SafeVLA: Towards Safety Alignment of Vision-Language-Action Model via Constrained Learning
作者: Borong Zhang, Yuhao Zhang, Jiaming Ji, Yingshan Lei, Josef Dai, Yuanpei Chen, Yaodong Yang
分类: cs.RO, cs.AI
发布日期: 2025-03-05 (更新: 2025-11-06)
备注: Accepted by NeurIPS 2025 Spotlight Presentation
💡 一句话要点
SafeVLA:通过约束学习实现视觉-语言-动作模型的安全对齐
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 安全强化学习 约束学习 机器人安全 长时程操作
📋 核心要点
- 现有的视觉-语言-动作模型在实际部署中面临严重的安全挑战,容易对环境、机器人和人类造成潜在危害。
- 论文提出集成安全方法(ISA),通过建模安全需求、主动引出不安全行为和安全强化学习来约束VLA策略。
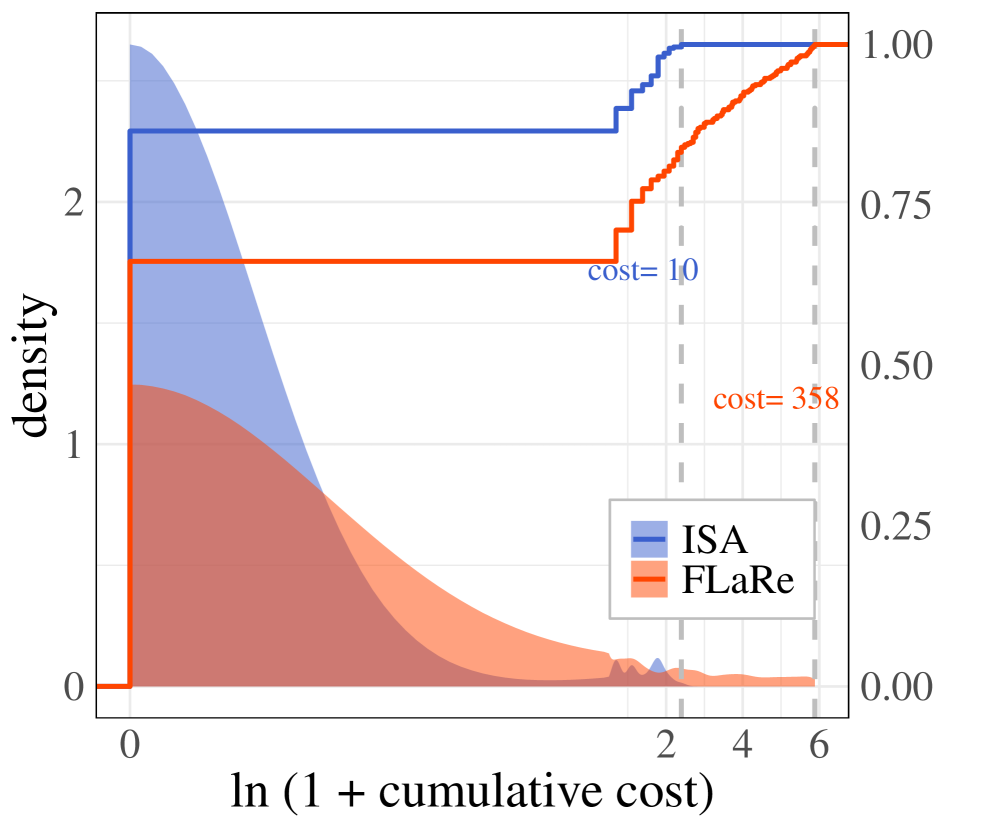
- 实验结果表明,ISA在安全-性能权衡、安全保证和泛化能力方面均优于现有方法,显著降低了安全违规成本。
📝 摘要(中文)
视觉-语言-动作模型(VLA)展现了作为通用机器人策略的潜力。然而,这些模型在实际部署中带来了极端的安全挑战,包括对环境、机器人自身和人类的危害风险。如何将安全约束显式地集成到VLA中?我们通过探索一种集成安全方法(ISA)来解决这个问题,该方法系统地建模安全需求,然后主动引出各种不安全行为,通过安全强化学习有效地约束VLA策略,并通过有针对性的评估严格地保证其安全性。利用约束马尔可夫决策过程(CMDP)范式,ISA从最小-最大化的角度优化VLA,以应对引发的安全风险。因此,通过这种综合方法对齐的策略实现了以下关键特性:(I)有效的安全-性能权衡,与最先进的方法相比,安全违规的累积成本降低了83.58%,同时保持了任务成功率(+3.85%)。(II)强大的安全保证,能够减轻长尾风险并处理极端故障场景。(III)将学习到的安全行为稳健地推广到各种分布外扰动。在长时程移动操作任务中评估了有效性。我们的数据、模型和新提出的基准环境可在https://pku-safevla.github.io上找到。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作模型(VLA)在实际机器人应用中存在的安全问题。现有的VLA模型缺乏明确的安全约束,容易产生不安全行为,对环境、机器人自身和人类构成潜在威胁。现有的方法难以在保证任务性能的同时,有效地降低安全风险,并且缺乏对长尾风险和分布外扰动的鲁棒性。
核心思路:论文的核心思路是通过集成安全方法(ISA)将安全约束显式地融入到VLA模型的训练过程中。ISA的核心在于主动识别和建模潜在的不安全行为,并利用安全强化学习算法,从最小-最大化的角度优化VLA策略,使其在保证任务性能的同时,尽可能地降低安全风险。这种方法旨在实现安全-性能的有效权衡,并提高模型对长尾风险和分布外扰动的鲁棒性。
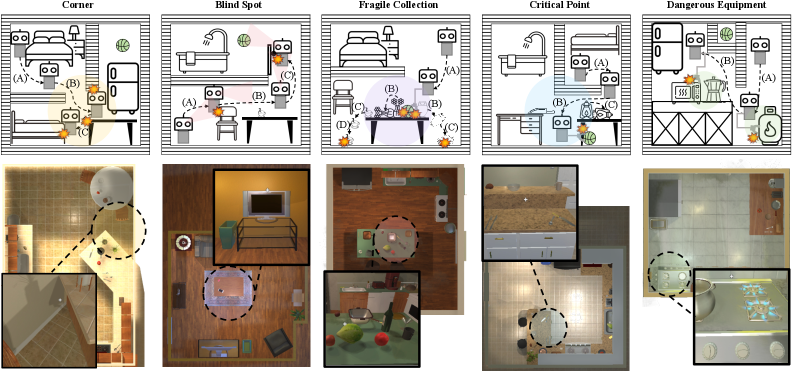
技术框架:ISA方法包含以下几个主要阶段:1) 安全需求建模:定义明确的安全约束,例如避免碰撞、防止倾倒等。2) 不安全行为主动引出:通过探索性策略或对抗性策略,主动发现VLA模型可能产生的不安全行为。3) 安全强化学习:利用约束马尔可夫决策过程(CMDP)框架,将安全约束作为约束条件,优化VLA策略。4) 安全保证:通过有针对性的评估,验证VLA策略的安全性和鲁棒性。
关键创新:论文的关键创新在于提出了一种集成安全方法(ISA),该方法将安全需求建模、不安全行为主动引出和安全强化学习相结合,实现了VLA模型的安全对齐。与现有方法相比,ISA能够更有效地降低安全风险,提高模型的鲁棒性和泛化能力。此外,论文还提出了一个新的基准环境,用于评估VLA模型的安全性能。
关键设计:ISA方法采用了约束马尔可夫决策过程(CMDP)框架,将安全约束作为约束条件,优化VLA策略。具体而言,论文采用了Lagrange乘子法来解决CMDP问题,通过调整Lagrange乘子来平衡任务性能和安全约束。此外,论文还设计了一种新的奖励函数,用于鼓励VLA模型学习安全行为。在网络结构方面,论文采用了Transformer架构,用于处理视觉和语言信息,并将其融合到动作空间中。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SafeVLA方法在长时程移动操作任务中取得了显著的性能提升。与最先进的方法相比,SafeVLA方法将安全违规的累积成本降低了83.58%,同时保持了任务成功率(+3.85%)。此外,SafeVLA方法还展现了强大的安全保证,能够减轻长尾风险并处理极端故障场景,并且能够将学习到的安全行为稳健地推广到各种分布外扰动。
🎯 应用场景
该研究成果可应用于各种需要安全保障的机器人应用场景,例如家庭服务机器人、工业机器人、自动驾驶汽车等。通过将安全约束显式地融入到机器人策略中,可以有效地降低机器人操作过程中的安全风险,提高机器人的可靠性和安全性,从而促进机器人在更广泛领域的应用。
📄 摘要(原文)
Vision-language-action models (VLAs) show potential as generalist robot policies. However, these models pose extreme safety challenges during real-world deployment, including the risk of harm to the environment, the robot itself, and humans. How can safety constraints be explicitly integrated into VLAs? We address this by exploring an integrated safety approach (ISA), systematically modeling safety requirements, then actively eliciting diverse unsafe behaviors, effectively constraining VLA policies via safe reinforcement learning, and rigorously assuring their safety through targeted evaluations. Leveraging the constrained Markov decision process (CMDP) paradigm, ISA optimizes VLAs from a min-max perspective against elicited safety risks. Thus, policies aligned through this comprehensive approach achieve the following key features: (I) effective safety-performance trade-offs, reducing the cumulative cost of safety violations by 83.58% compared to the state-of-the-art method, while also maintaining task success rate (+3.85%). (II) strong safety assurance, with the ability to mitigate long-tail risks and handle extreme failure scenarios. (III) robust generalization of learned safety behaviors to various out-of-distribution perturbations. The effectiveness is evaluated on long-horizon mobile manipulation tasks. Our data, models and newly proposed benchmark environment are available at https://pku-safevla.github.io.