Variable-Friction In-Hand Manipulation for Arbitrary Objects via Diffusion-Based Imitation Learning
作者: Qiyang Yan, Zihan Ding, Xin Zhou, Adam J. Spiers
分类: cs.RO
发布日期: 2025-03-04
备注: Accepted by ICRA 2025 Project website: https://sites.google.com/view/vf-ihm-il/home
💡 一句话要点
提出基于扩散模型的模仿学习方法,实现任意物体变摩擦灵巧手操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 灵巧手操作 变摩擦 模仿学习 扩散模型 机器人学习
📋 核心要点
- 现有变摩擦灵巧手操作方法依赖硬编码策略,仅适用于规则多边形,且需为特定物体定制策略,泛化性差。
- 论文提出基于扩散模型的模仿学习方法,结合模拟和少量真实数据进行协同训练,实现任意物体的灵巧操作。
- 实验结果表明,该方法在任意物体操作上精度优于定制策略,成功率达71.3%,姿态误差为2.676mm和1.902度。
📝 摘要(中文)
针对任意物体的灵巧手内操作(IHM)问题,由于其复杂的接触过程而极具挑战。变摩擦操作是实现灵巧性的替代方案,此前已展示了仅用两个单关节手指进行稳健且通用的2D IHM能力。然而,用于变摩擦手的硬编码操作方法仅限于规则多边形物体和有限的目标姿势,并且需要为每个物体定制策略。本文提出了一种基于端到端学习的操作方法,通过最少的工程投入和数据收集,在真实硬件上实现任意物体的任意目标姿势操作。该方法采用基于扩散策略的模仿学习方法,并结合了来自模拟和少量真实世界数据的协同训练。通过所提出的框架,包括多边形和非多边形在内的任意物体都可以被精确地操作,在A100 GPU上经过2小时的训练和仅1小时的真实世界数据收集后,即可达到任意目标姿势。精度高于以前的定制化特定物体策略,平均成功率达到71.3%,平均姿势误差为2.676毫米和1.902度。
🔬 方法详解
问题定义:现有基于变摩擦的灵巧手操作方法,依赖于针对特定物体的硬编码策略,泛化能力差,难以处理非规则物体和复杂目标姿态。为每个新物体设计策略需要大量人工干预和工程投入。因此,需要一种能够处理任意物体和目标姿态,且无需大量人工干预的通用操作方法。
核心思路:论文的核心思路是利用模仿学习,从少量真实世界数据中学习操作策略,并结合模拟数据进行协同训练,提高策略的泛化能力和鲁棒性。使用扩散模型作为策略表示,能够更好地捕捉复杂的操作动作分布,从而实现更精确的控制。
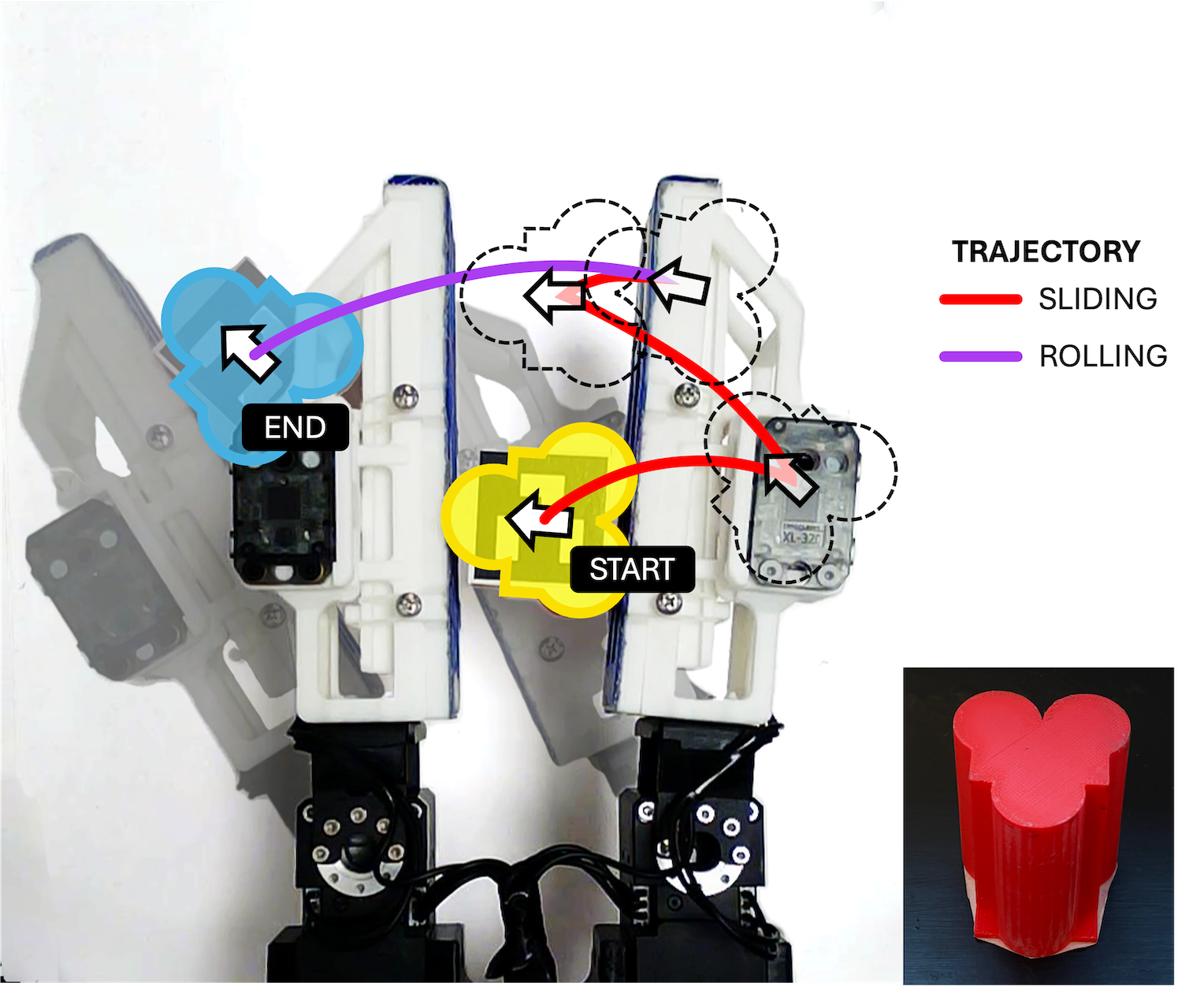
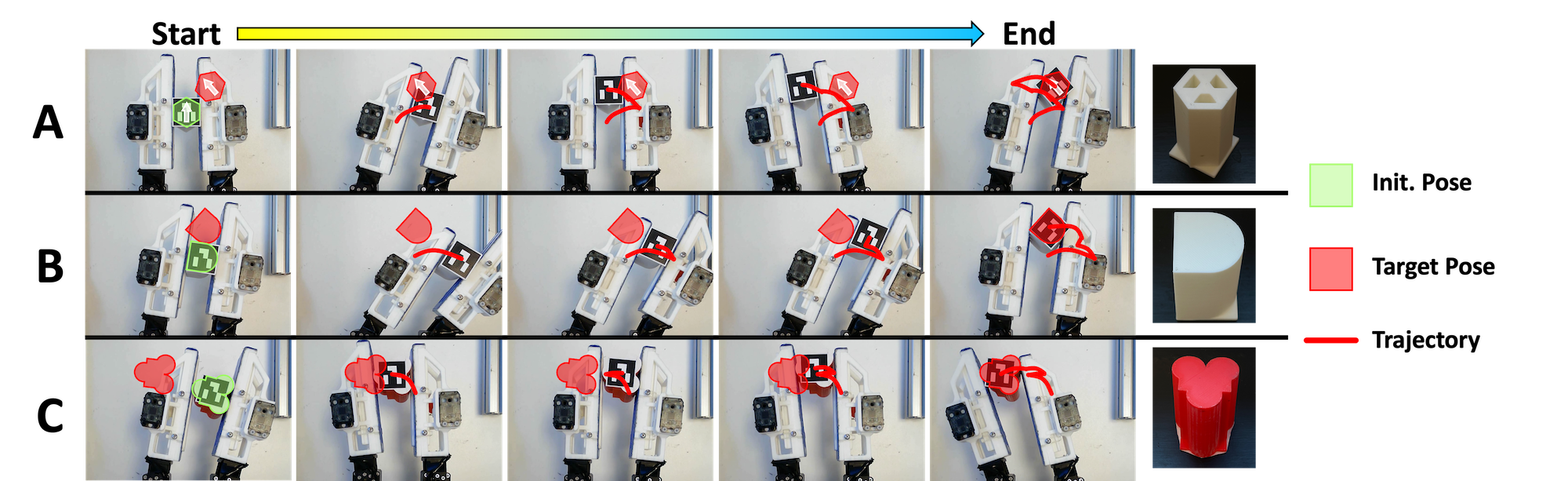
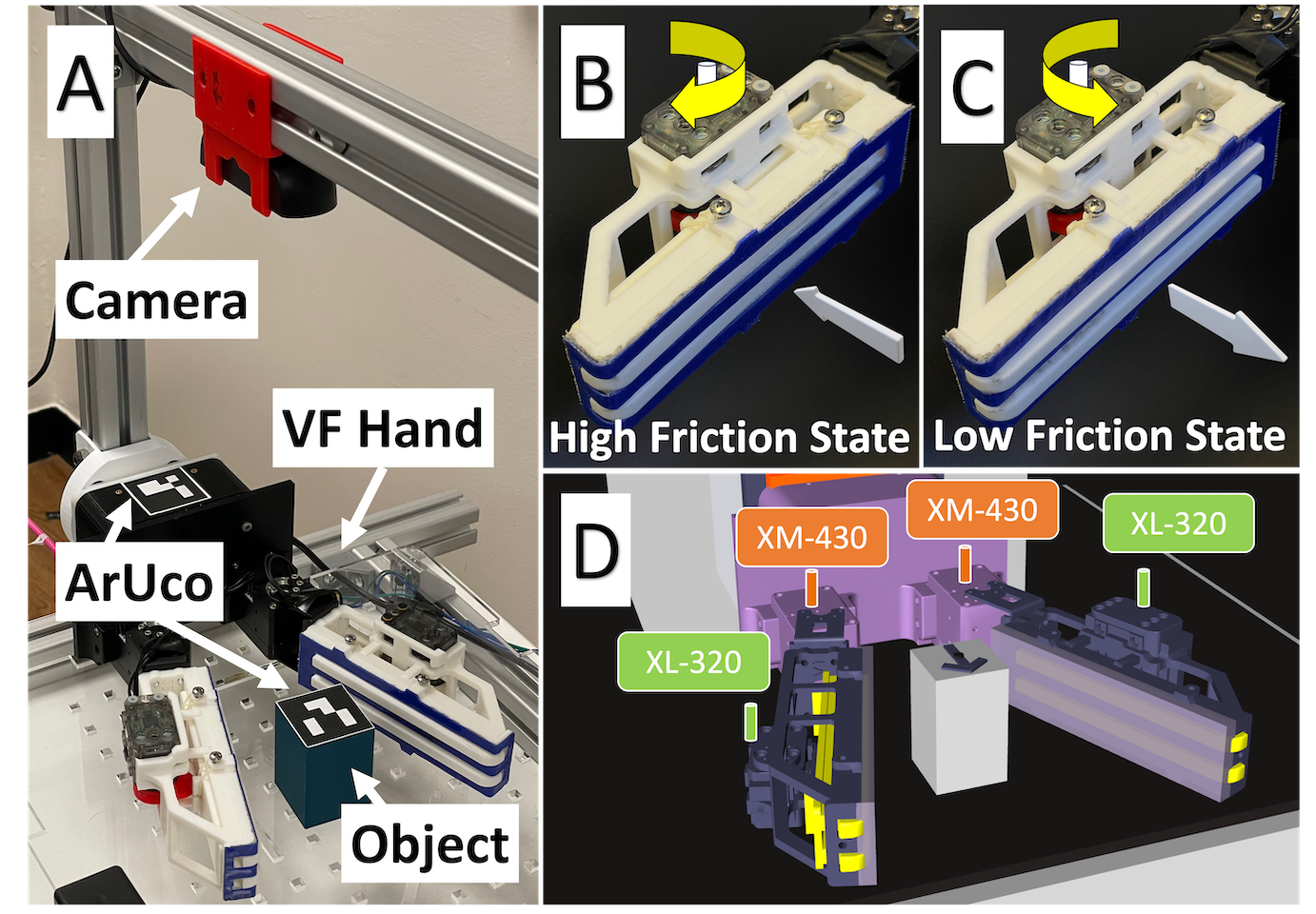
技术框架:整体框架包含以下几个主要模块:1) 数据收集模块:收集少量真实世界操作数据,用于模仿学习。2) 模拟环境:构建模拟环境,生成大量训练数据。3) 扩散策略学习模块:使用扩散模型学习操作策略,结合模拟和真实数据进行协同训练。4) 策略部署模块:将学习到的策略部署到真实机器人上进行操作。
关键创新:最重要的技术创新点在于使用扩散模型作为策略表示,并结合模拟和真实数据进行协同训练。扩散模型能够捕捉复杂的操作动作分布,从而实现更精确的控制。协同训练能够提高策略的泛化能力和鲁棒性,使其能够适应不同的物体和目标姿态。与现有方法的本质区别在于,该方法是一种端到端的学习方法,无需人工设计策略,能够自动学习操作策略。
关键设计:论文中关键的设计包括:1) 扩散模型的网络结构和训练方式。2) 模拟环境的构建和参数设置。3) 模拟数据和真实数据的比例和混合方式。4) 损失函数的设计,包括模仿学习损失和正则化损失等。这些设计共同保证了策略的学习效果和泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在任意物体操作上精度优于定制策略,平均成功率达到71.3%,平均姿势误差为2.676毫米和1.902度。仅需2小时的GPU训练和1小时的真实数据收集,即可实现对任意物体的精确操作。该方法显著降低了对人工干预的需求,提高了操作策略的泛化能力和鲁棒性。
🎯 应用场景
该研究成果可应用于自动化装配、物流分拣、医疗手术等领域。通过学习通用的灵巧操作策略,机器人可以处理各种形状和尺寸的物体,完成复杂的任务,提高生产效率和自动化水平。未来,该技术有望应用于家庭服务机器人,使其能够帮助人们完成各种日常任务。
📄 摘要(原文)
Dexterous in-hand manipulation (IHM) for arbitrary objects is challenging due to the rich and subtle contact process. Variable-friction manipulation is an alternative approach to dexterity, previously demonstrating robust and versatile 2D IHM capabilities with only two single-joint fingers. However, the hard-coded manipulation methods for variable friction hands are restricted to regular polygon objects and limited target poses, as well as requiring the policy to be tailored for each object. This paper proposes an end-to-end learning-based manipulation method to achieve arbitrary object manipulation for any target pose on real hardware, with minimal engineering efforts and data collection. The method features a diffusion policy-based imitation learning method with co-training from simulation and a small amount of real-world data. With the proposed framework, arbitrary objects including polygons and non-polygons can be precisely manipulated to reach arbitrary goal poses within 2 hours of training on an A100 GPU and only 1 hour of real-world data collection. The precision is higher than previous customized object-specific policies, achieving an average success rate of 71.3% with average pose error being 2.676 mm and 1.902 degrees.