Multi-Keypoint Affordance Representation for Functional Dexterous Grasping
作者: Fan Yang, Dongsheng Luo, Wenrui Chen, Jiacheng Lin, Junjie Cai, Kailun Yang, Zhiyong Li, Yaonan Wang
分类: cs.RO, cs.CV, eess.IV
发布日期: 2025-02-27 (更新: 2025-08-12)
备注: Accepted to IEEE Robotics and Automation Letters (RA-L). The source code and demo videos are publicly available at https://github.com/PopeyePxx/MKA
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于多关键点可供性的灵巧抓取方法,提升视觉感知与操作的连接。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 灵巧抓取 可供性 多关键点 机器人操作 视觉感知
📋 核心要点
- 现有基于可供性的抓取方法无法精确约束抓取姿势,导致视觉感知与操作脱节。
- 提出多关键点可供性表示,通过定位功能性接触点直接编码任务驱动的抓取配置。
- 实验表明,该方法显著提高了可供性定位精度、抓取一致性和泛化能力。
📝 摘要(中文)
功能性灵巧抓取需要精确的手-物交互,超越简单的抓握。现有的基于可供性的方法主要预测粗略的交互区域,无法直接约束抓取姿势,导致视觉感知和操作之间的脱节。为了解决这个问题,我们提出了一种用于功能性灵巧抓取的多关键点可供性表示,通过定位功能性接触点直接编码任务驱动的抓取配置。我们的方法引入了接触引导的多关键点可供性(CMKA),利用人类抓取经验图像进行弱监督,并结合大型视觉模型进行精细的可供性特征提取,在避免手动关键点标注的同时实现泛化。此外,我们提出了一种基于关键点的抓取矩阵变换(KGT)方法,确保手部关键点和物体接触点之间的空间一致性,从而提供视觉感知和灵巧机器人操作之间的直接联系。在公共真实世界FAH数据集、IsaacGym模拟和具有挑战性的机器人任务上的实验表明,我们的方法显著提高了可供性定位精度、抓取一致性和对未见工具和任务的泛化能力,弥合了视觉可供性学习和灵巧机器人操作之间的差距。
🔬 方法详解
问题定义:现有基于可供性的抓取方法通常预测物体上粗略的交互区域,而无法直接约束灵巧手部的抓取姿势。这导致视觉感知和机器人操作之间存在gap,难以实现精确的功能性抓取。现有方法依赖人工标注,泛化性差。
核心思路:论文的核心思路是通过预测物体上的多个关键接触点来表示可供性,这些关键点直接对应于灵巧手部的指尖位置。通过这种方式,可以将视觉感知到的物体信息直接映射到手部的抓取姿势,从而实现精确的抓取控制。利用人类抓取经验图像进行弱监督,并结合大型视觉模型进行特征提取,提升泛化能力。
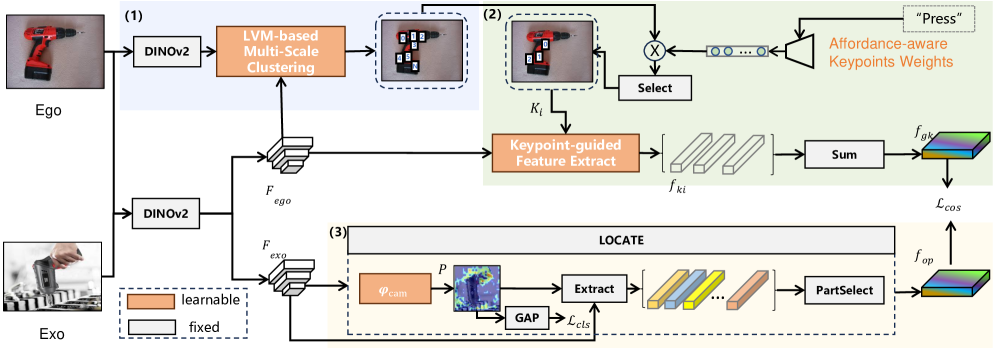
技术框架:整体框架包含两个主要模块:Contact-guided Multi-Keypoint Affordance (CMKA) 和 Keypoint-based Grasp matrix Transformation (KGT)。CMKA模块负责预测物体上的多个关键接触点,利用人类抓取经验图像进行弱监督学习,并使用大型视觉模型提取特征。KGT模块负责将物体上的关键接触点转换为灵巧手部的抓取姿势,确保手部关键点和物体接触点之间的空间一致性。
关键创新:最重要的创新点在于使用多关键点来表示可供性,这与传统的基于区域的可供性表示方法不同。多关键点表示能够更精确地描述物体上的交互位置,并直接约束手部的抓取姿势。另一个创新点是利用人类抓取经验图像进行弱监督学习,避免了手动标注关键点的繁琐过程,并提高了模型的泛化能力。
关键设计:CMKA模块的关键设计包括:1) 使用人类抓取经验图像作为弱监督信号,通过图像中的手部位置推断物体上的接触点位置;2) 利用大型视觉模型(如ResNet)提取图像特征,并使用卷积神经网络预测关键点位置;3) 设计损失函数,鼓励预测的关键点与真实接触点之间的距离最小化。KGT模块的关键设计包括:1) 使用旋转矩阵和平移向量将物体坐标系下的关键点转换到手部坐标系下;2) 设计约束条件,确保手部关键点和物体接触点之间的空间一致性。
🖼️ 关键图片


📊 实验亮点
在FAH数据集上,该方法显著提高了可供性定位精度,超越了现有的基于区域的可供性方法。在IsaacGym模拟和真实机器人实验中,该方法成功实现了对未见工具和任务的灵巧抓取,验证了其泛化能力。实验结果表明,该方法能够有效地弥合视觉感知和灵巧机器人操作之间的差距。
🎯 应用场景
该研究成果可应用于各种需要灵巧操作的机器人任务,例如:工业自动化中的精密装配、医疗机器人中的微创手术、家庭服务机器人中的物品整理等。通过提高机器人抓取的精度和泛化能力,可以显著提升机器人的智能化水平和应用范围,实现更复杂、更精细的操作任务。
📄 摘要(原文)
Functional dexterous grasping requires precise hand-object interaction, going beyond simple gripping. Existing affordance-based methods primarily predict coarse interaction regions and cannot directly constrain the grasping posture, leading to a disconnection between visual perception and manipulation. To address this issue, we propose a multi-keypoint affordance representation for functional dexterous grasping, which directly encodes task-driven grasp configurations by localizing functional contact points. Our method introduces Contact-guided Multi-Keypoint Affordance (CMKA), leveraging human grasping experience images for weak supervision combined with Large Vision Models for fine affordance feature extraction, achieving generalization while avoiding manual keypoint annotations. Additionally, we present a Keypoint-based Grasp matrix Transformation (KGT) method, ensuring spatial consistency between hand keypoints and object contact points, thus providing a direct link between visual perception and dexterous grasping actions. Experiments on public real-world FAH datasets, IsaacGym simulation, and challenging robotic tasks demonstrate that our method significantly improves affordance localization accuracy, grasp consistency, and generalization to unseen tools and tasks, bridging the gap between visual affordance learning and dexterous robotic manipulation. The source code and demo videos are publicly available at https://github.com/PopeyePxx/MKA.