ObjectVLA: End-to-End Open-World Object Manipulation Without Demonstration
作者: Minjie Zhu, Yichen Zhu, Jinming Li, Zhongyi Zhou, Junjie Wen, Xiaoyu Liu, Chaomin Shen, Yaxin Peng, Feifei Feng
分类: cs.RO, cs.CV
发布日期: 2025-02-26 (更新: 2025-02-28)
备注: Project page at https://objectvla.github.io/
💡 一句话要点
ObjectVLA:无需演示的端到端开放世界物体操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 物体泛化 视觉-语言-动作模型 模仿学习 端到端学习
📋 核心要点
- 现有端到端视觉运动策略学习方法在物体泛化方面存在不足,难以将技能迁移到语义相似但视觉不同的新物体。
- ObjectVLA利用视觉-语言对数据,在物体和动作间建立隐式联系,无需为新物体进行人工演示即可实现物体泛化。
- 实验表明,ObjectVLA在100个未见过的物体上实现了64%的成功率,并提出了一种使用智能手机图像微调以增强泛化的方法。
📝 摘要(中文)
模仿学习在机器人灵巧操作技能教学中非常有效。然而,它通常依赖于大量的人工演示数据,这限制了其在动态、真实世界环境中的可扩展性和适用性。一个关键挑战是物体泛化,即训练机器人使用一个物体(如“递苹果”)执行任务时,难以将其技能转移到语义相似但视觉上不同的物体(如“递桃子”)。本文提出了一种简单而有效的通过视觉-语言-动作(VLA)模型实现物体泛化的方法,称为ObjectVLA。我们的模型使机器人能够将学习到的技能推广到新的物体,而无需为每个新的目标物体进行明确的人工演示。通过利用视觉-语言对数据,我们的方法提供了一种轻量级且可扩展的方式来注入关于目标物体的知识,从而在物体和期望的动作之间建立隐式联系。我们在真实的机器人平台上评估了ObjectVLA,证明了其在选择训练期间未见过的100个新物体时具有64%的成功率。此外,我们提出了一种更易于访问的方法来增强VLA模型中的物体泛化,即使用智能手机捕获一些图像并微调预训练模型。这些结果突出了我们的方法在实现物体级别泛化和减少对大量人工演示的需求方面的有效性,为更灵活和可扩展的机器人学习系统铺平了道路。
🔬 方法详解
问题定义:论文旨在解决机器人操作任务中物体泛化能力不足的问题。现有方法通常依赖大量人工演示数据,难以推广到训练集中未出现过的新物体,限制了机器人在真实世界动态环境中的应用。现有端到端视觉运动策略学习方法难以将技能迁移到语义相似但视觉不同的新物体,需要为每个新物体进行大量训练。
核心思路:论文的核心思路是利用视觉-语言-动作(VLA)模型,通过视觉-语言对数据建立物体和动作之间的隐式联系。通过这种方式,模型可以学习到物体和动作之间的对应关系,从而在没有人工演示的情况下,将学习到的技能推广到新的物体上。这种方法避免了为每个新物体收集大量演示数据的需求,提高了模型的可扩展性和泛化能力。
技术框架:ObjectVLA模型接收视觉输入(场景图像)和语言输入(目标物体的描述),输出相应的动作指令。整体框架包含以下几个主要模块:1) 视觉编码器:用于提取场景图像的视觉特征。2) 语言编码器:用于提取目标物体描述的语言特征。3) 视觉-语言融合模块:将视觉特征和语言特征进行融合,得到融合后的特征表示。4) 动作预测模块:根据融合后的特征表示,预测机器人需要执行的动作指令。
关键创新:论文最重要的技术创新点在于利用视觉-语言对数据,在物体和动作之间建立隐式联系,从而实现物体泛化。与现有方法相比,ObjectVLA无需为每个新物体进行人工演示,降低了数据收集成本,提高了模型的可扩展性和泛化能力。此外,论文还提出了一种使用智能手机图像微调预训练模型的方法,进一步增强了物体泛化能力。
关键设计:论文的关键设计包括:1) 视觉编码器采用预训练的卷积神经网络(CNN),如ResNet,以提取鲁棒的视觉特征。2) 语言编码器采用预训练的Transformer模型,如BERT,以提取丰富的语言特征。3) 视觉-语言融合模块采用注意力机制,以更好地融合视觉特征和语言特征。4) 动作预测模块采用多层感知机(MLP),将融合后的特征映射到动作空间。损失函数采用交叉熵损失函数,用于优化动作预测的准确性。
🖼️ 关键图片


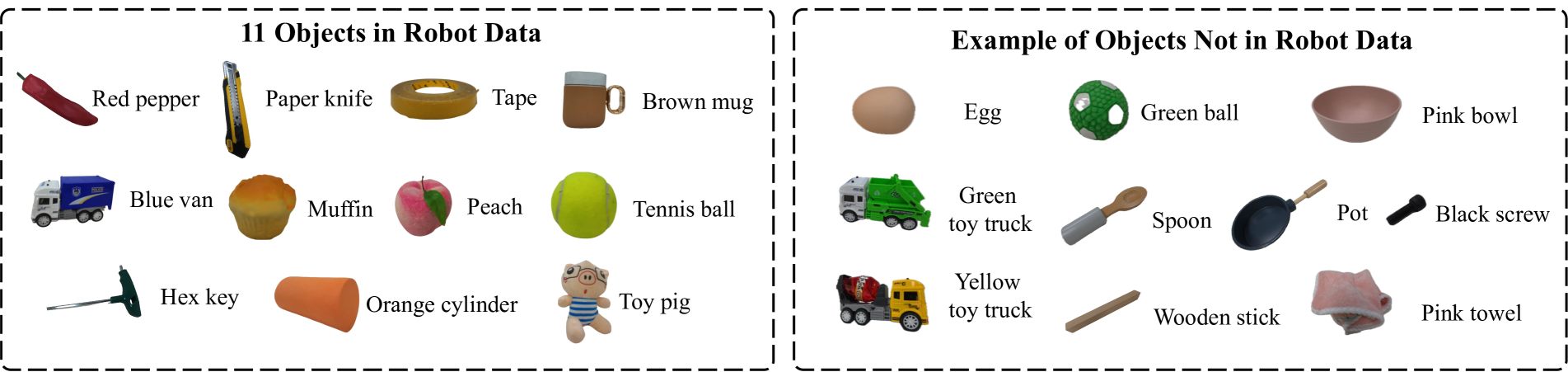
📊 实验亮点
ObjectVLA在真实机器人平台上进行了评估,结果表明,该模型在选择训练期间未见过的100个新物体时,成功率达到64%。此外,论文还提出了一种使用智能手机捕获少量图像并微调预训练模型的方法,进一步增强了物体泛化能力,为VLA模型的物体泛化提供了一种更易于访问的途径。
🎯 应用场景
ObjectVLA具有广泛的应用前景,例如在智能家居、仓储物流、医疗康复等领域。它可以使机器人能够根据用户的指令,灵活地操作各种物体,完成各种任务,而无需事先进行大量的训练和演示。例如,在智能家居中,机器人可以根据用户的语音指令,递送指定的物品;在仓储物流中,机器人可以根据订单信息,拣选和搬运货物;在医疗康复中,机器人可以辅助患者进行康复训练。
📄 摘要(原文)
Imitation learning has proven to be highly effective in teaching robots dexterous manipulation skills. However, it typically relies on large amounts of human demonstration data, which limits its scalability and applicability in dynamic, real-world environments. One key challenge in this context is object generalization, where a robot trained to perform a task with one object, such as "hand over the apple," struggles to transfer its skills to a semantically similar but visually different object, such as "hand over the peach." This gap in generalization to new objects beyond those in the same category has yet to be adequately addressed in previous work on end-to-end visuomotor policy learning. In this paper, we present a simple yet effective approach for achieving object generalization through Vision-Language-Action (VLA) models, referred to as \textbf{ObjectVLA}. Our model enables robots to generalize learned skills to novel objects without requiring explicit human demonstrations for each new target object. By leveraging vision-language pair data, our method provides a lightweight and scalable way to inject knowledge about the target object, establishing an implicit link between the object and the desired action. We evaluate ObjectVLA on a real robotic platform, demonstrating its ability to generalize across 100 novel objects with a 64\% success rate in selecting objects not seen during training. Furthermore, we propose a more accessible method for enhancing object generalization in VLA models, using a smartphone to capture a few images and fine-tune the pre-trained model. These results highlight the effectiveness of our approach in enabling object-level generalization and reducing the need for extensive human demonstrations, paving the way for more flexible and scalable robotic learning systems.