Safe Beyond the Horizon: Efficient Sampling-based MPC with Neural Control Barrier Functions
作者: Ji Yin, Oswin So, Eric Yang Yu, Chuchu Fan, Panagiotis Tsiotras
分类: cs.RO, cs.AI, eess.SY
发布日期: 2025-02-20 (更新: 2025-07-08)
备注: Accepted by RSS 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于神经控制屏障函数的采样MPC算法,提升非线性系统安全性和实时性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 模型预测控制 控制屏障函数 采样MPC 安全性 变分推理 机器人控制 非线性系统 实时规划
📋 核心要点
- 传统MPC难以保证预测范围外的安全性,依赖终端约束或长预测范围,但在非线性系统上难以应用。
- 通过学习控制屏障函数并融入采样MPC框架,在安全性和计算效率间取得平衡,适用于黑盒系统。
- 提出的采样策略降低了方差,提升了采样效率,实现了CPU上的实时规划,并在实验中验证了安全性。
📝 摘要(中文)
本文针对模型预测控制(MPC)在实际应用中难以保证预测范围之外安全规范的问题,提出了一种新的解决方案。该方案通过学习近似的离散时间控制屏障函数,并将其融入到变分推理MPC(VIMPC)框架中,从而在精确递归可行性、计算复杂度和对“黑盒”动态系统的适用性之间取得平衡。为了处理由此产生的状态约束,本文还提出了一种新的采样策略,显著降低了估计最优控制的方差,提高了采样效率,并实现了在CPU上的实时规划。实验结果表明,所提出的神经屏蔽-VIMPC(NS-VIMPC)控制器相比现有的基于采样的MPC控制器,在安全性方面有显著提升,即使在设计不良的成本函数下也是如此。该方法已在仿真和真实硬件实验中得到验证。
🔬 方法详解
问题定义:在模型预测控制(MPC)中,一个关键问题是如何保证系统在预测范围之外的安全性。传统的解决方案,例如施加合适的终端集合约束或使用足够长的预测范围,在理论上可以保证安全性,但这些方法在实际应用中面临挑战,尤其是在处理一般的非线性动态系统时,往往难以实现。现有的基于采样的MPC方法在安全性方面也存在不足,容易违反安全约束。
核心思路:本文的核心思路是利用神经控制屏障函数(Neural Control Barrier Functions, NCBFs)来近似表示系统的安全区域,并将其融入到基于采样的MPC框架中。通过学习一个离散时间的控制屏障函数,并在MPC的优化过程中强制满足该函数,从而保证系统在预测范围之外的安全性。同时,为了提高计算效率,采用了变分推理MPC(VIMPC)框架,并设计了一种新的采样策略。
技术框架:整体框架可以分为三个主要部分:1)离线学习控制屏障函数:使用神经网络学习一个近似的离散时间控制屏障函数,该函数能够反映系统的安全状态。2)在线MPC优化:在每个控制周期,使用VIMPC框架进行优化,目标是最小化成本函数,同时满足控制屏障函数的约束。3)采样策略改进:为了处理状态约束,提出了一种新的采样策略,降低了估计最优控制的方差,提高了采样效率。
关键创新:本文的关键创新在于将神经控制屏障函数与采样MPC相结合,提出了一种新的安全MPC算法。与传统的基于终端集合约束的方法相比,该方法不需要显式地设计终端集合,更易于应用。与现有的基于采样的MPC方法相比,该方法能够更好地保证系统的安全性。此外,提出的新的采样策略也显著提高了采样效率。
关键设计:控制屏障函数使用神经网络进行近似,网络的结构和训练数据需要根据具体的系统进行设计。VIMPC框架中的变分分布参数需要仔细调整,以保证优化过程的稳定性和效率。新的采样策略的关键在于如何有效地利用控制屏障函数的信息来指导采样过程,降低方差。损失函数的设计需要平衡成本函数和安全约束之间的关系。
🖼️ 关键图片
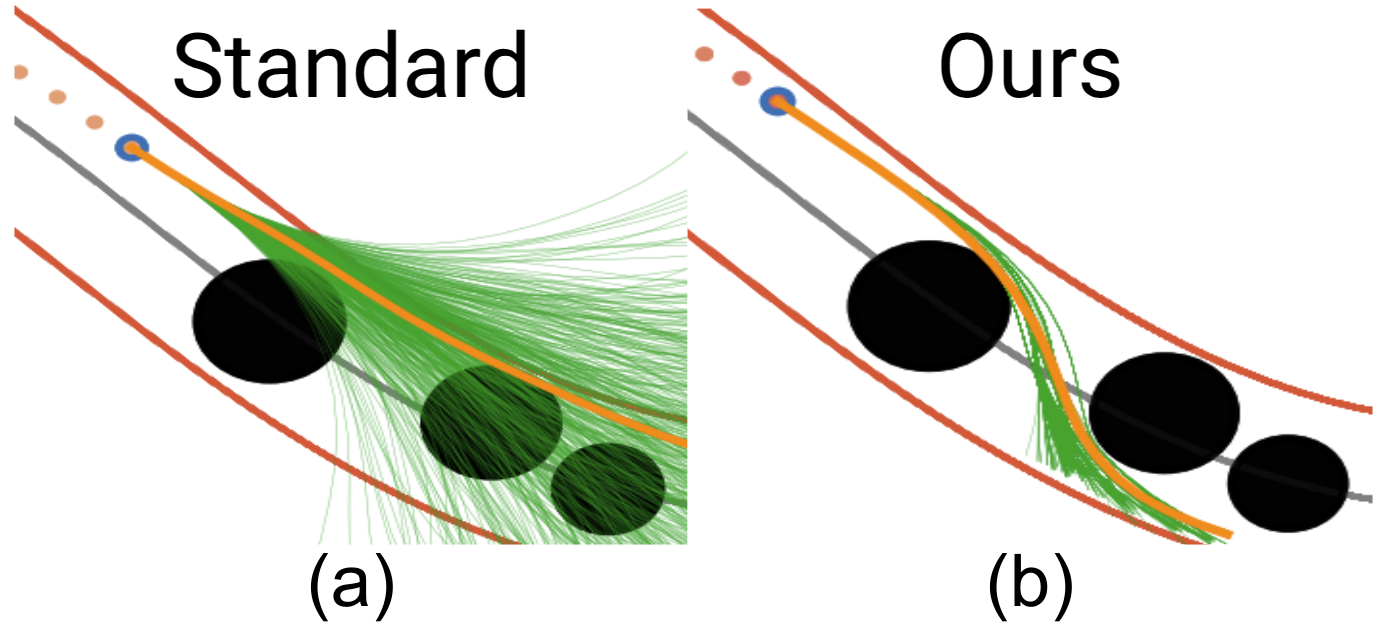
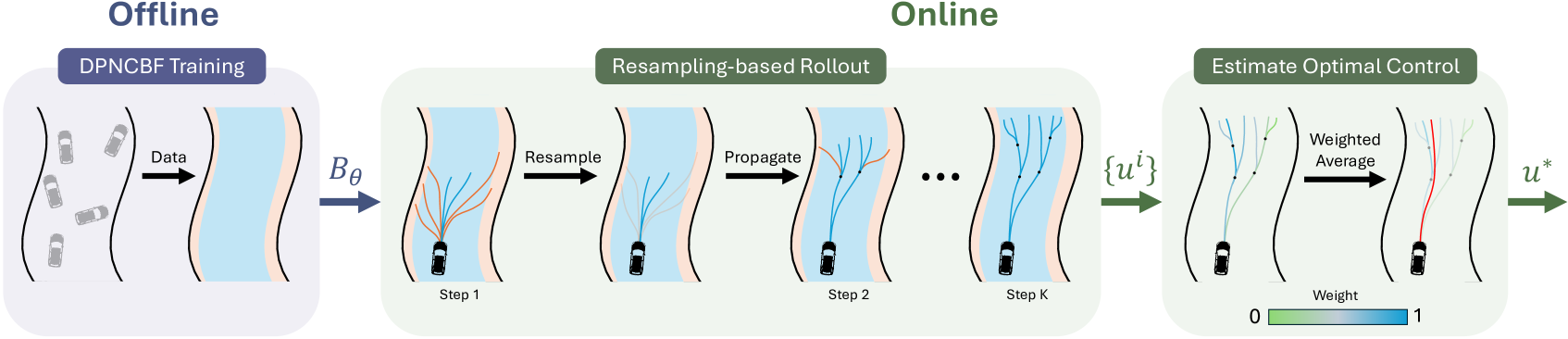

📊 实验亮点
实验结果表明,NS-VIMPC在安全性方面优于现有的采样MPC方法。在仿真和真实硬件实验中,NS-VIMPC能够显著减少安全约束的违反次数,即使在成本函数设计不良的情况下也能保持较高的安全性。此外,新的采样策略显著提高了采样效率,使得NS-VIMPC能够在CPU上实现实时规划。
🎯 应用场景
该研究成果可应用于各种需要安全保障的机器人控制场景,例如自动驾驶、无人机导航、工业机器人等。通过确保系统在复杂环境中的安全性,可以提高系统的可靠性和鲁棒性,降低事故发生的风险。此外,该方法对“黑盒”动态系统的适用性使其在模型不确定或难以精确建模的场景中具有重要价值。
📄 摘要(原文)
A common problem when using model predictive control (MPC) in practice is the satisfaction of safety specifications beyond the prediction horizon. While theoretical works have shown that safety can be guaranteed by enforcing a suitable terminal set constraint or a sufficiently long prediction horizon, these techniques are difficult to apply and thus are rarely used by practitioners, especially in the case of general nonlinear dynamics. To solve this problem, we impose a tradeoff between exact recursive feasibility, computational tractability, and applicability to ``black-box'' dynamics by learning an approximate discrete-time control barrier function and incorporating it into a variational inference MPC (VIMPC), a sampling-based MPC paradigm. To handle the resulting state constraints, we further propose a new sampling strategy that greatly reduces the variance of the estimated optimal control, improving the sample efficiency, and enabling real-time planning on a CPU. The resulting Neural Shield-VIMPC (NS-VIMPC) controller yields substantial safety improvements compared to existing sampling-based MPC controllers, even under badly designed cost functions. We validate our approach in both simulation and real-world hardware experiments. Project website: https://mit-realm.github.io/ns-vimpc/.