COMPASS: Cross-embodiment Mobility Policy via Residual RL and Skill Synthesis
作者: Wei Liu, Huihua Zhao, Chenran Li, Yuchen Deng, Joydeep Biswas, Soha Pouya, Yan Chang
分类: cs.RO
发布日期: 2025-02-22 (更新: 2025-10-27)
💡 一句话要点
COMPASS:通过残差强化学习和技能合成实现跨形态移动策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 跨形态学习 残差强化学习 技能合成 机器人移动控制 模仿学习
📋 核心要点
- 现有移动控制方法需大量人工调整,难以扩展到新机器人形态,模仿学习依赖于各形态的高质量数据。
- COMPASS框架利用单形态专家数据,通过残差强化学习微调策略,并提炼为通用策略,实现跨形态泛化。
- 实验表明,COMPASS显著提升了未见形态的成功率,达到预训练策略的5倍,并实现了零样本的sim-to-real迁移。
📝 摘要(中文)
随着机器人在各种应用领域日益普及,实现跨不同形态的鲁棒移动能力已成为一项关键挑战。传统的移动控制方法虽然在特定平台上有效,但需要针对每个机器人进行大量调整,并且难以扩展到新的形态。模仿学习(IL)等基于学习的方法提供了一种替代方案,但面临着需要为每种形态提供高质量演示数据的重大限制。为了解决这些挑战,我们提出了COMPASS,一个统一的框架,它仅使用来自单个形态的专家演示,即可实现可扩展的跨形态移动。我们首先使用IL在单个机器人上预训练一个移动策略,将世界模型与策略模型相结合。然后,我们应用残差强化学习(RL)通过纠正性改进有效地将该策略适应于不同的形态。最后,我们将专家策略提炼成一个通用的策略,该策略以形态嵌入向量为条件。这种设计显著降低了收集数据的负担,同时实现了跨各种机器人设计的鲁棒泛化。我们的实验表明,COMPASS可以有效地跨各种机器人平台进行扩展,同时保持对各种环境配置的适应性,实现通用策略,其成功率比未见形态上预训练的IL策略高出约5倍,并进一步展示了零样本的sim-to-real迁移。
🔬 方法详解
问题定义:论文旨在解决机器人移动控制策略在不同机器人形态上的泛化问题。现有方法,如传统控制方法和模仿学习,分别存在需要大量人工调整和依赖大量特定形态数据的痛点。这限制了机器人在多样化环境和任务中的部署。
核心思路:论文的核心思路是利用单个机器人形态的专家数据,通过残差强化学习(Residual RL)对预训练策略进行微调,使其能够适应不同的机器人形态。然后,通过技能合成(Skill Synthesis)将多个特定形态的策略提炼成一个通用的、以形态嵌入为条件的策略。这样既减少了数据需求,又提高了泛化能力。
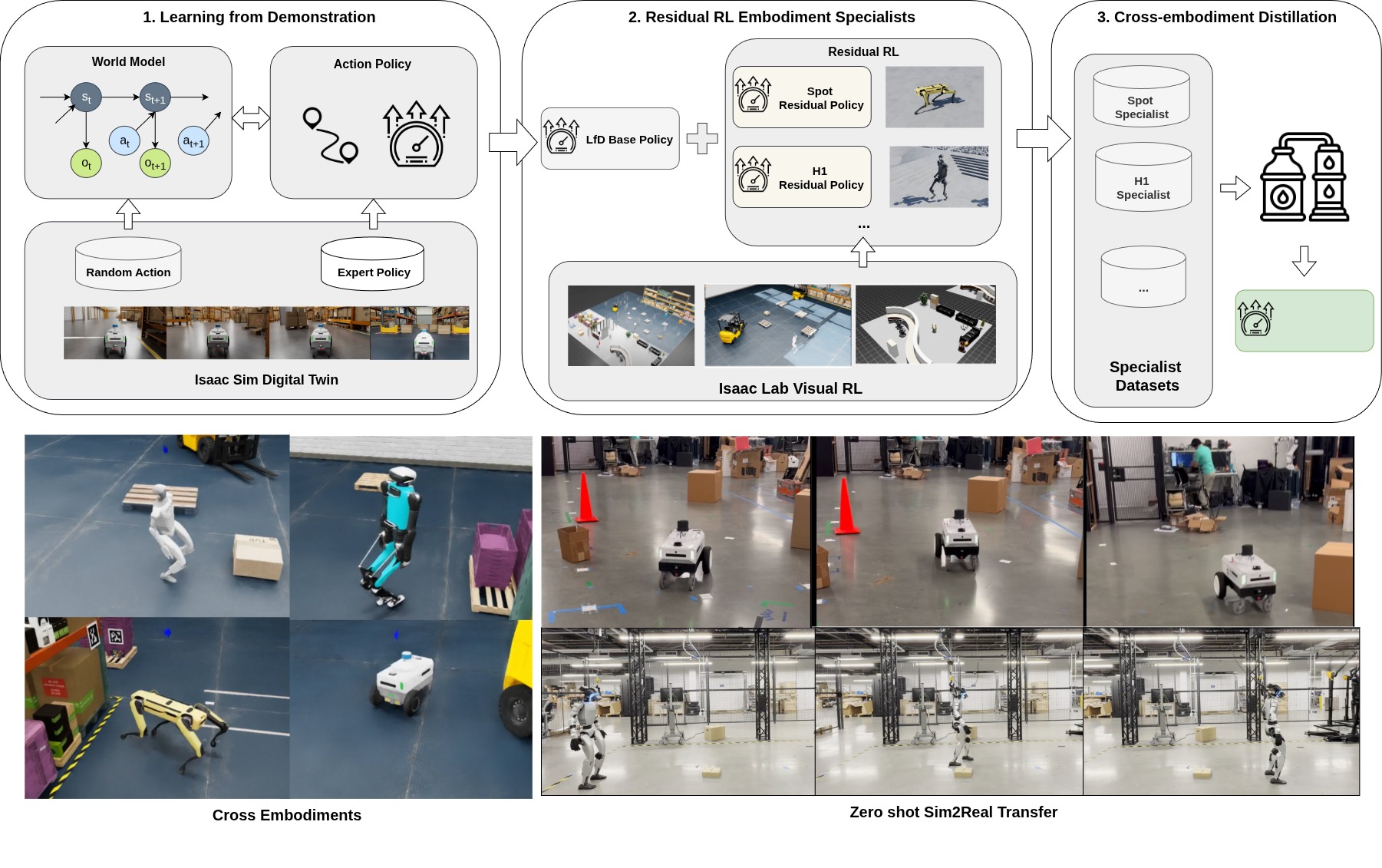
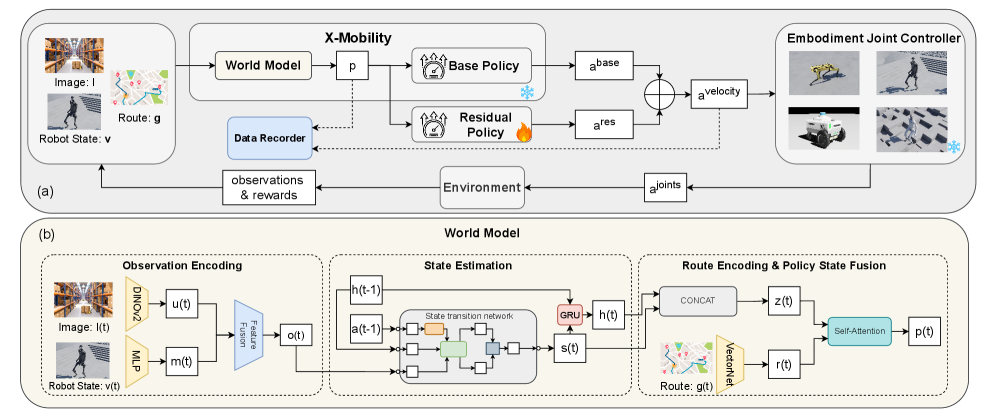
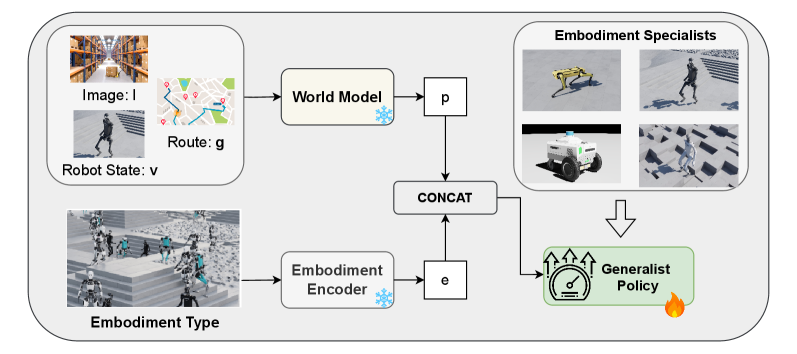
技术框架:COMPASS框架包含三个主要阶段:1) 基于模仿学习的预训练阶段:使用单个机器人形态的专家数据,训练一个初始的移动策略,包括世界模型和策略模型。2) 基于残差强化学习的微调阶段:利用残差强化学习,通过少量环境交互数据,对预训练策略进行微调,使其适应不同的机器人形态。3) 基于技能合成的泛化阶段:将多个特定形态的策略提炼成一个通用的策略,该策略以形态嵌入向量为条件,从而实现跨形态的泛化。
关键创新:COMPASS的关键创新在于结合了残差强化学习和技能合成,实现了仅使用单形态数据即可进行跨形态泛化的移动控制策略。与传统的模仿学习方法相比,COMPASS显著降低了数据收集的成本。与直接使用强化学习训练跨形态策略相比,COMPASS通过预训练和残差学习,提高了训练效率和策略的稳定性。
关键设计:在预训练阶段,使用行为克隆(Behavior Cloning)训练初始策略。在残差强化学习阶段,使用PPO(Proximal Policy Optimization)算法,并引入残差连接,使得策略的更新更加稳定。在技能合成阶段,使用蒸馏学习(Distillation Learning)将多个特定形态的策略提炼成一个通用的策略。形态嵌入向量的设计至关重要,需要能够有效地表征不同机器人形态的特征。
🖼️ 关键图片
📊 实验亮点
COMPASS在多个机器人平台上进行了实验验证,结果表明,其通用策略在未见形态上的成功率比预训练的IL策略高出约5倍。此外,COMPASS还展示了良好的零样本sim-to-real迁移能力,表明该框架具有很强的实用价值。这些实验结果充分证明了COMPASS在跨形态移动控制方面的有效性和优越性。
🎯 应用场景
COMPASS框架具有广泛的应用前景,可用于快速部署移动机器人在各种复杂环境和任务中。例如,在物流、仓储、搜索救援等领域,可以利用该框架快速训练出适应不同机器人平台的移动控制策略,从而提高工作效率和降低开发成本。此外,该框架还可以应用于机器人教育和研究,为学生和研究人员提供一个便捷的跨形态机器人控制平台。
📄 摘要(原文)
As robots are increasingly deployed in diverse application domains, enabling robust mobility across different embodiments has become a critical challenge. Classical mobility stacks, though effective on specific platforms, require extensive per-robot tuning and do not scale easily to new embodiments. Learning-based approaches, such as imitation learning (IL), offer alternatives, but face significant limitations on the need for high-quality demonstrations for each embodiment. To address these challenges, we introduce COMPASS, a unified framework that enables scalable cross-embodiment mobility using expert demonstrations from only a single embodiment. We first pre-train a mobility policy on a single robot using IL, combining a world model with a policy model. We then apply residual reinforcement learning (RL) to efficiently adapt this policy to diverse embodiments through corrective refinements. Finally, we distill specialist policies into a single generalist policy conditioned on an embodiment embedding vector. This design significantly reduces the burden of collecting data while enabling robust generalization across a wide range of robot designs. Our experiments demonstrate that COMPASS scales effectively across diverse robot platforms while maintaining adaptability to various environment configurations, achieving a generalist policy with a success rate approximately 5X higher than the pre-trained IL policy on unseen embodiments, and further demonstrates zero-shot sim-to-real transfer.