RGBSQGrasp: Inferring Local Superquadric Primitives from Single RGB Image for Graspability-Aware Bin Picking
作者: Yifeng Xu, Fan Zhu, Ye Li, Sebastian Ren, Xiaonan Huang, Yuhao Chen
分类: cs.RO, eess.SY
发布日期: 2025-03-04 (更新: 2025-11-22)
备注: 8 pages, 6 figures, IROS2025 RGMCW Best Workshop Paper
💡 一句话要点
RGBSQGrasp:单目RGB图像超二次曲面抓取,提升无序分拣泛化性
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人抓取 无序分拣 超二次曲面 单目视觉 深度估计
📋 核心要点
- 无序分拣面临遮挡和物理约束,现有方法依赖CAD模型或先验几何信息,泛化性受限,直接回归抓取姿态的方法受深度噪声影响。
- RGBSQGrasp利用超二次曲面形状基元和单目深度估计,从RGB图像推断抓取姿态,无需深度传感器,提升对未知物体的适应性。
- 真实机器人实验表明,RGBSQGrasp抓取成功率达到92%,验证了其在拥挤的无序分拣环境中的有效性。
📝 摘要(中文)
本文提出RGBSQGrasp,一个基于单目RGB图像的抓取框架,用于解决无序分拣任务中的挑战。该框架利用超二次曲面(SQ)形状基元和预训练的深度估计模型,从单目RGB图像中推断抓取姿态,无需深度传感器。RGBSQGrasp集成了跨平台数据集生成流程、基于预训练模型的物体点云估计模块、全局-局部超二次曲面拟合网络以及SQ引导的抓取姿态采样模块。通过整合这些组件,RGBSQGrasp通过几何推理可靠地推断抓取姿态,增强了抓取稳定性和对未知物体的适应性。真实机器人实验表明,抓取成功率达到92%,突显了RGBSQGrasp在拥挤的无序分拣环境中的有效性。
🔬 方法详解
问题定义:无序分拣任务中,由于物体遮挡和堆叠,仅依靠有限的视觉信息进行物体识别和抓取姿态估计非常困难。现有方法要么依赖于已知的CAD模型,限制了对新物体的泛化能力,要么直接从RGB-D数据回归抓取姿态,但深度数据的噪声和缺乏对物体几何结构的理解使得抓取姿态的合成和评估更加困难。
核心思路:利用超二次曲面(Superquadrics, SQ)作为物体的形状基元表示。SQ具有紧凑、可解释的特点,能够捕捉物体的物理和可抓取性信息。通过从单目RGB图像中估计SQ参数,可以实现对物体形状的理解,并在此基础上进行抓取姿态的规划。核心在于克服单目视觉下SQ参数估计的挑战,并设计有效的SQ引导的抓取姿态采样方法。
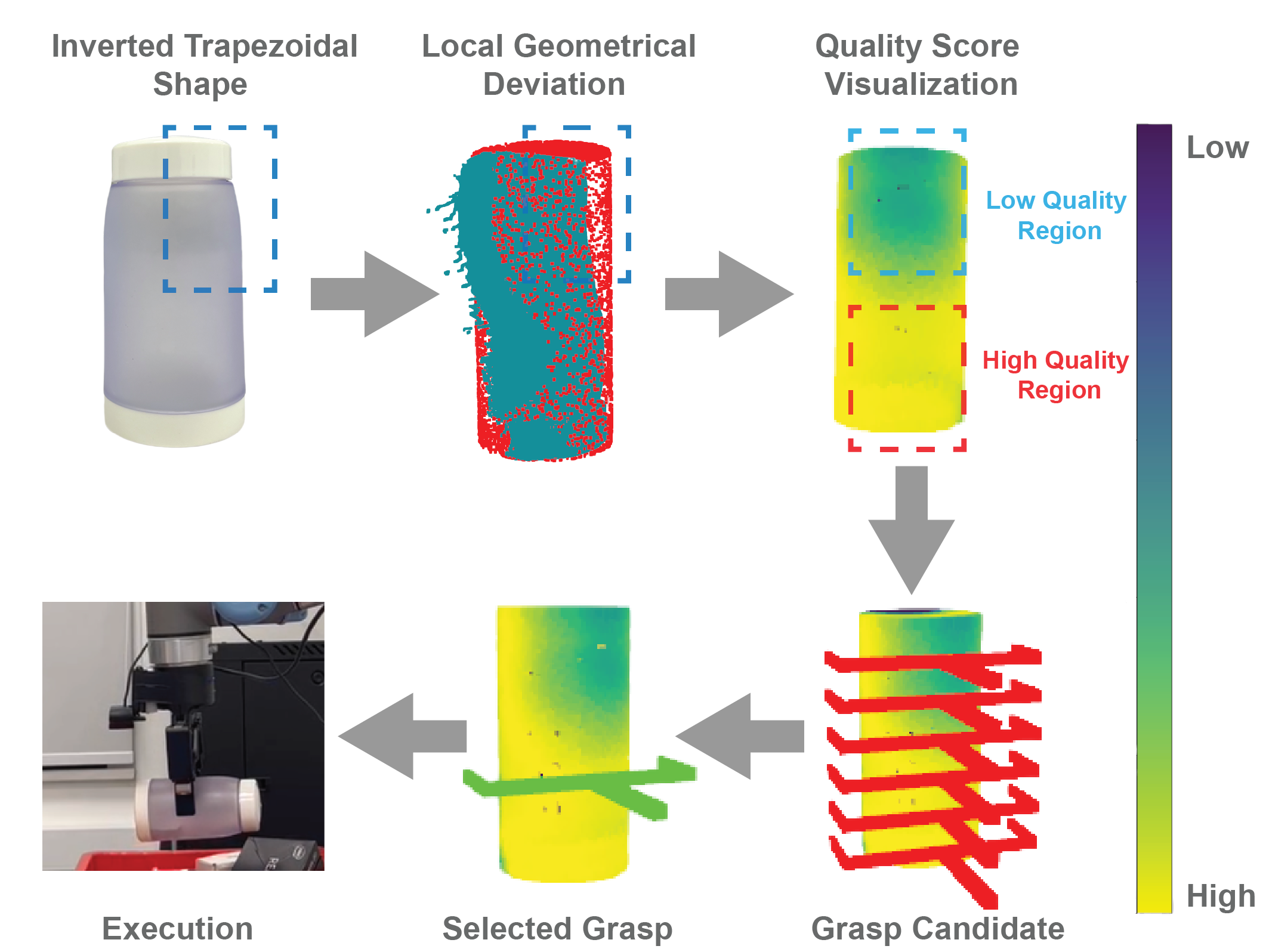
技术框架:RGBSQGrasp框架包含以下几个主要模块:1) 数据集生成模块:构建通用的跨平台数据集生成流程,用于训练深度估计和SQ拟合网络。2) 物体点云估计模块:利用预训练的深度估计模型,从单目RGB图像中估计物体点云。3) 全局-局部超二次曲面拟合网络:设计网络结构,从估计的点云中拟合SQ参数。该网络可能包含全局特征提取和局部精细化两个阶段。4) SQ引导的抓取姿态采样模块:基于估计的SQ参数,采样候选抓取姿态,并进行评估和选择。
关键创新:1) 将超二次曲面引入到单目RGB图像的抓取任务中,利用SQ的几何先验知识提升抓取姿态的鲁棒性。2) 提出全局-局部超二次曲面拟合网络,克服了单目视觉下SQ参数估计的挑战。3) 设计SQ引导的抓取姿态采样模块,利用SQ参数指导抓取姿态的生成和评估。
关键设计:1) 全局-局部超二次曲面拟合网络可能采用编码器-解码器结构,编码器提取全局特征,解码器根据全局特征和局部点云信息回归SQ参数。损失函数可能包含点云重建损失和SQ参数正则化项。2) SQ引导的抓取姿态采样模块可能基于SQ的轴向方向和尺寸信息,生成候选抓取姿态,并利用SQ的内部/外部判断函数评估抓取姿态的有效性。
🖼️ 关键图片
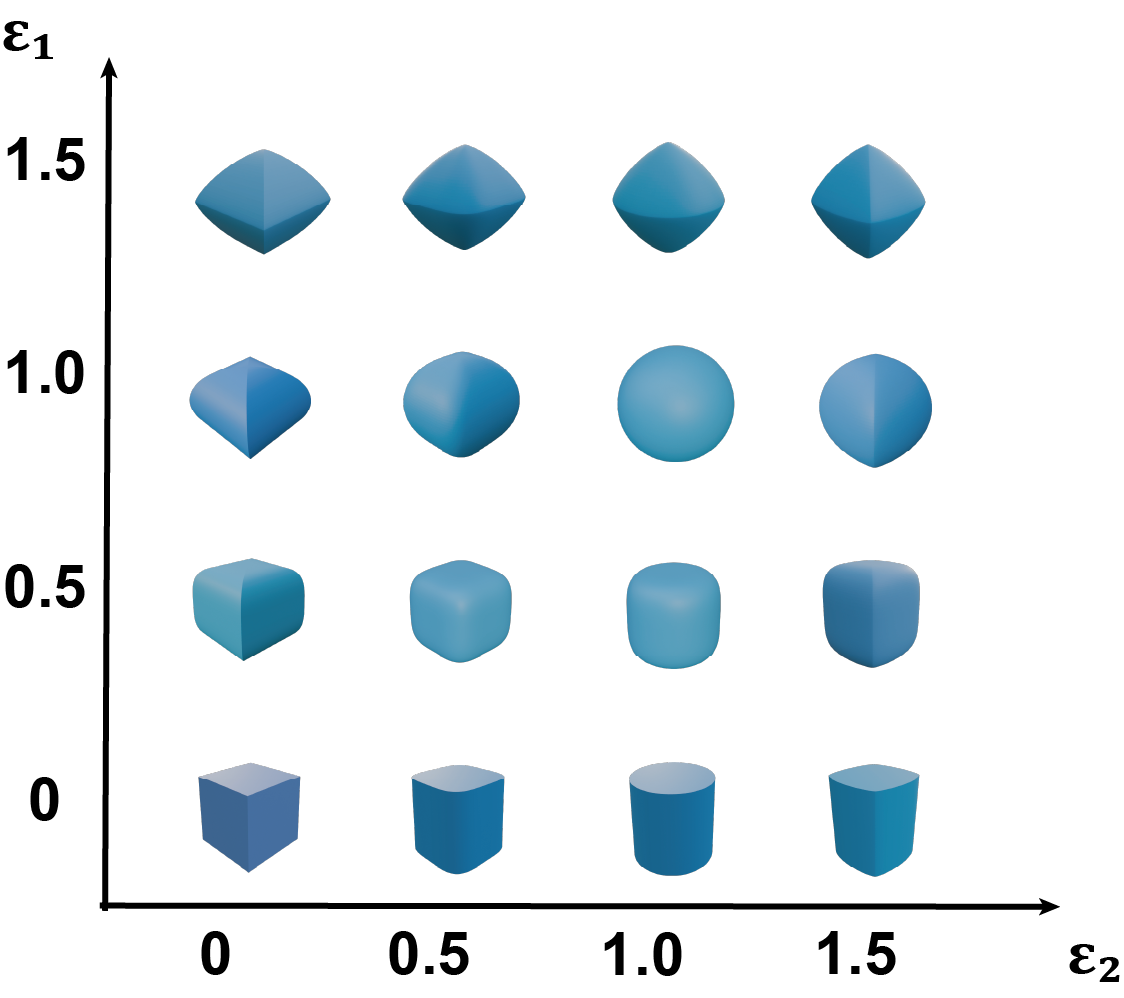

📊 实验亮点
真实机器人实验表明,RGBSQGrasp在拥挤的无序分拣环境中实现了92%的抓取成功率。该结果表明,利用超二次曲面作为形状基元,并结合单目深度估计,可以有效地提升机器人对未知物体的抓取能力。相较于依赖深度传感器的传统方法,RGBSQGrasp具有更高的鲁棒性和适应性。
🎯 应用场景
RGBSQGrasp在机器人无序分拣、自动化装配、智能仓储等领域具有广泛的应用前景。该方法能够提升机器人对未知物体的抓取能力,降低对深度传感器的依赖,从而降低系统成本和提高部署灵活性。未来,该技术可以进一步扩展到更复杂的场景,例如动态环境下的物体抓取和操作。
📄 摘要(原文)
Bin picking is a challenging robotic task due to occlusions and physical constraints that limit visual information for object recognition and grasping. Existing approaches often rely on known CAD models or prior object geometries, restricting generalization to novel or unknown objects. Other methods directly regress grasp poses from RGB-D data without object priors, but the inherent noise in depth sensing and the lack of object understanding make grasp synthesis and evaluation more difficult. Superquadrics (SQ) offer a compact, interpretable shape representation that captures the physical and graspability understanding of objects. However, recovering them from limited viewpoints is challenging, as existing methods rely on multiple perspectives for near-complete point cloud reconstruction, limiting their effectiveness in bin-picking. To address these challenges, we propose \textbf{RGBSQGrasp}, a grasping framework that leverages superquadric shape primitives and foundation metric depth estimation models to infer grasp poses from a monocular RGB camera -- eliminating the need for depth sensors. Our framework integrates a universal, cross-platform dataset generation pipeline, a foundation model-based object point cloud estimation module, a global-local superquadric fitting network, and an SQ-guided grasp pose sampling module. By integrating these components, RGBSQGrasp reliably infers grasp poses through geometric reasoning, enhancing grasp stability and adaptability to unseen objects. Real-world robotic experiments demonstrate a 92% grasp success rate, highlighting the effectiveness of RGBSQGrasp in packed bin-picking environments.