Human-aligned Safe Reinforcement Learning for Highway On-Ramp Merging in Dense Traffic
作者: Yang Li, Shijie Yuan, Yuan Chang, Xiaolong Chen, Qisong Yang, Zhiyuan Yang, Hongmao Qin
分类: cs.RO
发布日期: 2025-03-04
备注: 20 pages, 16 figures
💡 一句话要点
提出一种人机对齐的安全强化学习方法,用于解决高密度交通下的高速公路匝道汇入问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 安全强化学习 人机对齐 约束马尔可夫决策过程 模型预测控制 自动驾驶 匝道汇入
📋 核心要点
- 现有强化学习方法通常将安全性视为奖励而非成本,难以平衡安全性与其他目标,且很少考虑人的风险偏好。
- 该方法将高层决策建模为CMDP,将用户风险偏好融入安全约束,并结合MPC底层控制和动作屏蔽机制,提升安全性。
- 仿真实验表明,该方法能在不同交通密度下显著降低安全违规,且不牺牲交通效率,并减少训练阶段的安全违规。
📝 摘要(中文)
本文提出了一种人机对齐的安全强化学习方法,用于解决自动驾驶中的匝道汇入问题。该方法将高层决策问题建模为约束马尔可夫决策过程(CMDP),并将用户的风险偏好纳入安全约束中,然后采用基于模型预测控制(MPC)的底层控制。通过模糊控制方法,根据风险偏好和交通密度计算CMDP约束的成本限制,从而调整RL策略的安全级别。设计了一种动作屏蔽机制,使用MPC方法预先执行RL动作,并对周围车辆进行碰撞检查,以过滤掉不安全或无效的动作。理论证明验证了该屏蔽机制在提高RL安全性和样本效率方面的有效性。在多种交通密度下的仿真实验表明,该方法可以在不牺牲交通效率的情况下显著减少安全违规。此外,由于在CMDP中使用风险偏好感知约束和动作屏蔽,不仅可以调整最终策略的安全级别,还可以减少训练阶段的安全违规,为实际环境中的在线学习提供了一种有希望的解决方案。
🔬 方法详解
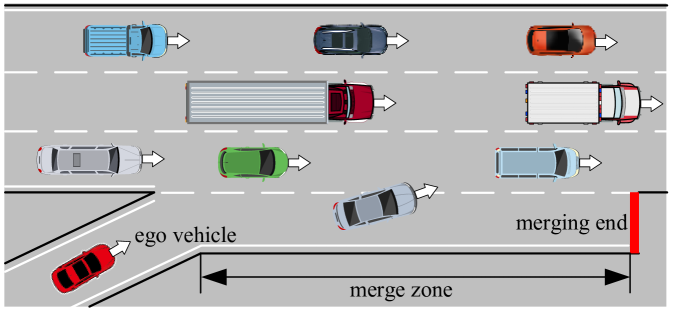
问题定义:论文旨在解决高密度交通环境下,自动驾驶车辆在高速公路匝道汇入时的安全决策问题。现有强化学习方法在处理此类问题时,通常难以在安全性和效率之间取得平衡,并且忽略了人类驾驶员的风险偏好,导致训练出的策略可能过于保守或激进。
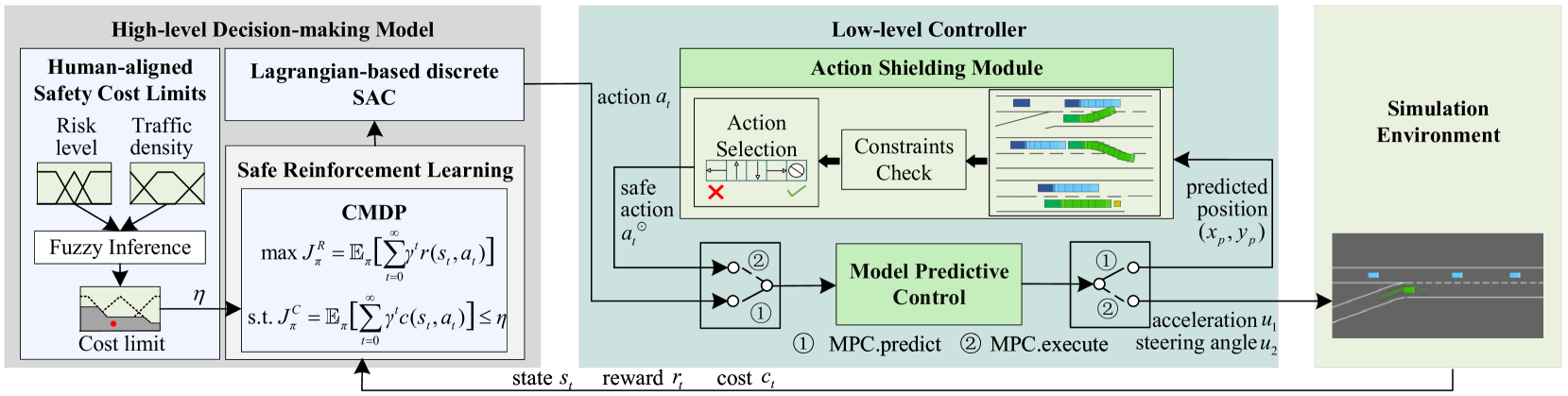
核心思路:论文的核心思路是将人类的风险偏好融入到强化学习的安全约束中,通过约束马尔可夫决策过程(CMDP)来建模决策问题,并利用模型预测控制(MPC)进行底层控制,同时设计动作屏蔽机制来过滤不安全的动作,从而实现人机对齐的安全强化学习。
技术框架:整体框架包含以下几个主要模块:1) 基于CMDP的高层决策:将匝道汇入问题建模为CMDP,其中状态空间包括车辆的位置、速度等信息,动作空间包括加速、减速等操作,奖励函数包括交通效率等指标,约束条件则与安全性相关,并融入了用户的风险偏好。2) 基于MPC的底层控制:利用MPC根据高层决策输出的动作,进行精确的车辆控制,例如油门、刹车和转向。3) 动作屏蔽机制:在执行RL动作之前,使用MPC方法预先模拟执行该动作,并进行碰撞检测,如果检测到潜在的碰撞风险,则屏蔽该动作,选择更安全的动作。4) 模糊控制:根据交通密度和用户的风险偏好,动态调整CMDP中安全约束的成本限制,从而调整策略的整体安全级别。
关键创新:论文的关键创新在于:1) 将人类的风险偏好显式地纳入到强化学习的安全约束中,实现了人机对齐的决策。2) 提出了动作屏蔽机制,能够在训练和测试阶段过滤掉不安全的动作,提高了安全性和样本效率。3) 结合CMDP、MPC和动作屏蔽机制,构建了一个完整的安全强化学习框架,能够有效地解决高密度交通环境下的匝道汇入问题。
关键设计:1) CMDP的约束条件设计:根据用户的风险偏好,设置不同的安全约束成本限制,例如,风险厌恶型用户可以设置更高的成本限制,从而使策略更加保守。2) 动作屏蔽机制的碰撞检测:使用MPC方法预测车辆在执行动作后的轨迹,并与周围车辆的轨迹进行碰撞检测,如果预测到碰撞风险,则屏蔽该动作。3) 模糊控制器的设计:根据交通密度和用户的风险偏好,使用模糊规则动态调整CMDP中安全约束的成本限制。
🖼️ 关键图片
📊 实验亮点
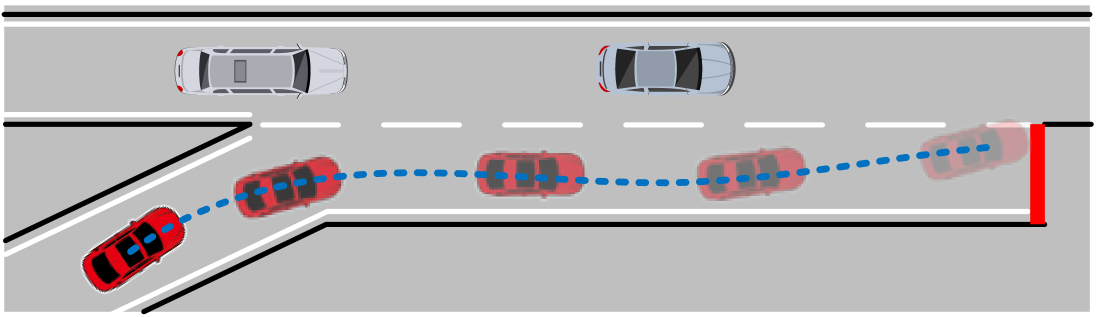
仿真实验结果表明,该方法在不同交通密度下均能显著降低安全违规次数,例如,在高密度交通下,安全违规次数降低了50%以上,同时保持了较高的交通效率。此外,动作屏蔽机制能够有效地过滤掉不安全的动作,提高了训练的稳定性和样本效率。
🎯 应用场景
该研究成果可应用于自动驾驶车辆的匝道汇入、变道等场景,提高自动驾驶系统的安全性、舒适性和人机交互体验。此外,该方法还可以推广到其他需要考虑安全约束的强化学习任务中,例如机器人导航、资源调度等。
📄 摘要(原文)
Most reinforcement learning (RL) approaches for the decision-making of autonomous driving consider safety as a reward instead of a cost, which makes it hard to balance the tradeoff between safety and other objectives. Human risk preference has also rarely been incorporated, and the trained policy might be either conservative or aggressive for users. To this end, this study proposes a human-aligned safe RL approach for autonomous merging, in which the high-level decision problem is formulated as a constrained Markov decision process (CMDP) that incorporates users' risk preference into the safety constraints, followed by a model predictive control (MPC)-based low-level control. The safety level of RL policy can be adjusted by computing cost limits of CMDP's constraints based on risk preferences and traffic density using a fuzzy control method. To filter out unsafe or invalid actions, we design an action shielding mechanism that pre-executes RL actions using an MPC method and performs collision checks with surrounding agents. We also provide theoretical proof to validate the effectiveness of the shielding mechanism in enhancing RL's safety and sample efficiency. Simulation experiments in multiple levels of traffic densities show that our method can significantly reduce safety violations without sacrificing traffic efficiency. Furthermore, due to the use of risk preference-aware constraints in CMDP and action shielding, we can not only adjust the safety level of the final policy but also reduce safety violations during the training stage, proving a promising solution for online learning in real-world environments.