A Taxonomy for Evaluating Generalist Robot Manipulation Policies
作者: Jensen Gao, Suneel Belkhale, Sudeep Dasari, Ashwin Balakrishna, Dhruv Shah, Dorsa Sadigh
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-03-03 (更新: 2026-01-15)
备注: IEEE Robotics and Automation Letters (RA-L)
💡 一句话要点
提出STAR-Gen:通用机器人操作策略评估分类法,并提供可复现的基准测试指南
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 泛化能力 分类法 基准测试 视觉泛化 语义泛化 行为泛化 机器学习
📋 核心要点
- 现有机器人操作策略的泛化能力评估缺乏统一标准,不同研究的设定难以复现,阻碍了领域进展。
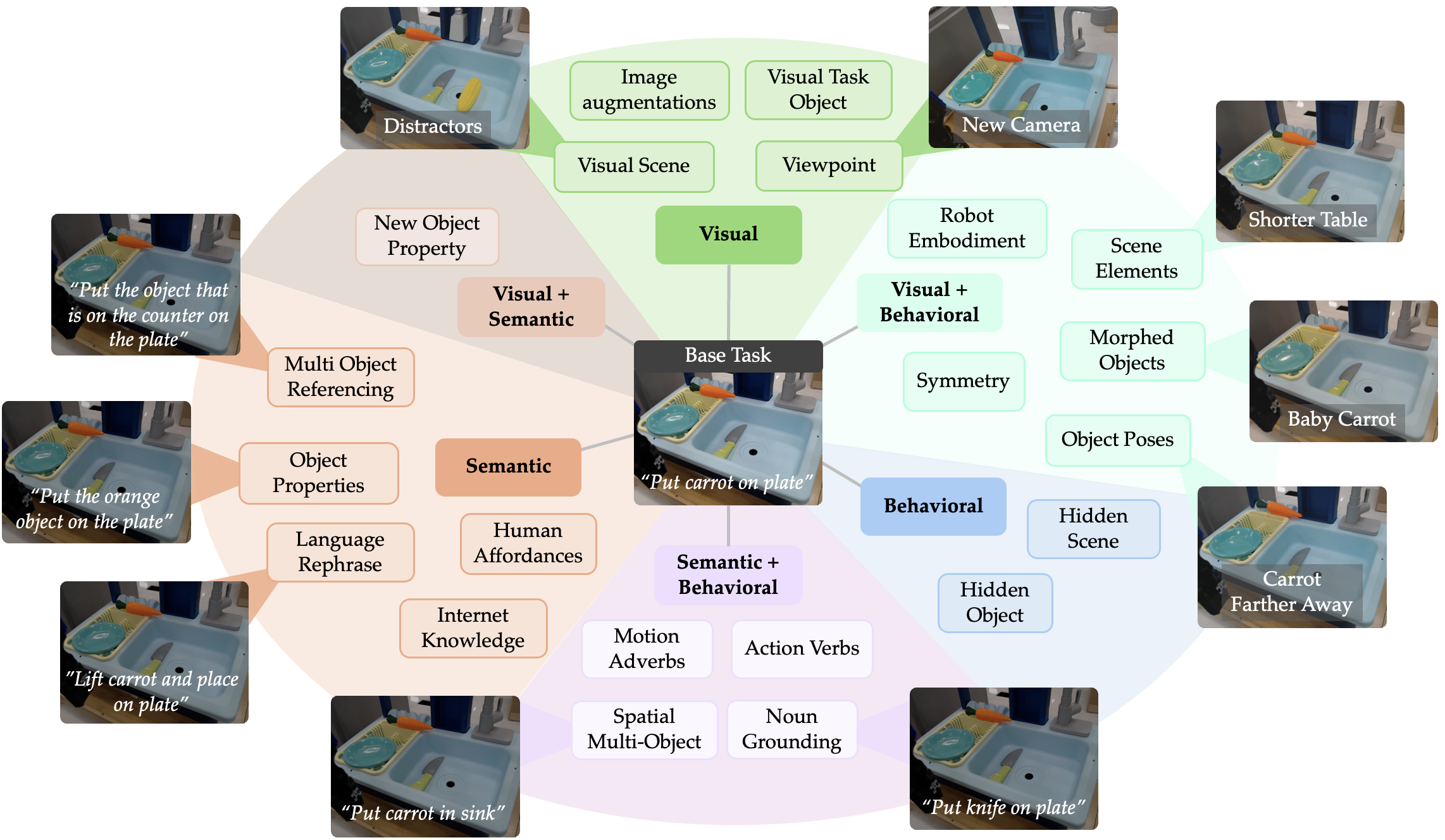
- 论文提出STAR-Gen分类法,围绕视觉、语义和行为三个维度,细致地定义了机器人操作中的泛化形式。
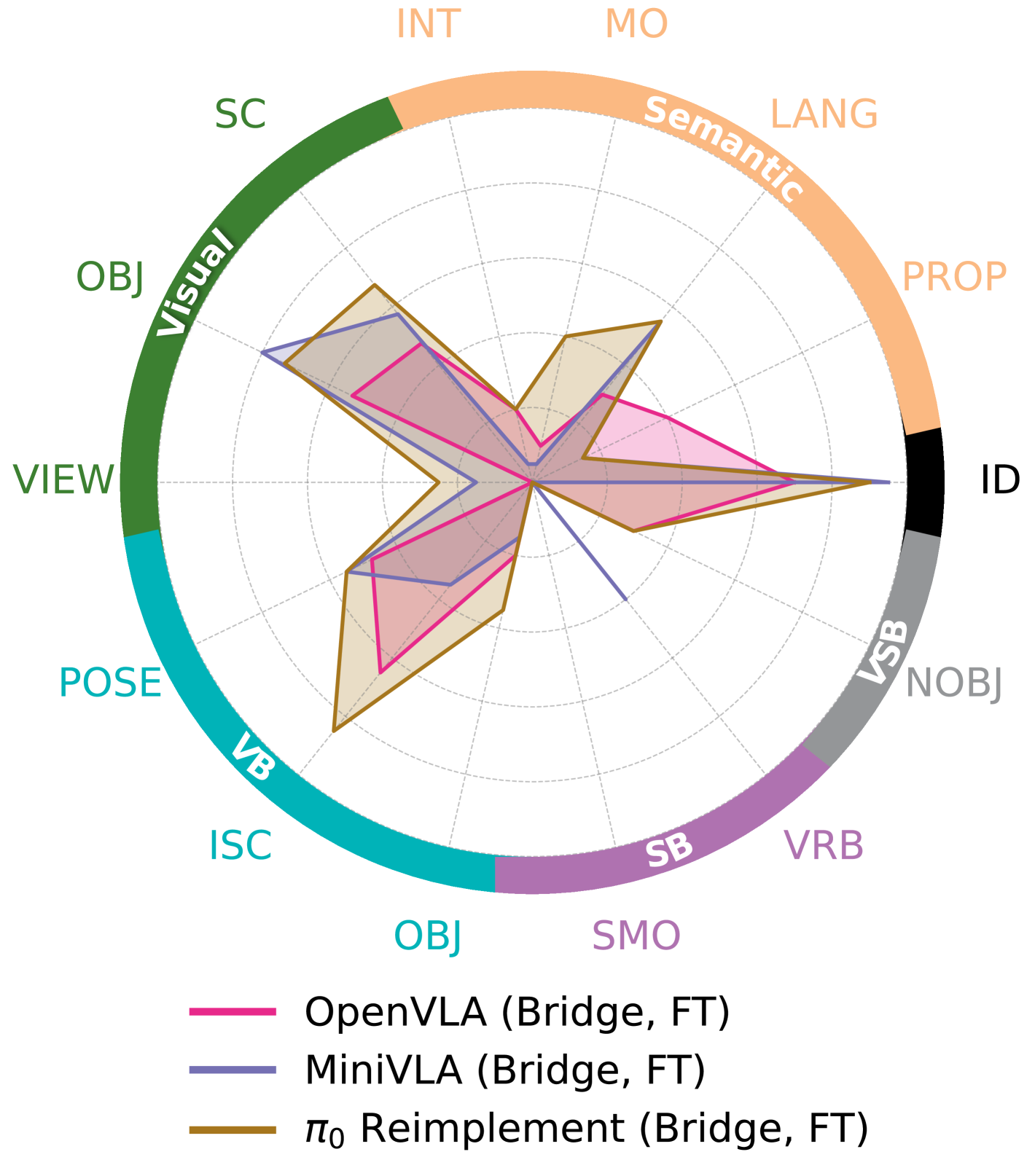
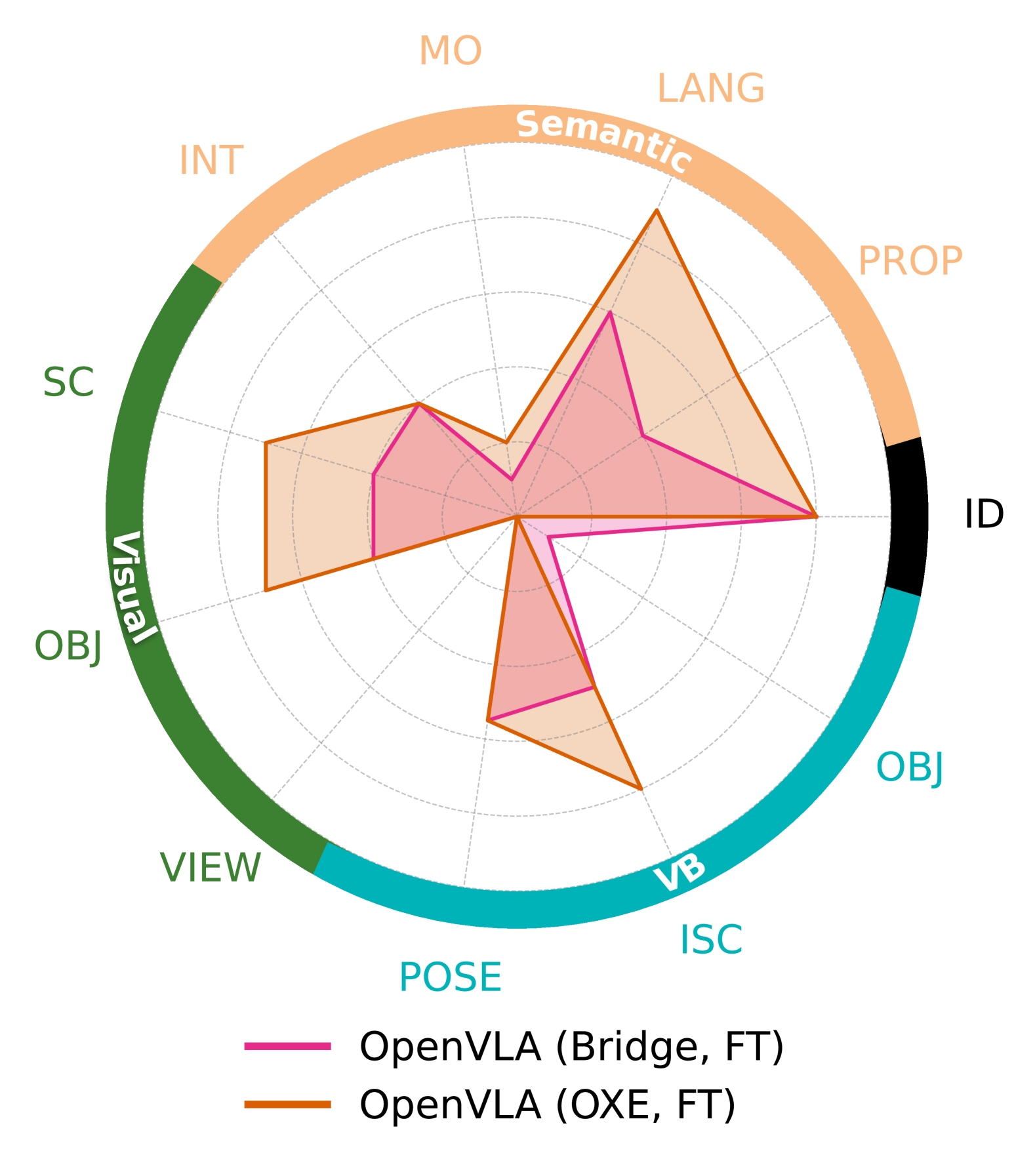
- 通过开源模型和ALOHA 2平台上的案例研究,验证了STAR-Gen的有效性,并揭示了现有模型在语义泛化方面的不足。
📝 摘要(中文)
机器人操作的机器学习有望实现对新任务和环境的泛化。然而,如何衡量这些策略在泛化方面的进展?评估和量化泛化是现代机器人领域的难题,每个工作都提出并衡量不同类型的泛化,且通常难以复现。本文旨在(1)全面而细致地概述我们认为对机器人操作重要的泛化形式,以及(2)为衡量这些泛化概念提供可复现的指南。我们首先提出了STAR-Gen,一个围绕视觉、语义和行为泛化构建的机器人操作泛化分类法。接下来,我们通过两个真实世界的基准测试案例研究来实例化STAR-Gen:一个基于开源模型和Bridge V2数据集,另一个基于双臂ALOHA 2平台,涵盖更灵巧和更长时程的任务。我们的案例研究揭示了许多有趣的见解:例如,我们观察到开源的视觉-语言-动作模型在语义泛化方面常常表现不佳,尽管它们在互联网规模的语言数据集上进行了预训练。我们在我们的网站stargen-taxonomy.github.io上提供了视频和其他补充材料。
🔬 方法详解
问题定义:现有机器人操作策略的泛化能力评估缺乏统一的标准和可复现的基准。不同的研究通常关注不同类型的泛化,并在不同的环境中进行评估,这使得比较和衡量不同策略的进展变得困难。此外,许多评估设置难以复现,阻碍了研究的进一步发展。因此,亟需一个全面、细致且可复现的泛化评估框架。
核心思路:论文的核心思路是构建一个名为STAR-Gen的泛化分类法,该分类法围绕视觉、语义和行为三个关键维度来组织泛化类型。通过细致地定义每个维度下的泛化形式,并提供可复现的基准测试指南,论文旨在为机器人操作策略的泛化能力评估提供一个统一的框架。这种结构化的方法有助于研究人员更好地理解和衡量不同策略的泛化能力,并促进该领域的进展。
技术框架:STAR-Gen分类法是论文的核心技术框架。它将泛化分为三个主要维度:视觉泛化、语义泛化和行为泛化。每个维度下又包含多个细分的泛化类型。论文还提供了基于开源模型和ALOHA 2平台的两个案例研究,用于实例化STAR-Gen分类法,并展示如何使用该分类法来评估机器人操作策略的泛化能力。这些案例研究包括具体的任务设置、评估指标和实验结果。
关键创新:论文的关键创新在于提出了STAR-Gen分类法,这是一个全面且细致的机器人操作泛化评估框架。与以往的研究相比,STAR-Gen不仅考虑了视觉泛化,还强调了语义和行为泛化的重要性。此外,论文还提供了可复现的基准测试指南,使得研究人员可以更容易地比较和衡量不同策略的泛化能力。STAR-Gen的提出填补了机器人操作泛化评估领域的空白,为未来的研究奠定了基础。
关键设计:STAR-Gen分类法的关键设计在于其三个维度的划分:视觉泛化关注策略对不同视觉环境的适应能力,语义泛化关注策略对不同物体和概念的理解能力,行为泛化关注策略对不同任务和动作的执行能力。在案例研究中,论文使用了Bridge V2数据集和ALOHA 2平台,并设计了具体的任务和评估指标。例如,在语义泛化方面,论文评估了模型在识别和操作不同类型的物体时的性能。在行为泛化方面,论文评估了模型在执行不同长度和复杂度的任务时的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,开源的视觉-语言-动作模型在语义泛化方面表现不佳,尽管它们在互联网规模的语言数据集上进行了预训练。这表明,仅仅依靠大规模的预训练数据并不能保证模型具有良好的语义理解能力。此外,基于ALOHA 2平台的案例研究表明,对于更灵巧和更长时程的任务,现有的机器人操作策略仍然面临很大的挑战。
🎯 应用场景
该研究成果可广泛应用于机器人操作领域,例如家庭服务机器人、工业自动化机器人和医疗机器人等。通过使用STAR-Gen分类法,可以更好地评估和改进这些机器人的泛化能力,使其能够适应更复杂和多变的环境,从而提高其在实际应用中的可靠性和效率。此外,该研究还有助于推动机器人操作领域的标准化和规范化。
📄 摘要(原文)
Machine learning for robot manipulation promises to unlock generalization to novel tasks and environments. But how should we measure the progress of these policies towards generalization? Evaluating and quantifying generalization is the Wild West of modern robotics, with each work proposing and measuring different types of generalization in their own, often difficult to reproduce settings. In this work, our goal is (1) to outline the forms of generalization we believe are important for robot manipulation in a comprehensive and fine-grained manner, and (2) to provide reproducible guidelines for measuring these notions of generalization. We first propose STAR-Gen, a taxonomy of generalization for robot manipulation structured around visual, semantic, and behavioral generalization. Next, we instantiate STAR-Gen with two case studies on real-world benchmarking: one based on open-source models and the Bridge V2 dataset, and another based on the bimanual ALOHA 2 platform that covers more dexterous and longer horizon tasks. Our case studies reveal many interesting insights: for example, we observe that open-source vision-language-action models often struggle with semantic generalization, despite pre-training on internet-scale language datasets. We provide videos and other supplementary material at our website stargen-taxonomy.github.io.