Active Alignments of Lens Systems with Reinforcement Learning
作者: Matthias Burkhardt, Tobias Schmähling, Pascal Stegmann, Michael Layh, Tobias Windisch
分类: cs.RO, cs.LG, eess.SY
发布日期: 2025-03-03 (更新: 2025-10-02)
备注: This work has been submitted to the IEEE for possible publication
💡 一句话要点
提出基于强化学习的光学镜头主动对准方法,提升相机制造效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 光学对准 相机制造 机器人控制 物理渲染
📋 核心要点
- 传统镜头对准方法易受制造公差影响,测量这些公差成本高昂且不切实际,导致对准精度下降。
- 提出一种基于强化学习的镜头对准方法,直接在像素空间学习,无需人工设计对准策略,适应制造偏差。
- 实验表明,该方法在对准速度、精度和鲁棒性方面优于现有方法,并开源了逼真的光学系统模拟环境relign。
📝 摘要(中文)
在相机制造中,镜头系统相对于成像器的对准至关重要。虽然在理想条件下可以通过数学计算实现最佳对准,但制造公差导致的实际偏差常常使这种方法失效。测量这些公差的成本可能很高甚至不可行,忽略它们可能导致次优的对准结果。我们提出了一种强化学习(RL)方法,该方法仅在传感器输出的像素空间中学习,无需设计专家对准方案。我们进行了一项广泛的基准研究,表明我们的方法在速度、精度和鲁棒性方面优于其他方法。此外,我们还引入了relign,这是一个逼真、可自由探索的开源模拟环境,它利用基于物理的渲染来模拟具有非确定性制造公差和机器人对准运动噪声的光学系统。它提供了与流行的机器学习框架的接口,从而实现无缝的实验和开发。我们的工作强调了强化学习在制造环境中提高光学对准效率同时最大限度地减少人工干预的潜力。
🔬 方法详解
问题定义:论文旨在解决相机制造中镜头系统相对于成像器的高精度自动对准问题。现有方法依赖于精确的数学模型,但实际生产中制造公差导致模型失效,人工测量公差成本高昂,忽略公差则导致对准精度不足。因此,如何在存在制造偏差的情况下实现快速、精确、鲁棒的镜头对准是一个关键挑战。
核心思路:论文的核心思路是利用强化学习直接从传感器输出的像素空间学习对准策略。通过将镜头对准过程建模为一个马尔可夫决策过程(MDP),智能体(机器人)通过与环境(光学系统)交互,不断调整镜头位置,并根据图像质量获得奖励,最终学习到最优的对准策略。这种方法无需显式地建模制造公差,而是通过试错学习来适应这些偏差。
技术框架:整体框架包含三个主要部分:1) 光学系统模拟环境(relign),用于生成训练数据;2) 强化学习智能体,负责学习对准策略;3) 奖励函数,用于评估对准质量。智能体通过执行动作(调整镜头位置)与环境交互,环境返回新的图像和奖励。智能体根据奖励更新其策略,不断优化对准过程。relign模拟环境基于物理渲染,可以模拟制造公差和机器人运动噪声,保证了训练数据的真实性。
关键创新:最重要的创新点在于直接在像素空间进行强化学习,避免了对制造公差的显式建模。传统方法需要精确的几何模型和参数估计,而该方法通过端到端的学习,直接从图像中提取对准信息,具有更强的适应性和鲁棒性。此外,开源的relign模拟环境为光学系统对准算法的研究提供了一个统一的平台。
关键设计:论文使用了深度Q网络(DQN)作为强化学习算法。奖励函数的设计至关重要,论文采用了一种基于图像清晰度的奖励函数,鼓励智能体将镜头移动到最佳对准位置。此外,为了提高训练效率,论文还使用了经验回放和目标网络等技术。具体参数设置未知。
🖼️ 关键图片

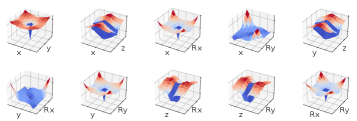
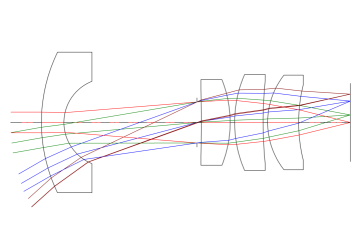
📊 实验亮点
实验结果表明,该方法在对准速度、精度和鲁棒性方面均优于传统方法。在模拟环境中,该方法能够快速找到最佳对准位置,并且对制造公差和机器人运动噪声具有很强的鲁棒性。具体的性能数据未知,但论文强调了其超越其他方法的优越性。
🎯 应用场景
该研究成果可应用于相机、手机、VR/AR设备等光学成像系统的自动化生产线,提高生产效率和产品质量,降低人工干预成本。此外,该方法也可推广到其他需要高精度对准的制造领域,如激光器、显微镜等。
📄 摘要(原文)
Aligning a lens system relative to an imager is a critical challenge in camera manufacturing. While optimal alignment can be mathematically computed under ideal conditions, real-world deviations caused by manufacturing tolerances often render this approach impractical. Measuring these tolerances can be costly or even infeasible, and neglecting them may result in suboptimal alignments. We propose a reinforcement learning (RL) approach that learns exclusively in the pixel space of the sensor output, eliminating the need to develop expert-designed alignment concepts. We conduct an extensive benchmark study and show that our approach surpasses other methods in speed, precision, and robustness. We further introduce relign, a realistic, freely explorable, open-source simulation utilizing physically based rendering that models optical systems with non-deterministic manufacturing tolerances and noise in robotic alignment movement. It provides an interface to popular machine learning frameworks, enabling seamless experimentation and development. Our work highlights the potential of RL in a manufacturing environment to enhance efficiency of optical alignments while minimizing the need for manual intervention.