ChatVLA: Unified Multimodal Understanding and Robot Control with Vision-Language-Action Model
作者: Zhongyi Zhou, Yichen Zhu, Minjie Zhu, Junjie Wen, Ning Liu, Zhiyuan Xu, Weibin Meng, Ran Cheng, Yaxin Peng, Chaomin Shen, Feifei Feng
分类: cs.RO, cs.CV, cs.LG
发布日期: 2025-02-20 (更新: 2025-02-21)
💡 一句话要点
ChatVLA:通过视觉-语言-动作模型实现统一的多模态理解和机器人控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 多模态理解 机器人控制 分阶段对齐训练 混合专家架构
📋 核心要点
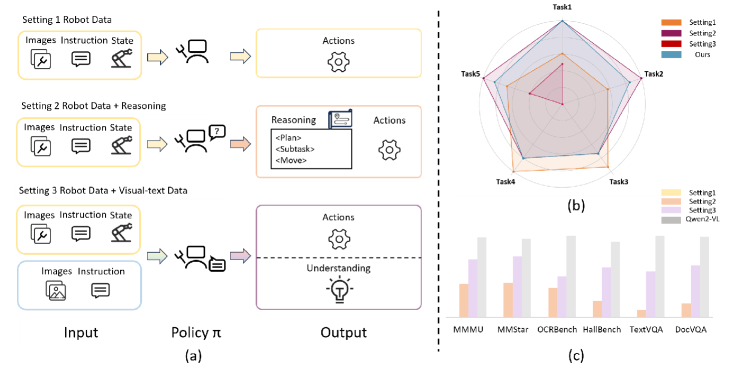
- 现有视觉-语言-动作模型(VLA)在联合训练时面临虚假遗忘和任务干扰问题,导致多模态理解能力不足。
- ChatVLA采用分阶段对齐训练,先训练控制能力,再逐步整合多模态数据,并使用混合专家架构减少任务干扰。
- 实验表明,ChatVLA在多模态理解和机器人控制任务上均优于现有VLA方法,并在MMMU数据集上取得了显著提升。
📝 摘要(中文)
本文提出了一种名为ChatVLA的新框架,旨在解决视觉-语言-动作模型(VLA)中存在的两个关键挑战:虚假遗忘(机器人训练覆盖了关键的视觉-文本对齐)和任务干扰(竞争性的控制和理解任务在联合训练时降低性能)。ChatVLA采用分阶段对齐训练,在初始控制能力掌握后逐步整合多模态数据,并使用混合专家架构来最小化任务干扰。实验结果表明,ChatVLA在视觉问答数据集上表现出色,并在多模态理解基准测试中显著超越了最先进的VLA方法。尤其是在MMMU上实现了六倍的性能提升,并在MMStar上获得了47.2%的分数,且参数效率高于ECoT。此外,ChatVLA在25个真实世界机器人操作任务中也表现出优于OpenVLA等现有VLA方法的性能。研究结果突出了该统一框架在实现鲁棒的多模态理解和有效的机器人控制方面的潜力。
🔬 方法详解
问题定义:现有视觉-语言-动作模型(VLA)在训练过程中存在两个主要问题。一是“虚假遗忘”,即机器人控制任务的训练会覆盖掉模型中原本存在的视觉和文本之间的对齐关系,导致模型的多模态理解能力下降。二是“任务干扰”,即控制任务和理解任务在联合训练时会相互干扰,导致模型在两个任务上的性能都无法达到最优。
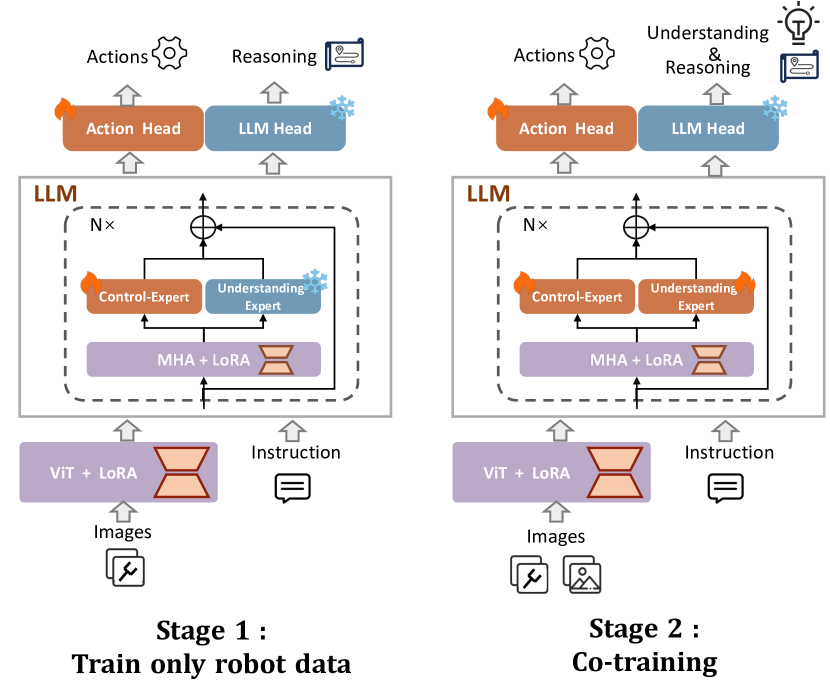
核心思路:ChatVLA的核心思路是将多模态理解和机器人控制任务解耦,采用分阶段训练的方式。首先训练模型掌握基本的机器人控制能力,然后再逐步引入多模态数据,以避免控制任务对视觉-文本对齐的干扰。同时,使用混合专家架构来进一步减少任务之间的干扰,使得模型能够更好地学习和利用不同模态的信息。
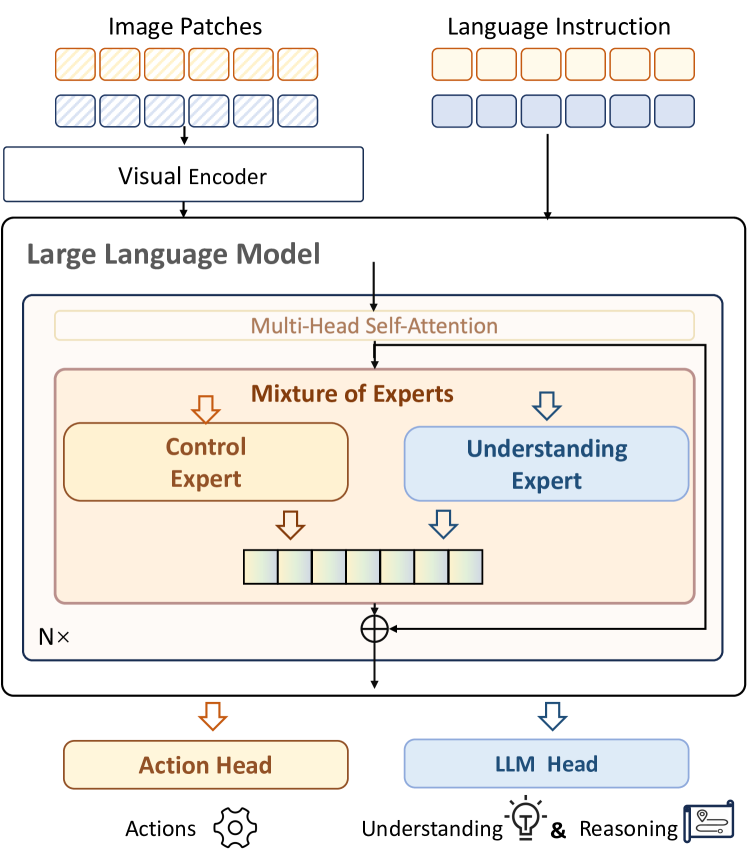
技术框架:ChatVLA的整体框架主要包括两个阶段:预训练阶段和微调阶段。在预训练阶段,模型首先在一个大规模的机器人控制数据集上进行训练,以学习基本的控制策略。然后,在微调阶段,模型在一个多模态数据集上进行训练,以学习视觉、语言和动作之间的关系。在微调阶段,采用了分阶段对齐训练策略,逐步增加多模态数据的比例。此外,模型还采用了混合专家架构,将不同的任务分配给不同的专家网络进行处理,从而减少任务之间的干扰。
关键创新:ChatVLA的关键创新在于分阶段对齐训练策略和混合专家架构。分阶段对齐训练策略能够有效地避免虚假遗忘问题,使得模型能够更好地保留视觉-文本对齐关系。混合专家架构能够有效地减少任务之间的干扰,使得模型能够更好地学习和利用不同模态的信息。
关键设计:在分阶段对齐训练中,采用了线性增加多模态数据比例的方式。在混合专家架构中,采用了门控机制来动态地选择不同的专家网络。损失函数包括控制损失、理解损失和对齐损失。控制损失用于训练机器人控制能力,理解损失用于训练多模态理解能力,对齐损失用于促进视觉、语言和动作之间的对齐。
🖼️ 关键图片
📊 实验亮点
ChatVLA在MMMU数据集上取得了显著的性能提升,达到了现有最佳方法(ECoT)的六倍。在MMStar数据集上,ChatVLA获得了47.2%的分数,且参数效率高于ECoT。此外,在25个真实世界机器人操作任务中,ChatVLA也表现出优于OpenVLA等现有VLA方法的性能。这些实验结果表明,ChatVLA在多模态理解和机器人控制方面具有显著的优势。
🎯 应用场景
ChatVLA具有广泛的应用前景,可应用于智能家居、自动驾驶、工业机器人等领域。例如,在智能家居中,ChatVLA可以帮助机器人理解用户的语音指令,并根据用户的需求执行相应的任务。在自动驾驶中,ChatVLA可以帮助车辆理解周围环境的信息,并做出相应的驾驶决策。在工业机器人中,ChatVLA可以帮助机器人完成复杂的装配和操作任务。该研究有望推动人机交互和机器人技术的进一步发展。
📄 摘要(原文)
Humans possess a unified cognitive ability to perceive, comprehend, and interact with the physical world. Why can't large language models replicate this holistic understanding? Through a systematic analysis of existing training paradigms in vision-language-action models (VLA), we identify two key challenges: spurious forgetting, where robot training overwrites crucial visual-text alignments, and task interference, where competing control and understanding tasks degrade performance when trained jointly. To overcome these limitations, we propose ChatVLA, a novel framework featuring Phased Alignment Training, which incrementally integrates multimodal data after initial control mastery, and a Mixture-of-Experts architecture to minimize task interference. ChatVLA demonstrates competitive performance on visual question-answering datasets and significantly surpasses state-of-the-art vision-language-action (VLA) methods on multimodal understanding benchmarks. Notably, it achieves a six times higher performance on MMMU and scores 47.2% on MMStar with a more parameter-efficient design than ECoT. Furthermore, ChatVLA demonstrates superior performance on 25 real-world robot manipulation tasks compared to existing VLA methods like OpenVLA. Our findings highlight the potential of our unified framework for achieving both robust multimodal understanding and effective robot control.