Beyond Visibility Limits: A DRL-Based Navigation Strategy for Unexpected Obstacles
作者: Mingao Tan, Shanze Wang, Biao Huang, Zhibo Yang, Rongfei Chen, Xiaoyu Shen, Wei Zhang
分类: cs.RO
发布日期: 2025-03-03
💡 一句话要点
提出基于DRL-NSUO的导航策略,解决动态环境中受限视野下意外障碍物的避障问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 机器人导航 动态环境 激光雷达 避障 课程学习 环境感知
📋 核心要点
- 传统基于距离奖励的DRL导航在动态、低视野环境中易碰撞,安全性不足。
- 提出DRL-NSUO,利用激光雷达数据变化率感知环境,结合复合奖励函数和课程学习平衡效率与安全。
- 实验表明,该方法在复杂场景中显著提升了机器人和行人的安全性,成功率优于传统方法。
📝 摘要(中文)
现有的基于深度强化学习(DRL)的导航系统中的基于距离的奖励机制在动态环境中存在严重的安全限制,当视野受限时,经常导致碰撞。本文提出了一种新的针对意外障碍物的导航策略DRL-NSUO,该策略利用激光雷达数据的变化率作为动态环境感知元素。我们的方法结合了具有环境变化率约束的复合奖励函数,并通过课程学习动态调整权重,使机器人能够在路径效率和安全最大化之间自主平衡。通过对激光雷达数据进行短程特征预处理,增强了对附近障碍物的敏感性。实验结果表明,与传统的基于DRL的方法相比,该方法显著提高了复杂场景中机器人和行人的安全性。在BARN导航数据集上的评估结果表明,我们的方法在0.5米/秒和1.0米/秒的速度下分别实现了94.0%和91.0%的成功率,优于保守的障碍物扩展策略。这些结果验证了DRL-NSUO在人机协作环境(包括智能物流应用)中增强的实用性和安全性。
🔬 方法详解
问题定义:现有基于深度强化学习的机器人导航方法,特别是依赖距离作为奖励函数的策略,在动态环境中,尤其是在视野受限的情况下,容易发生碰撞。这是因为机器人无法及时感知到突然出现的障碍物,导致反应时间不足,从而影响安全性。保守的障碍物扩展策略虽然可以提高安全性,但会牺牲路径效率。
核心思路:本文的核心思路是利用激光雷达数据的变化率来增强机器人对动态环境的感知能力。通过监测激光雷达数据随时间的变化,机器人可以更早地检测到潜在的障碍物,从而做出更及时的避障反应。此外,通过设计一个复合奖励函数,并使用课程学习动态调整其权重,可以使机器人在路径效率和安全性之间取得更好的平衡。
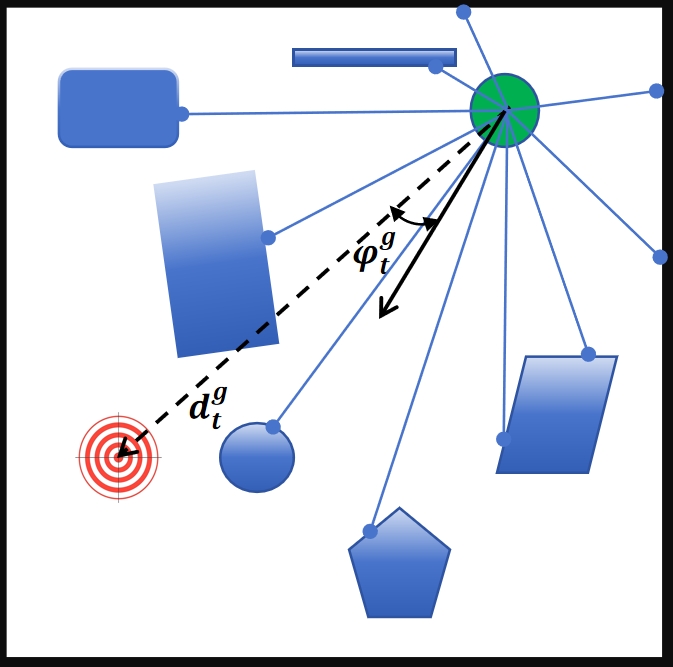
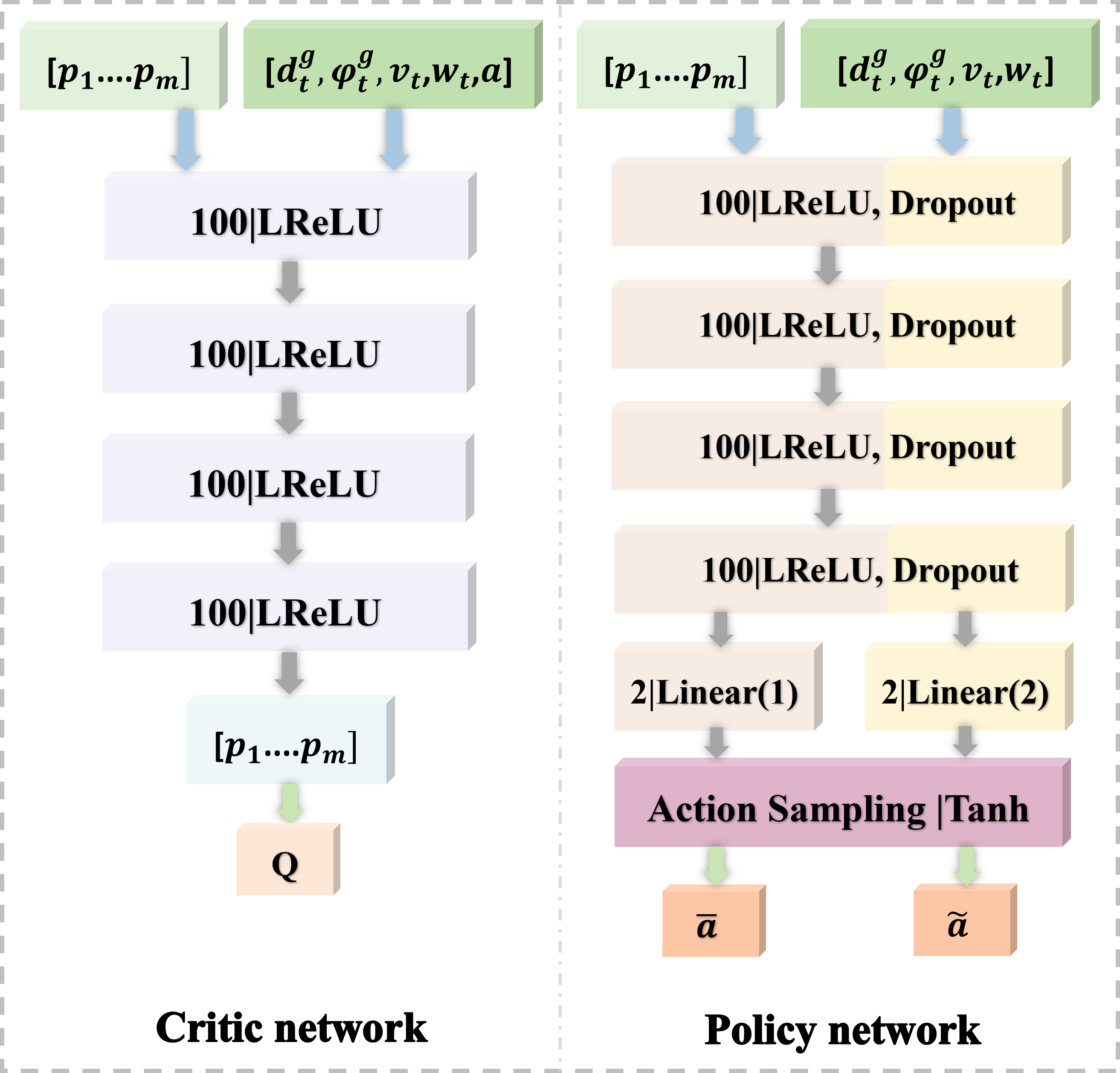
技术框架:该导航系统的整体框架包括以下几个主要模块:1) 激光雷达数据预处理模块,用于提取短程特征,增强对附近障碍物的感知;2) 环境变化率计算模块,用于计算激光雷达数据的变化率,反映环境的动态程度;3) 基于深度强化学习的决策模块,该模块使用环境变化率作为输入,输出机器人的运动控制指令;4) 复合奖励函数模块,用于评估机器人的行为,并提供奖励信号,该奖励函数综合考虑了路径效率、安全性和环境变化率;5) 课程学习模块,用于动态调整复合奖励函数中各个部分的权重,使机器人能够逐步适应更复杂的环境。
关键创新:该论文最重要的技术创新点在于将激光雷达数据的变化率引入到深度强化学习导航系统中。与传统的基于距离的奖励函数相比,这种方法能够更早地检测到潜在的障碍物,从而提高机器人的安全性。此外,通过结合复合奖励函数和课程学习,可以使机器人在路径效率和安全性之间取得更好的平衡,从而提高导航系统的整体性能。
关键设计:在激光雷达数据预处理方面,采用了短程特征提取,以增强对附近障碍物的感知。复合奖励函数的设计综合考虑了路径效率、安全性和环境变化率,具体形式未知。课程学习的具体策略未知,但其目标是动态调整复合奖励函数中各个部分的权重,使机器人能够逐步适应更复杂的环境。深度强化学习模型的具体网络结构和训练参数未知。
🖼️ 关键图片
📊 实验亮点
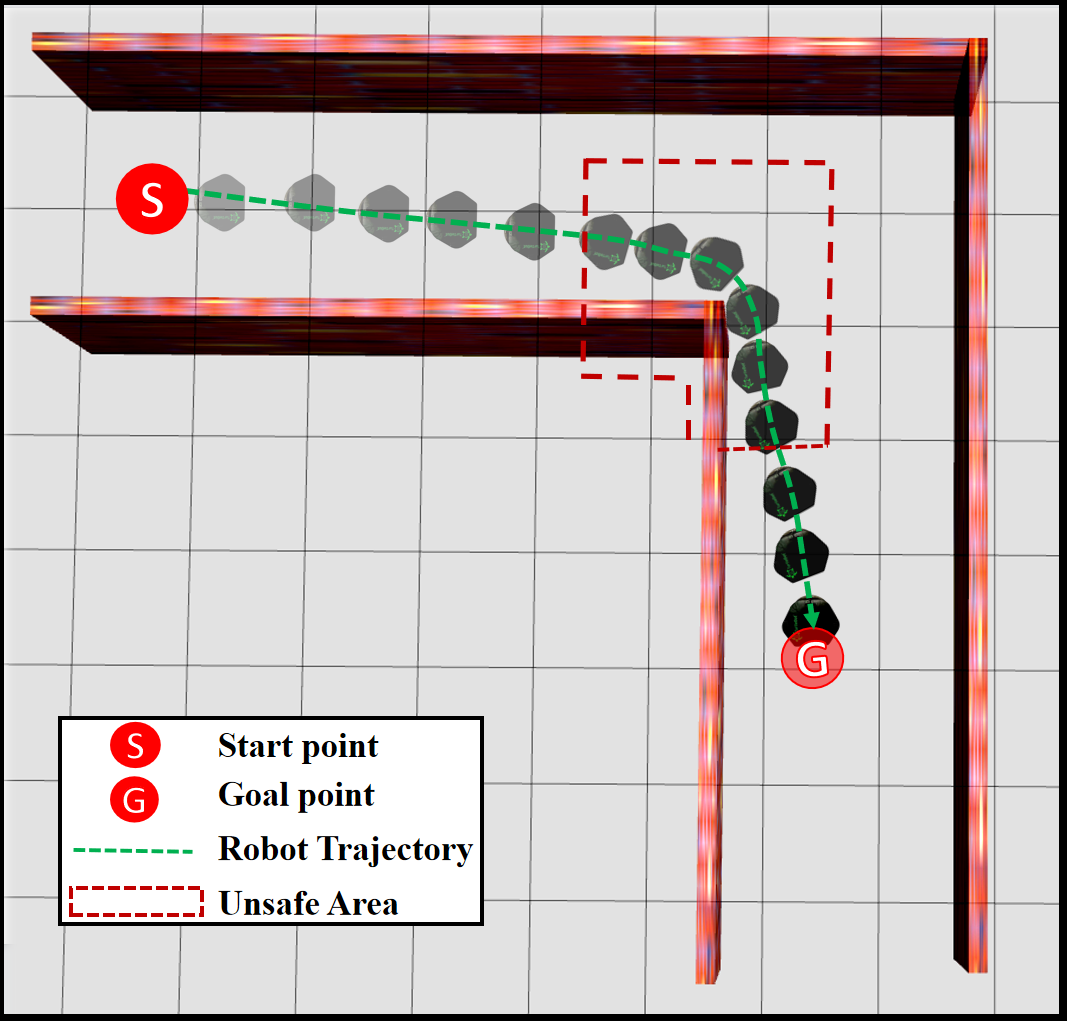
该方法在BARN导航数据集上进行了评估,结果表明,在0.5米/秒和1.0米/秒的速度下,成功率分别达到了94.0%和91.0%,优于传统的基于DRL的方法和保守的障碍物扩展策略。这表明该方法在复杂动态环境中具有更高的安全性和实用性。
🎯 应用场景
该研究成果可应用于智能物流、自动驾驶、服务机器人等领域。在智能物流中,可以提高仓库和配送中心内机器人的导航安全性和效率。在自动驾驶领域,可以增强车辆在复杂城市环境中的避障能力。在服务机器人领域,可以提高机器人在家庭和办公环境中的安全性,使其能够更好地与人类协作。
📄 摘要(原文)
Distance-based reward mechanisms in deep reinforcement learning (DRL) navigation systems suffer from critical safety limitations in dynamic environments, frequently resulting in collisions when visibility is restricted. We propose DRL-NSUO, a novel navigation strategy for unexpected obstacles that leverages the rate of change in LiDAR data as a dynamic environmental perception element. Our approach incorporates a composite reward function with environmental change rate constraints and dynamically adjusted weights through curriculum learning, enabling robots to autonomously balance between path efficiency and safety maximization. We enhance sensitivity to nearby obstacles by implementing short-range feature preprocessing of LiDAR data. Experimental results demonstrate that this method significantly improves both robot and pedestrian safety in complex scenarios compared to traditional DRL-based methods. When evaluated on the BARN navigation dataset, our method achieved superior performance with success rates of 94.0% at 0.5 m/s and 91.0% at 1.0 m/s, outperforming conservative obstacle expansion strategies. These results validate DRL-NSUO's enhanced practicality and safety for human-robot collaborative environments, including intelligent logistics applications.