Active Robot Curriculum Learning from Online Human Demonstrations
作者: Muhan Hou, Koen Hindriks, A. E. Eiben, Kim Baraka
分类: cs.RO
发布日期: 2025-03-04
💡 一句话要点
提出基于课程学习的主动机器人示教学习方法,优化在线示教序列。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 主动学习 示教学习 课程学习 人机协作 机器人 强化学习 在线学习
📋 核心要点
- 现有主动示教学习方法易导致任务情境频繁切换,增加人类认知负荷,影响示教质量。
- 提出基于课程学习的主动示教学习方法,引导示教者提供难度渐增的示教序列,优化学习过程。
- 实验表明,该方法显著提升了学习性能和样本效率,并改善了人类示教者的教学表现和适应性。
📝 摘要(中文)
从示教中学习(LfD)允许机器人从人类用户那里学习技能,但其有效性会因次优教学而受到影响,尤其是在未经训练的示教者的情况下。主动LfD旨在通过让机器人主动请求示教来增强学习。然而,这可能导致各种任务情境之间频繁的上下文切换,增加人类的认知负荷,并给示教引入错误。此外,很少有主动LfD的先前研究考察这些主动查询策略可能如何在用户体验之外的方面影响人类教学,这对于开发既有利于机器人学习又有利于人类教学的算法至关重要。为了应对这些挑战,我们提出了一种主动LfD方法,该方法通过课程学习(CL)优化在线人类示教的查询序列,其中引导示教者在难度逐渐增加的情境中提供示教。我们在四个具有稀疏奖励的模拟机器人任务中评估了我们的方法,并进行了一项用户研究(N=26),以调查主动LfD方法对人类教学在教学表现、指导后教学适应性和教学可迁移性方面的影响。我们的结果表明,与另外三个LfD基线相比,我们的方法在收敛策略的最终成功率和样本效率方面显著提高了学习性能。此外,用户研究的结果表明,我们的方法显著减少了人类示教者所需的时间,并减少了失败的示教尝试。与另一个主动LfD基线相比,它还增强了指导后人类在已见和未见场景中的教学,表明我们的方法实现了增强的教学表现、更大的指导后教学适应性和更好的教学可迁移性。
🔬 方法详解
问题定义:论文旨在解决主动示教学习(Active Learning from Demonstration, Active LfD)中,机器人主动向人类请求示教时,由于频繁切换任务情境导致的人类认知负荷过高和示教质量下降的问题。现有方法未能充分考虑人类教学的特点,容易导致次优的示教序列,从而影响机器人的学习效率和最终性能。
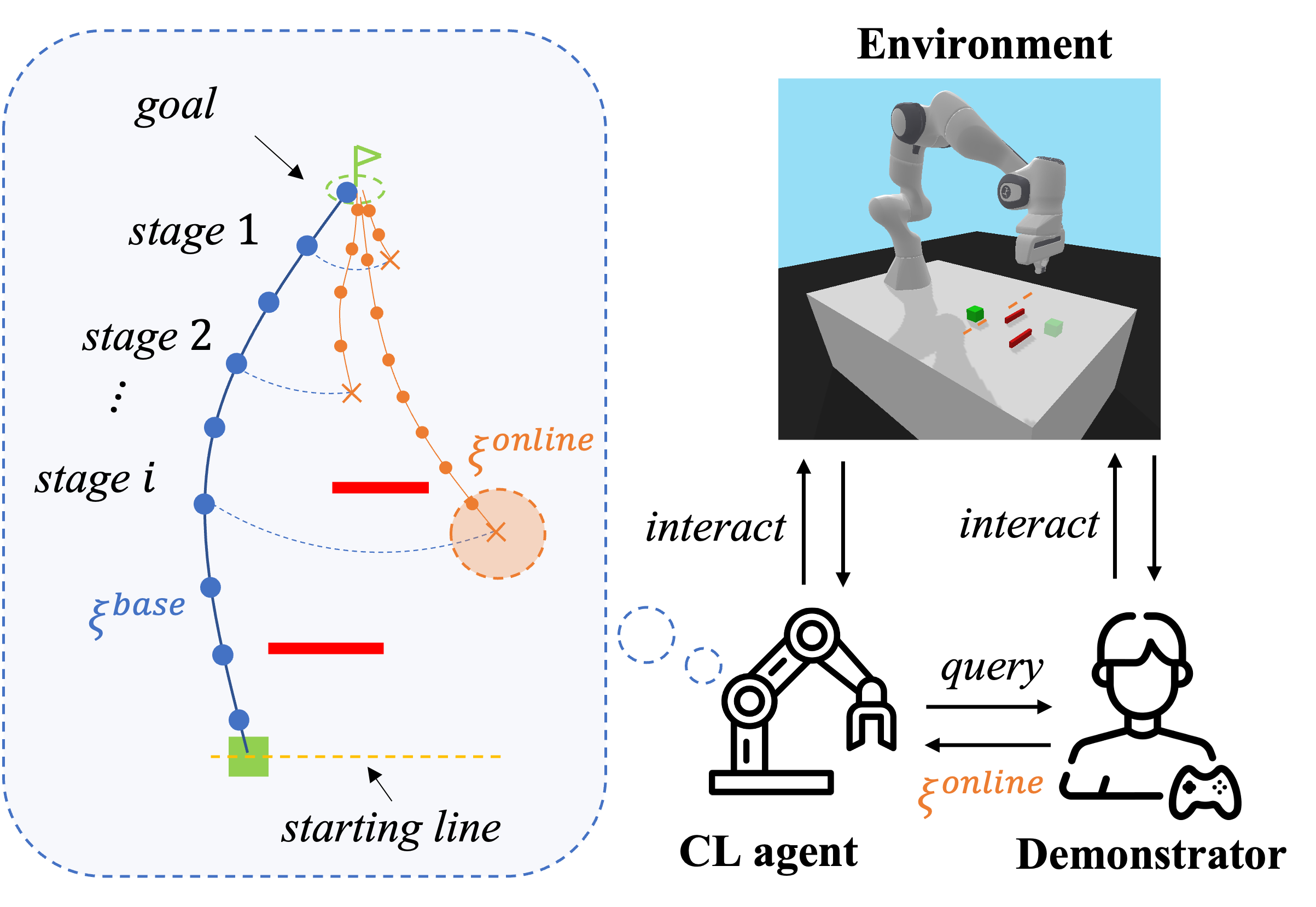
核心思路:论文的核心思路是利用课程学习(Curriculum Learning, CL)的思想,设计一个难度逐渐增加的示教序列,引导人类示教者按照由易到难的顺序提供示教。通过这种方式,可以降低人类的认知负荷,提高示教质量,并最终提升机器人的学习效率和泛化能力。这样设计的目的是为了模拟人类教学的自然过程,即从简单到复杂,逐步引导学生掌握知识。
技术框架:该方法的技术框架主要包含以下几个模块:1) 任务环境模拟器:用于模拟不同的机器人任务场景,并生成任务状态。2) 策略学习模块:使用强化学习算法(如PPO)训练机器人的策略。3) 课程生成模块:基于课程学习算法,生成难度逐渐增加的示教序列。4) 人机交互模块:负责与人类示教者进行交互,请求示教并接收示教数据。5) 示教数据处理模块:对人类提供的示教数据进行处理,用于训练机器人的策略。整体流程是,机器人首先根据课程生成模块生成的示教序列,向人类请求示教;人类提供示教数据后,机器人利用这些数据更新策略;然后,课程生成模块根据策略的性能,调整示教序列,重复上述过程,直到策略收敛。
关键创新:该论文最重要的技术创新点是将课程学习的思想引入到主动示教学习中,通过优化示教序列来提升学习效率和泛化能力。与传统的Active LfD方法相比,该方法更加关注人类教学的特点,能够更好地利用人类的知识和经验。此外,该方法还考虑了人类的认知负荷,通过难度渐增的示教序列来降低人类的认知负担,从而提高示教质量。
关键设计:课程生成模块是该方法中的关键设计。具体来说,课程生成模块需要定义一个难度指标,用于衡量不同任务状态的难度。然后,基于这个难度指标,生成一个难度逐渐增加的示教序列。难度指标可以根据任务的特点进行设计,例如,对于机器人导航任务,可以将目标点与起始点之间的距离作为难度指标;对于机器人操作任务,可以将操作的复杂程度作为难度指标。课程生成算法可以使用多种方法,例如,可以采用基于专家知识的方法,也可以采用基于强化学习的方法。此外,还需要设计合适的奖励函数,用于指导策略学习模块的学习过程。奖励函数的设计需要考虑任务的特点和机器人的目标。
🖼️ 关键图片

📊 实验亮点
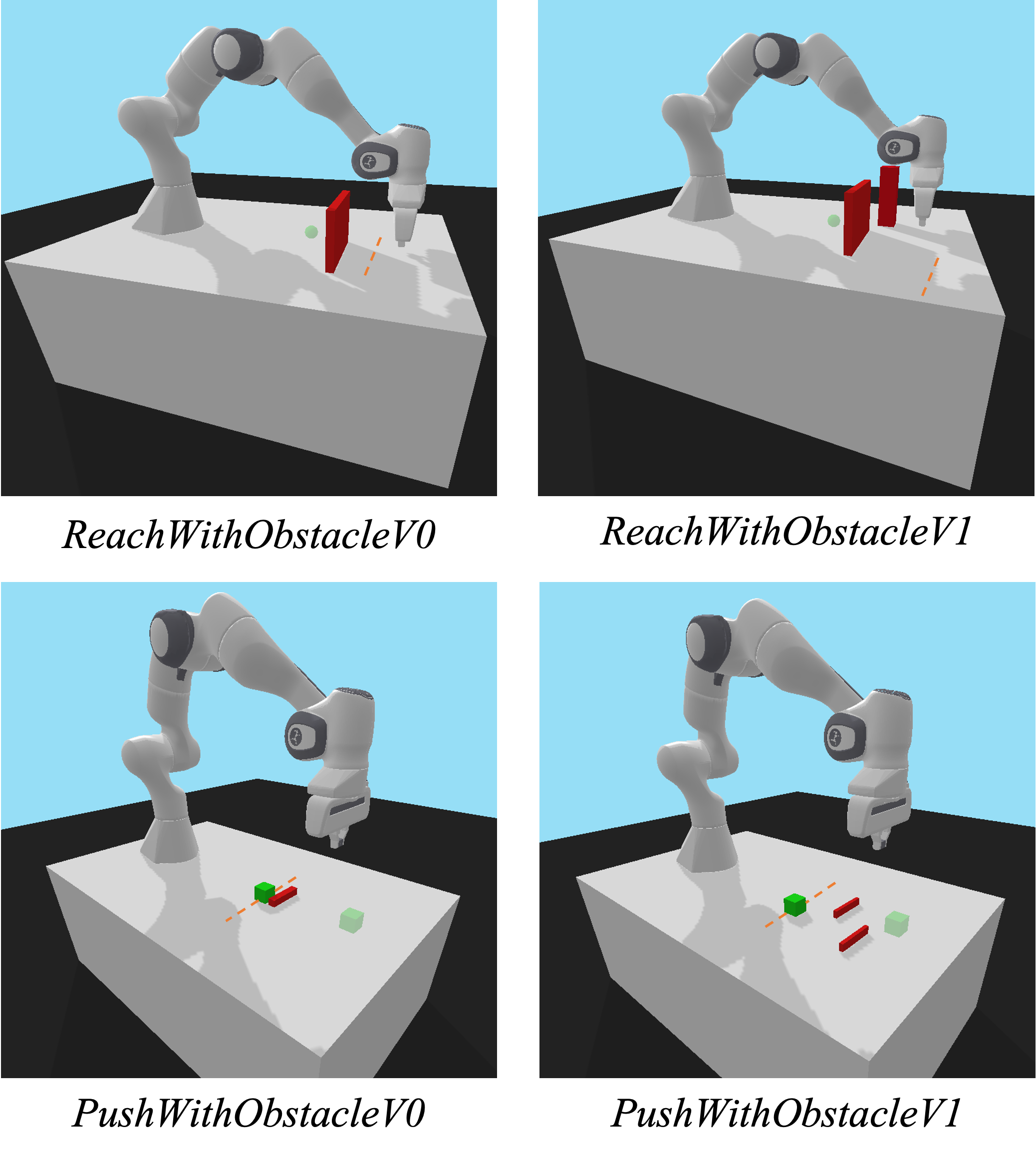
实验结果表明,该方法在四个模拟机器人任务中,显著提高了学习性能和样本效率。与三个LfD基线相比,该方法在收敛策略的最终成功率和样本效率方面均有显著提升。用户研究表明,该方法显著减少了人类示教者所需的时间,并减少了失败的示教尝试。此外,该方法还增强了指导后人类在已见和未见场景中的教学,表明其具有更好的教学适应性和可迁移性。
🎯 应用场景
该研究成果可应用于各种需要人机协作的机器人任务中,例如:家庭服务机器人、工业机器人、医疗机器人等。通过主动学习和课程学习,机器人能够更有效地从人类示教中学习技能,从而更好地完成各种任务。该研究有助于降低机器人部署和使用的门槛,促进人机协作的普及。
📄 摘要(原文)
Learning from Demonstrations (LfD) allows robots to learn skills from human users, but its effectiveness can suffer due to sub-optimal teaching, especially from untrained demonstrators. Active LfD aims to improve this by letting robots actively request demonstrations to enhance learning. However, this may lead to frequent context switches between various task situations, increasing the human cognitive load and introducing errors to demonstrations. Moreover, few prior studies in active LfD have examined how these active query strategies may impact human teaching in aspects beyond user experience, which can be crucial for developing algorithms that benefit both robot learning and human teaching. To tackle these challenges, we propose an active LfD method that optimizes the query sequence of online human demonstrations via Curriculum Learning (CL), where demonstrators are guided to provide demonstrations in situations of gradually increasing difficulty. We evaluate our method across four simulated robotic tasks with sparse rewards and conduct a user study (N=26) to investigate the influence of active LfD methods on human teaching regarding teaching performance, post-guidance teaching adaptivity, and teaching transferability. Our results show that our method significantly improves learning performance compared to three other LfD baselines in terms of the final success rate of the converged policy and sample efficiency. Additionally, results from our user study indicate that our method significantly reduces the time required from human demonstrators and decreases failed demonstration attempts. It also enhances post-guidance human teaching in both seen and unseen scenarios compared to another active LfD baseline, indicating enhanced teaching performance, greater post-guidance teaching adaptivity, and better teaching transferability achieved by our method.