SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
作者: Zekun Qi, Wenyao Zhang, Yufei Ding, Runpei Dong, Xinqiang Yu, Jingwen Li, Lingyun Xu, Baoyu Li, Xialin He, Guofan Fan, Jiazhao Zhang, Jiawei He, Jiayuan Gu, Xin Jin, Kaisheng Ma, Zhizheng Zhang, He Wang, Li Yi
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-02-18 (更新: 2025-09-24)
备注: Accepted at NeurIPS 2025 Spotlight
💡 一句话要点
提出SoFar框架以解决物体操作中的方向感知问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 语义方向 空间推理 物体操作 视觉语言模型 零样本学习 机器人技术 数据集构建
📋 核心要点
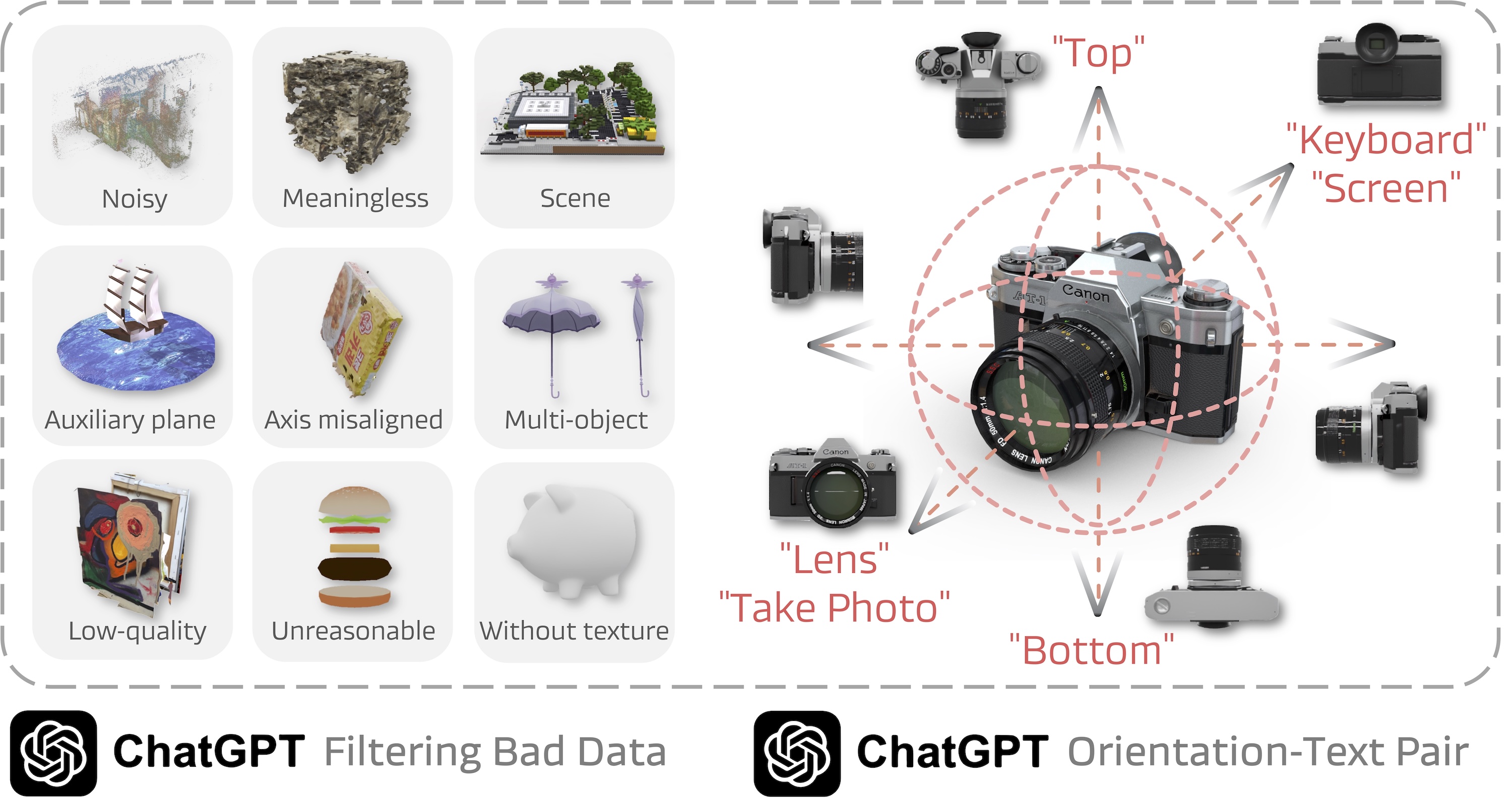
- 现有方法在物体定位时忽视了方向感知,限制了6自由度操作的精度和灵活性。
- 本文提出了语义方向的概念,利用自然语言定义物体方向,构建了大规模数据集OrienText300K。
- SoFar框架在多个基准测试中表现出色,Open6DOR和SIMPLER-Env的零样本成功率分别为48.7%和74.9%。
📝 摘要(中文)
尽管空间推理在物体定位关系上取得了进展,但往往忽视了物体方向这一关键因素,限制了6自由度精细操作的能力。本文引入了语义方向的概念,通过自然语言定义物体方向,构建了OrienText300K数据集,并开发了PointSO模型以实现零样本语义方向预测。通过将语义方向整合到视觉语言模型中,SoFar框架实现了6自由度空间推理并生成机器人动作。实验结果表明,SoFar在Open6DOR和SIMPLER-Env上分别达到了48.7%和74.9%的零样本成功率,展示了其有效性和泛化能力。
🔬 方法详解
问题定义:本文旨在解决现有物体操作方法中对物体方向感知不足的问题。传统的姿态表示依赖于预定义的框架或模板,导致泛化能力差和语义基础不牢。
核心思路:提出语义方向的概念,通过自然语言描述物体的方向,避免了框架依赖,从而增强了模型的灵活性和适应性。
技术框架:整体架构包括数据集构建、模型开发和集成应用三个主要阶段。首先,构建OrienText300K数据集;其次,开发PointSO模型用于零样本预测;最后,将模型整合进视觉语言模型中以实现空间推理和机器人动作生成。
关键创新:最重要的创新在于引入了语义方向的定义方式,使得物体方向的表示不再依赖于固定的坐标系,从而提升了操作的精细度和灵活性。
关键设计:在模型设计中,采用了特定的损失函数以优化语义方向的预测精度,并通过多层神经网络结构增强模型的表达能力。
🖼️ 关键图片


📊 实验亮点
在实验中,SoFar框架在Open6DOR和SIMPLER-Env数据集上分别实现了48.7%和74.9%的零样本成功率,显著优于现有基线方法,展示了其在空间推理和物体操作中的有效性和广泛适用性。
🎯 应用场景
该研究的潜在应用领域包括机器人操作、增强现实和智能家居等。通过提升机器人对物体方向的理解能力,能够实现更为复杂和精细的操作,进而推动智能设备在实际生活中的应用和普及。
📄 摘要(原文)
While spatial reasoning has made progress in object localization relationships, it often overlooks object orientation-a key factor in 6-DoF fine-grained manipulation. Traditional pose representations rely on pre-defined frames or templates, limiting generalization and semantic grounding. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the "plug-in" direction of a USB or the "handle" direction of a cup). To support this, we construct OrienText300K, a large-scale dataset of 3D objects annotated with semantic orientations, and develop PointSO, a general model for zero-shot semantic orientation prediction. By integrating semantic orientation into VLM agents, our SoFar framework enables 6-DoF spatial reasoning and generates robotic actions. Extensive experiments demonstrated the effectiveness and generalization of our SoFar, e.g., zero-shot 48.7% successful rate on Open6DOR and zero-shot 74.9% successful rate on SIMPLER-Env.