Diffusion Stabilizer Policy for Automated Surgical Robot Manipulations
作者: Chonlam Ho, Jianshu Hu, Hesheng Wang, Qi Dou, Yutong Ban
分类: cs.RO
发布日期: 2025-03-03
备注: Under-review
💡 一句话要点
提出基于扩散稳定器策略(DSP)的自动手术机器人操作方法,提升轨迹扰动下的鲁棒性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 手术机器人 策略学习 扩散模型 轨迹优化 鲁棒性 自动化手术 深度学习 机器人操作
📋 核心要点
- 手术机器人自动化面临挑战,现有方法难以处理不完美或失败的轨迹数据。
- 提出扩散稳定器策略(DSP),利用扩散模型学习策略,并使用预测误差过滤扰动数据。
- 实验表明,DSP在无扰动和扰动环境下均表现出色,提升了手术机器人的鲁棒性。
📝 摘要(中文)
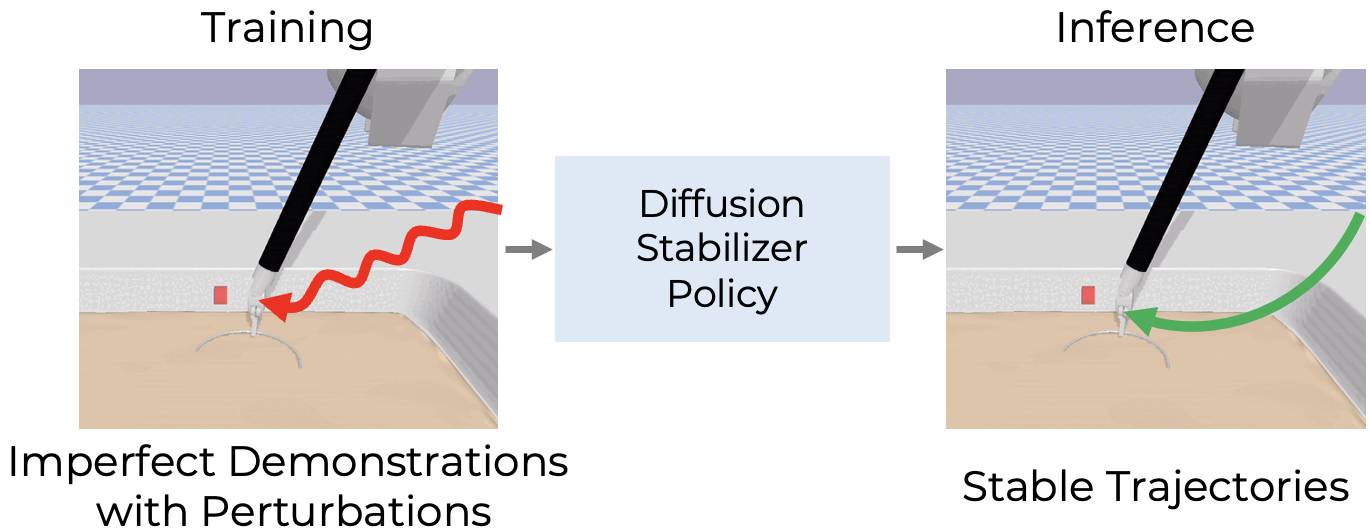
智能手术机器人有望通过实现更精确和自动化的手术程序来彻底改变临床实践。然而,与解决家庭操作任务的最新进展相比,手术机器人自动化仍有待探索。这些成功主要归功于(1)Transformer和扩散模型等先进模型,以及(2)大规模数据利用。为了将这些成功扩展到手术机器人领域,我们提出了一种基于扩散的策略学习框架,称为扩散稳定器策略(DSP),该框架能够使用不完美甚至失败的轨迹进行训练。我们的方法包括两个阶段:首先,我们仅使用干净数据训练扩散稳定器策略。然后,使用干净数据和扰动数据的混合数据持续更新策略,并基于动作的预测误差进行过滤。在各种手术环境中进行的综合实验表明,我们的方法在无扰动设置下表现出卓越的性能,并且在处理扰动演示时具有鲁棒性。
🔬 方法详解
问题定义:论文旨在解决手术机器人自动化中,策略学习对不完美或失败轨迹的敏感性问题。现有方法在处理包含噪声或错误的轨迹数据时,性能会显著下降,限制了其在实际手术环境中的应用。
核心思路:论文的核心思路是利用扩散模型学习一个稳定的策略,该策略能够容忍一定程度的轨迹扰动。通过引入一个稳定器,该稳定器可以基于预测误差对数据进行过滤,从而减少不完美数据对策略学习的影响。
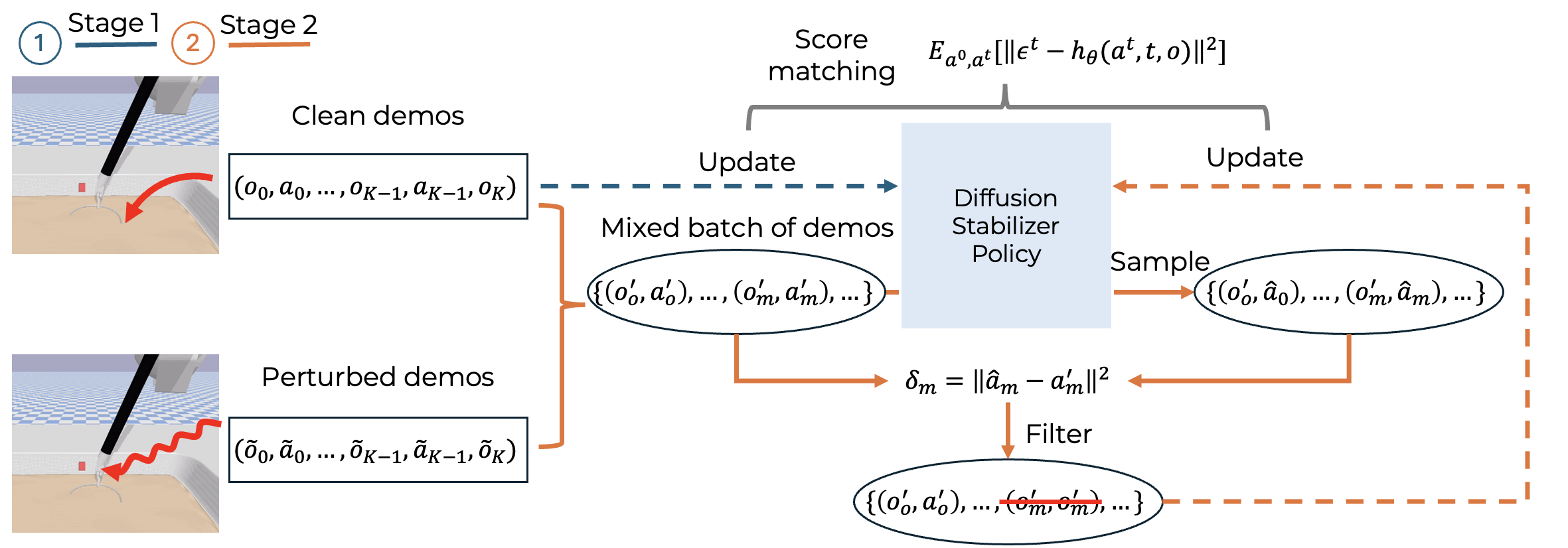
技术框架:DSP框架包含两个主要阶段:(1) 扩散稳定器策略训练阶段:仅使用干净的轨迹数据训练一个初始的扩散策略。该策略学习从状态到动作的概率分布。(2) 策略持续更新阶段:使用干净数据和扰动数据的混合数据持续更新策略。在更新过程中,使用预测误差作为过滤标准,去除预测误差较大的扰动数据,保留高质量的数据用于策略优化。
关键创新:关键创新在于将扩散模型与稳定器相结合,实现对不完美轨迹数据的鲁棒学习。稳定器通过预测误差来评估数据的质量,并过滤掉噪声较大的数据,从而保证策略学习的稳定性。这与传统的策略学习方法不同,传统方法通常假设训练数据是完美的。
关键设计:论文的关键设计包括:(1) 扩散模型的选择:具体使用的扩散模型结构未知,但需要能够生成连续的动作空间。(2) 预测误差的计算:预测误差是稳定器的核心,需要选择合适的误差度量方式,例如均方误差或交叉熵。(3) 数据混合比例:需要仔细调整干净数据和扰动数据的混合比例,以平衡策略的探索和利用。(4) 误差阈值的设定:需要设定一个合适的误差阈值,用于过滤掉预测误差较大的数据。
🖼️ 关键图片
📊 实验亮点
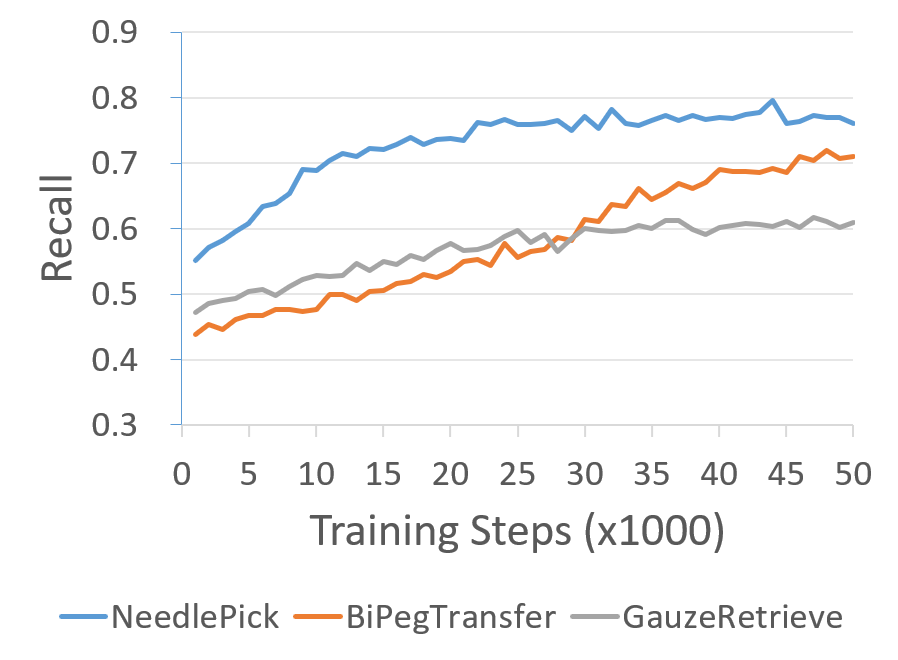
论文在多个手术环境中进行了实验,验证了DSP的有效性。实验结果表明,在无扰动环境下,DSP的性能与现有方法相当。在存在轨迹扰动的情况下,DSP的性能显著优于现有方法,表现出更强的鲁棒性。具体的性能提升数据未知,但论文强调了DSP在处理扰动数据方面的优势。
🎯 应用场景
该研究成果可应用于多种手术机器人任务,例如微创手术、远程手术等。通过提高手术机器人在复杂环境下的鲁棒性,可以减少人为干预,提高手术精度和效率,降低手术风险,最终改善患者的治疗效果。未来,该技术有望推广到其他需要高精度和鲁棒性的机器人操作领域。
📄 摘要(原文)
Intelligent surgical robots have the potential to revolutionize clinical practice by enabling more precise and automated surgical procedures. However, the automation of such robot for surgical tasks remains under-explored compared to recent advancements in solving household manipulation tasks. These successes have been largely driven by (1) advanced models, such as transformers and diffusion models, and (2) large-scale data utilization. Aiming to extend these successes to the domain of surgical robotics, we propose a diffusion-based policy learning framework, called Diffusion Stabilizer Policy (DSP), which enables training with imperfect or even failed trajectories. Our approach consists of two stages: first, we train the diffusion stabilizer policy using only clean data. Then, the policy is continuously updated using a mixture of clean and perturbed data, with filtering based on the prediction error on actions. Comprehensive experiments conducted in various surgical environments demonstrate the superior performance of our method in perturbation-free settings and its robustness when handling perturbed demonstrations.