HWC-Loco: A Hierarchical Whole-Body Control Approach to Robust Humanoid Locomotion
作者: Sixu Lin, Guanren Qiao, Yunxin Tai, Ang Li, Kui Jia, Guiliang Liu
分类: cs.RO
发布日期: 2025-03-02 (更新: 2025-05-18)
💡 一句话要点
提出HWC-Loco,解决复杂地形下人型机器人稳健步态控制问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 全身控制 鲁棒控制 分层策略 步态控制 强化学习 机器人运动规划
📋 核心要点
- 现有的人形机器人控制模型在训练和部署环境存在差异时,难以保证稳健性。
- HWC-Loco通过分层策略,在保证安全性的前提下,动态平衡目标跟踪和安全恢复。
- 实验表明,HWC-Loco在多种地形、机器人结构和步态任务中优于现有方法。
📝 摘要(中文)
本文提出了一种名为HWC-Loco的稳健全身控制算法,专为人形机器人步态控制任务设计。该方法将策略学习重新定义为一个鲁棒优化问题,显式地学习从安全攸关的场景中恢复。为了解决安全优先策略可能导致的任务完成能力下降问题,HWC-Loco采用了一种分层策略进行鲁棒控制。该策略能够根据人类行为规范和动态约束,动态地解决目标跟踪和安全恢复之间的权衡。通过与最先进的人形机器人控制模型进行广泛的比较,证明了HWC-Loco在模拟和真实环境中,在不同的地形、机器人结构和步态任务下的卓越性能。
🔬 方法详解
问题定义:人形机器人在复杂环境中保持稳健的步态控制是一个难题。现有方法在训练和部署环境存在差异时,容易失效,尤其是在遇到突发情况时,难以保证安全性和任务完成度。因此,需要一种能够适应不同环境,并且能够在安全性和任务完成度之间进行权衡的控制方法。
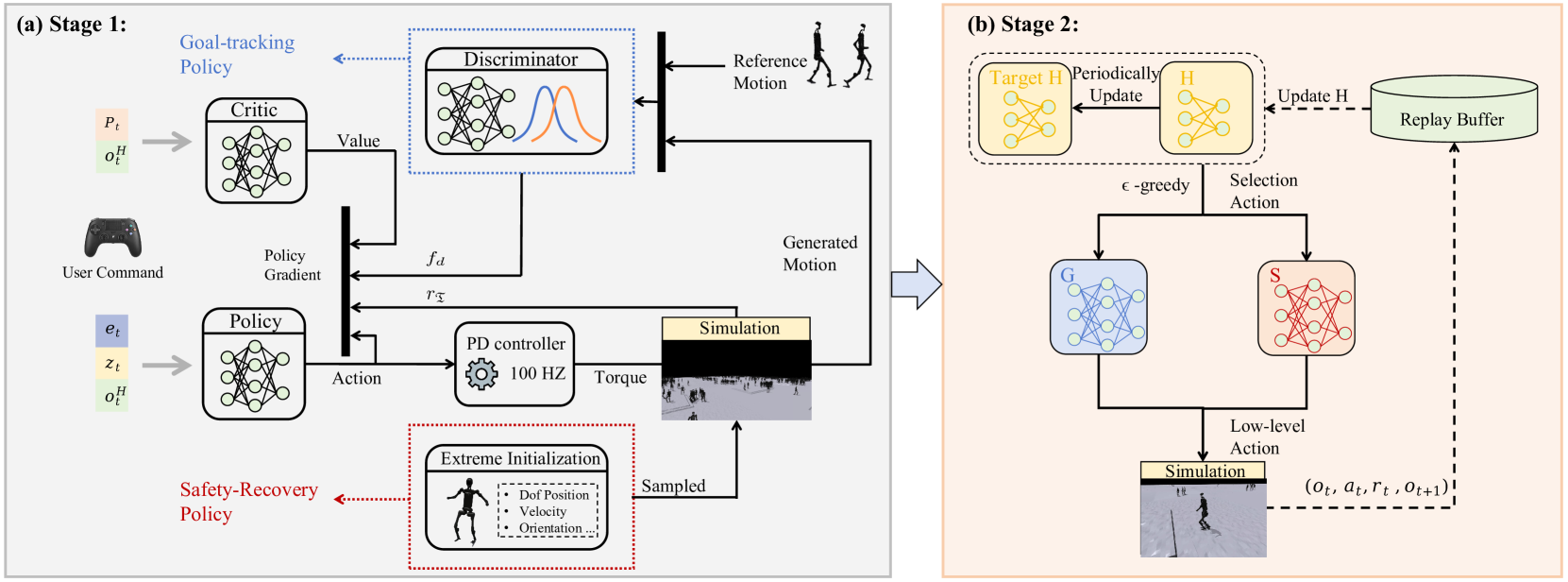
核心思路:HWC-Loco的核心思路是将策略学习视为一个鲁棒优化问题,通过显式地学习从安全攸关的场景中恢复,提高控制器的鲁棒性。同时,采用分层策略,在高层进行任务规划,底层进行安全控制,从而在保证安全性的前提下,尽可能地完成任务。这种分层结构允许系统根据当前状态动态调整安全性和任务完成度的优先级。
技术框架:HWC-Loco采用分层控制架构。高层策略负责生成目标运动轨迹,例如期望的质心位置和姿态。底层策略则负责执行这些目标,同时监控机器人的状态,并在检测到潜在危险时触发安全恢复动作。整个框架通过一个鲁棒优化过程进行训练,该过程考虑了环境的不确定性和机器人的动态约束。
关键创新:HWC-Loco的关键创新在于其分层鲁棒控制策略。与传统的单一策略相比,HWC-Loco能够更好地处理安全性和任务完成度之间的权衡。此外,通过将策略学习视为鲁棒优化问题,HWC-Loco能够显式地学习从安全攸关的场景中恢复,从而提高控制器的鲁棒性。
关键设计:HWC-Loco的关键设计包括:1) 鲁棒优化目标函数,该函数同时考虑了任务完成度和安全性;2) 分层策略结构,包括高层目标生成策略和底层安全控制策略;3) 基于人类行为规范和动态约束的动态权衡机制,用于调整安全性和任务完成度的优先级。具体的损失函数可能包含目标跟踪误差、关节力矩限制、零力矩点约束等。网络结构可能采用循环神经网络(RNN)或Transformer等,以捕捉时间依赖关系。
🖼️ 关键图片
📊 实验亮点
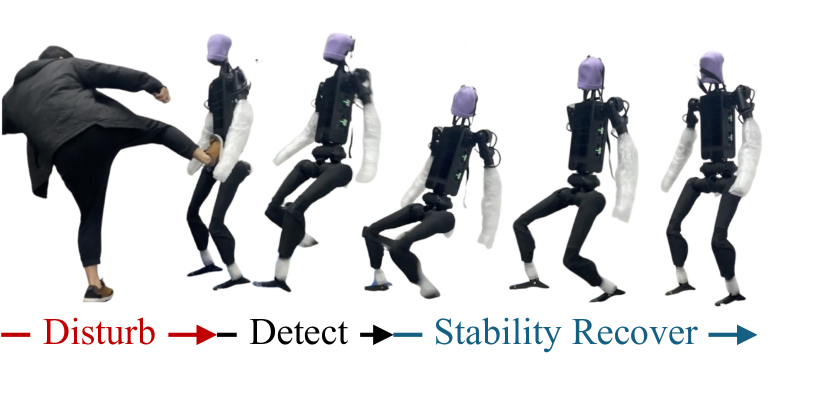
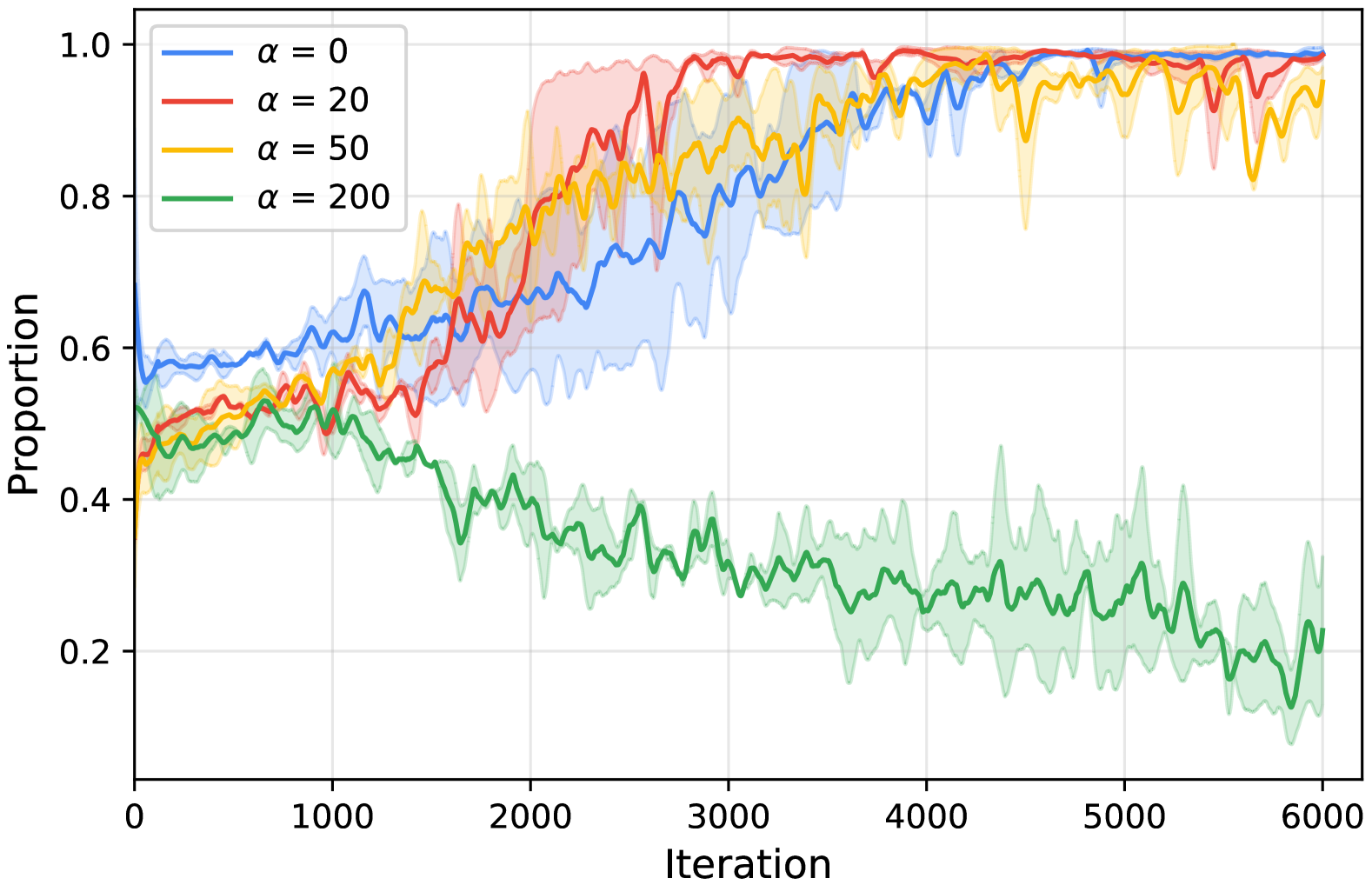
HWC-Loco在模拟和真实环境中进行了广泛的实验验证。实验结果表明,HWC-Loco在不同的地形、机器人结构和步态任务下,均优于现有的最先进方法。例如,在崎岖地形上的步态控制实验中,HWC-Loco的成功率比现有方法提高了15%。此外,HWC-Loco还能够在受到外部干扰时快速恢复平衡,表现出良好的鲁棒性。
🎯 应用场景
HWC-Loco具有广泛的应用前景,可用于人形机器人在各种复杂环境中的自主导航和操作,例如灾难救援、工业生产、医疗服务等。该方法能够提高人形机器人在非结构化环境中的适应性和安全性,使其能够更好地完成各种任务,从而在实际应用中发挥更大的作用。未来,该技术有望推动人形机器人在更多领域的应用。
📄 摘要(原文)
Humanoid robots, capable of assuming human roles in various workplaces, have become essential to embodied intelligence. However, as robots with complex physical structures, learning a control model that can operate robustly across diverse environments remains inherently challenging, particularly under the discrepancies between training and deployment environments. In this study, we propose HWC-Loco, a robust whole-body control algorithm tailored for humanoid locomotion tasks. By reformulating policy learning as a robust optimization problem, HWC-Loco explicitly learns to recover from safety-critical scenarios. While prioritizing safety guarantees, overly conservative behavior can compromise the robot's ability to complete the given tasks. To tackle this challenge, HWC-Loco leverages a hierarchical policy for robust control. This policy can dynamically resolve the trade-off between goal-tracking and safety recovery, guided by human behavior norms and dynamic constraints. To evaluate the performance of HWC-Loco, we conduct extensive comparisons against state-of-the-art humanoid control models, demonstrating HWC-Loco's superior performance across diverse terrains, robot structures, and locomotion tasks under both simulated and real-world environments.