Toward 6-DOF Autonomous Underwater Vehicle Energy-Aware Position Control based on Deep Reinforcement Learning: Preliminary Results
作者: Gustavo Boré, Vicente Sufán, Sebastián Rodríguez-Martínez, Giancarlo Troni
分类: cs.RO, cs.LG, eess.SY
发布日期: 2025-02-25
备注: 6 pages, 5 figures, submitted to 2024 IEEE OES AUV Symposium
💡 一句话要点
提出基于深度强化学习的6自由度水下机器人节能自主位置控制方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自主水下机器人 深度强化学习 6自由度控制 能量效率 TQC算法
📋 核心要点
- 传统PID和模型预测控制(MPC)方法在AUV控制中应用广泛,但依赖精确系统知识,难以适应载荷变化,且调参耗时。
- 论文提出基于TQC算法的DRL方法,直接控制AUV推进器,无需手动调参和系统先验知识,并将功耗纳入奖励函数。
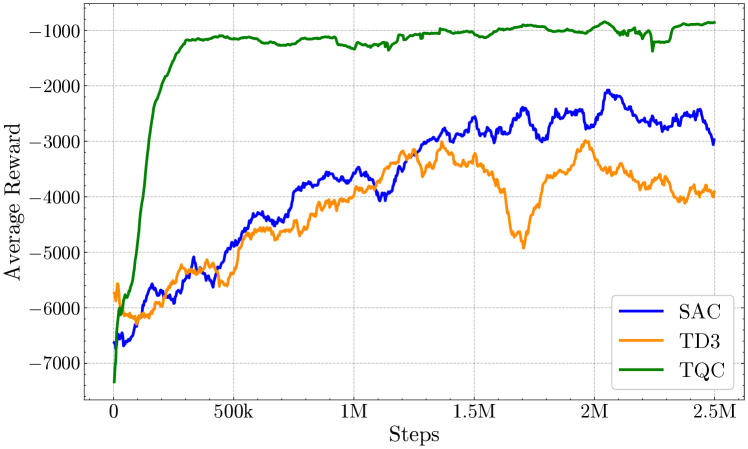
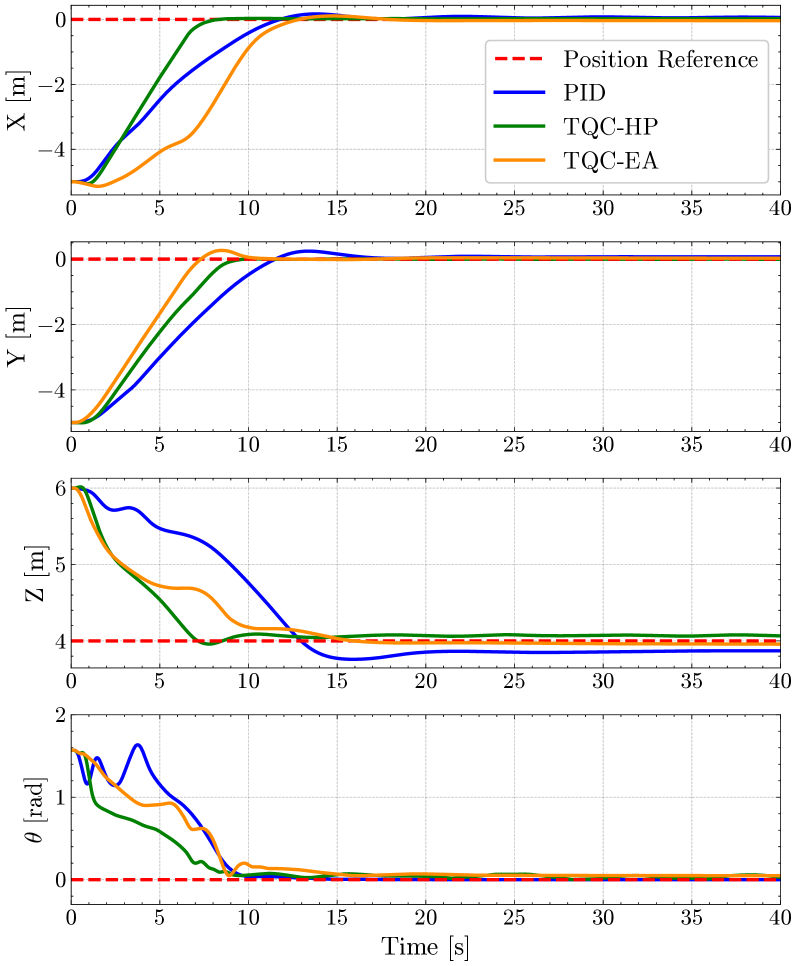
- 仿真结果表明,TQC高性能方法优于PID控制器,而TQC节能方法在性能略降的情况下,功耗平均降低30%。
📝 摘要(中文)
本文提出了一种基于深度强化学习(DRL)的新方法,用于控制全向6自由度(6-DOF)自主水下机器人(AUV)。该方法采用截断分位数评论家(TQC)算法,无需手动调整,直接将指令输入推进器,无需预先了解其配置。此外,它将功耗直接纳入奖励函数中。仿真结果表明,TQC高性能方法在到达目标点时比经过精细调整的PID控制器表现更好,而TQC节能方法虽然性能略有下降,但平均功耗降低了30%。该研究旨在提高AUV在水下勘测、测绘和检查等任务中的机动性和能效,从而延长平台的使用寿命。
🔬 方法详解
问题定义:论文旨在解决全向6自由度AUV在水下定位控制中,传统PID和MPC控制器对系统知识依赖性强、难以适应环境变化以及能效较低的问题。现有方法在面对载荷或配置变化时,需要耗费大量时间进行重新调整,且通常忽略了能量消耗的优化。
核心思路:论文的核心思路是利用深度强化学习(DRL)算法,特别是截断分位数评论家(TQC)算法,直接学习AUV的控制策略,无需预先了解AUV的动力学模型和推进器配置。通过将功耗纳入奖励函数,引导智能体学习节能的控制策略。
技术框架:整体框架包括一个AUV仿真环境和一个DRL智能体。AUV仿真环境提供AUV的状态信息,DRL智能体根据状态信息输出控制指令。TQC算法作为核心的DRL算法,负责学习最优的控制策略。该框架通过不断迭代训练,使智能体能够自主地控制AUV到达目标位置,并尽可能地降低功耗。
关键创新:论文的关键创新在于将TQC算法应用于6自由度AUV的控制,并首次将功耗直接纳入奖励函数中。这使得智能体能够同时优化AUV的定位精度和能量效率。此外,该方法无需手动调整参数和系统辨识,降低了控制器的设计难度。
关键设计:论文中,奖励函数的设计至关重要,它包括了到达目标位置的奖励、控制动作的惩罚以及功耗的惩罚。通过调整这些惩罚项的权重,可以控制智能体在定位精度和能量效率之间的权衡。TQC算法中的截断分位数评论家用于估计状态-动作价值函数,并通过截断操作来提高算法的稳定性和泛化能力。具体的网络结构和参数设置在论文中可能没有详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
仿真结果表明,基于TQC的DRL方法在AUV的6自由度位置控制方面表现出色。TQC高性能方法在到达目标点时优于经过精细调整的PID控制器。更重要的是,TQC节能方法在性能略有下降的情况下,实现了平均30%的功耗降低。这表明该方法在提高AUV能效方面具有显著优势。
🎯 应用场景
该研究成果可应用于水下勘测、测绘、管道检测、海洋环境监测等领域。通过提高AUV的自主性和能效,可以降低水下作业的成本和风险,并延长AUV的续航时间,使其能够执行更长时间和更远距离的任务。未来,该技术有望应用于深海探测、海底资源开发等更具挑战性的场景。
📄 摘要(原文)
The use of autonomous underwater vehicles (AUVs) for surveying, mapping, and inspecting unexplored underwater areas plays a crucial role, where maneuverability and power efficiency are key factors for extending the use of these platforms, making six degrees of freedom (6-DOF) holonomic platforms essential tools. Although Proportional-Integral-Derivative (PID) and Model Predictive Control controllers are widely used in these applications, they often require accurate system knowledge, struggle with repeatability when facing payload or configuration changes, and can be time-consuming to fine-tune. While more advanced methods based on Deep Reinforcement Learning (DRL) have been proposed, they are typically limited to operating in fewer degrees of freedom. This paper proposes a novel DRL-based approach for controlling holonomic 6-DOF AUVs using the Truncated Quantile Critics (TQC) algorithm, which does not require manual tuning and directly feeds commands to the thrusters without prior knowledge of their configuration. Furthermore, it incorporates power consumption directly into the reward function. Simulation results show that the TQC High-Performance method achieves better performance to a fine-tuned PID controller when reaching a goal point, while the TQC Energy-Aware method demonstrates slightly lower performance but consumes 30% less power on average.