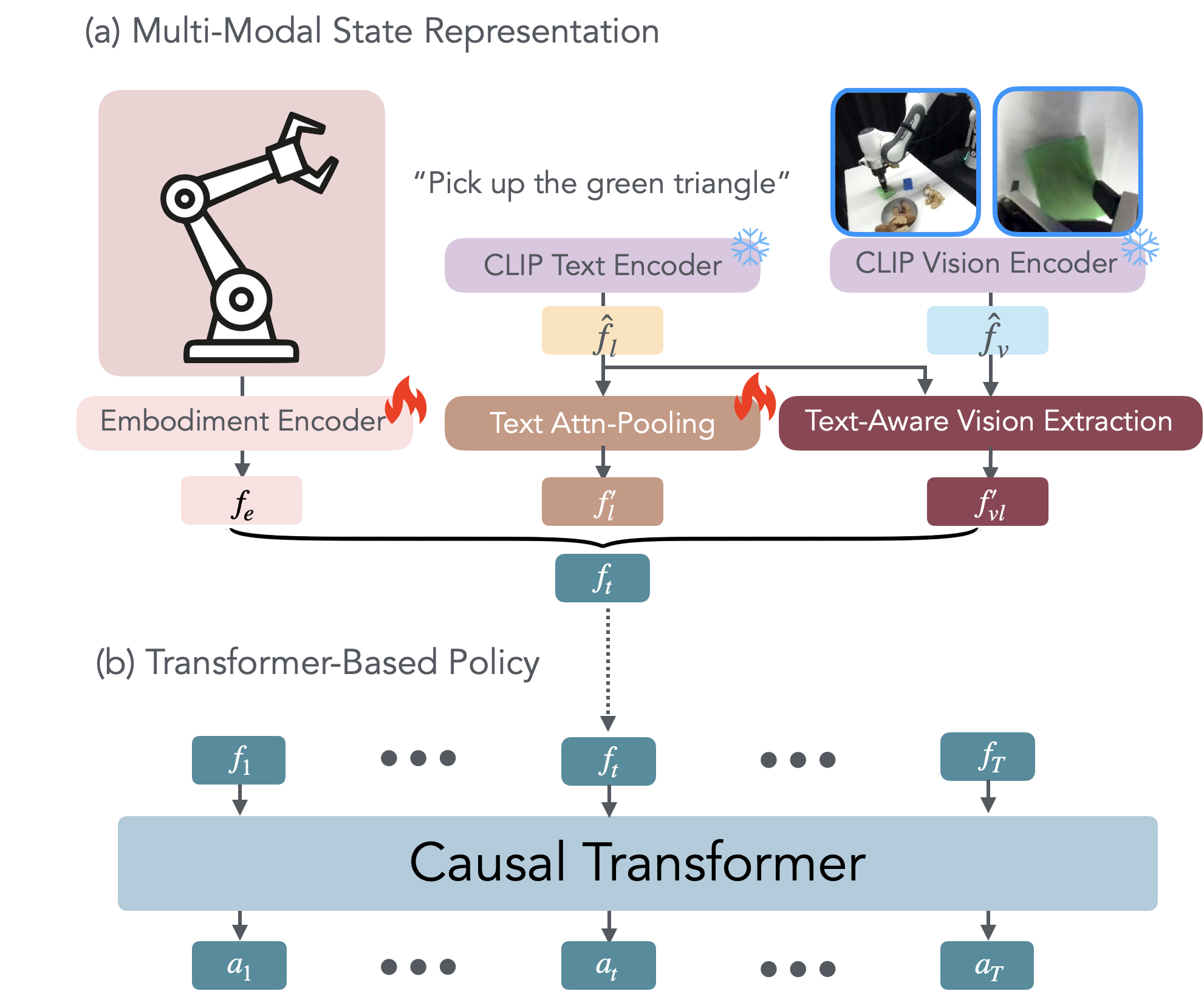
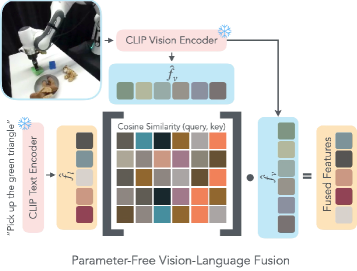
核心思路:OTTER的核心思路是通过显式的文本感知视觉特征提取,选择性地提取与任务相关的视觉特征,并将其传递给策略变换器。这种设计允许保持预训练的视觉语言编码器不变,从而保留其丰富的语义理解能力。
技术框架:OTTER的整体架构包括三个主要模块:视觉特征提取模块、文本感知模块和策略变换器。视觉特征提取模块负责从输入图像中提取视觉特征,文本感知模块则根据语言指令选择性地过滤和提取相关的视觉特征,最后将这些特征输入到策略变换器中进行动作预测。
关键创新:OTTER的主要创新在于其文本感知的视觉特征提取机制,这与现有方法的独立特征输入方式形成了本质区别。通过这种机制,OTTER能够更好地利用预训练模型的语义对齐,提升模型的整体性能。
关键设计:在设计中,OTTER保持了预训练的视觉语言编码器不变,采用了选择性特征提取的策略。此外,损失函数的设计也考虑了语义对齐的保持,确保了模型在训练过程中的稳定性和有效性。整体网络结构经过精心设计,以优化特征提取和动作预测的效率。
🖼️ 关键图片
📊 实验亮点
OTTER在模拟和真实世界实验中表现出色,显著优于现有的视觉语言行动模型。在零样本泛化能力方面,OTTER在新物体和环境中的表现提升幅度超过了20%,展示了其强大的适应性和实用性。
🎯 应用场景
OTTER的研究成果在机器人控制、自动化任务执行和人机交互等领域具有广泛的应用潜力。通过提高机器人对新环境和物体的适应能力,OTTER可以在实际应用中显著提升机器人的智能水平和操作灵活性,推动智能机器人技术的发展。
📄 摘要(原文)
Vision-Language-Action (VLA) models aim to predict robotic actions based on visual observations and language instructions. Existing approaches require fine-tuning pre-trained visionlanguage models (VLMs) as visual and language features are independently fed into downstream policies, degrading the pre-trained semantic alignments. We propose OTTER, a novel VLA architecture that leverages these existing alignments through explicit, text-aware visual feature extraction. Instead of processing all visual features, OTTER selectively extracts and passes only task-relevant visual features that are semantically aligned with the language instruction to the policy transformer. This allows OTTER to keep the pre-trained vision-language encoders frozen. Thereby, OTTER preserves and utilizes the rich semantic understanding learned from large-scale pre-training, enabling strong zero-shot generalization capabilities. In simulation and real-world experiments, OTTER significantly outperforms existing VLA models, demonstrating strong zeroshot generalization to novel objects and environments. Video, code, checkpoints, and dataset: https://ottervla.github.io/.