BFA: Best-Feature-Aware Fusion for Multi-View Fine-grained Manipulation
作者: Zihan Lan, Weixin Mao, Haosheng Li, Le Wang, Tiancai Wang, Haoqiang Fan, Osamu Yoshie
分类: cs.RO, cs.CV
发布日期: 2025-02-16 (更新: 2025-06-28)
备注: 8 pages, 4 figures
💡 一句话要点
提出BFA:一种最佳特征感知融合方法,用于多视角精细操作任务
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多视角学习 机器人操作 精细操作 特征融合 注意力机制
📋 核心要点
- 现有方法在多视角精细操作中直接连接所有视角特征,忽略了视角的重要性差异,导致冗余信息和计算成本增加。
- 论文提出最佳特征感知(BFA)融合策略,通过预测每个视角的重要性得分,自适应地融合多视角特征。
- 实验结果表明,BFA方法在精细操作任务中显著优于现有基线方法,成功率提升22-46%。
📝 摘要(中文)
在实际场景中,多视角相机通常用于精细操作任务。现有方法(如ACT)倾向于平等对待多视角特征,并直接将它们连接起来进行策略学习。然而,这会引入冗余的视觉信息,并带来更高的计算成本,导致操作效率低下。对于精细操作任务,它往往涉及多个阶段,而不同阶段贡献最大的视角随时间变化。本文提出了一种即插即用的最佳特征感知(BFA)融合策略,用于多视角操作任务,该策略适用于各种策略。基于策略网络的视觉骨干网络,我们设计了一个轻量级网络来预测每个视角的重要性得分。基于预测的重要性得分,重新加权的多视角特征随后被融合并输入到端到端策略网络中,从而实现无缝集成。值得注意的是,我们的方法在精细操作中表现出卓越的性能。实验结果表明,我们的方法在不同任务上的成功率优于多个基线22-46%。我们的工作为解决精细操作中的关键挑战提供了新的见解和启发。
🔬 方法详解
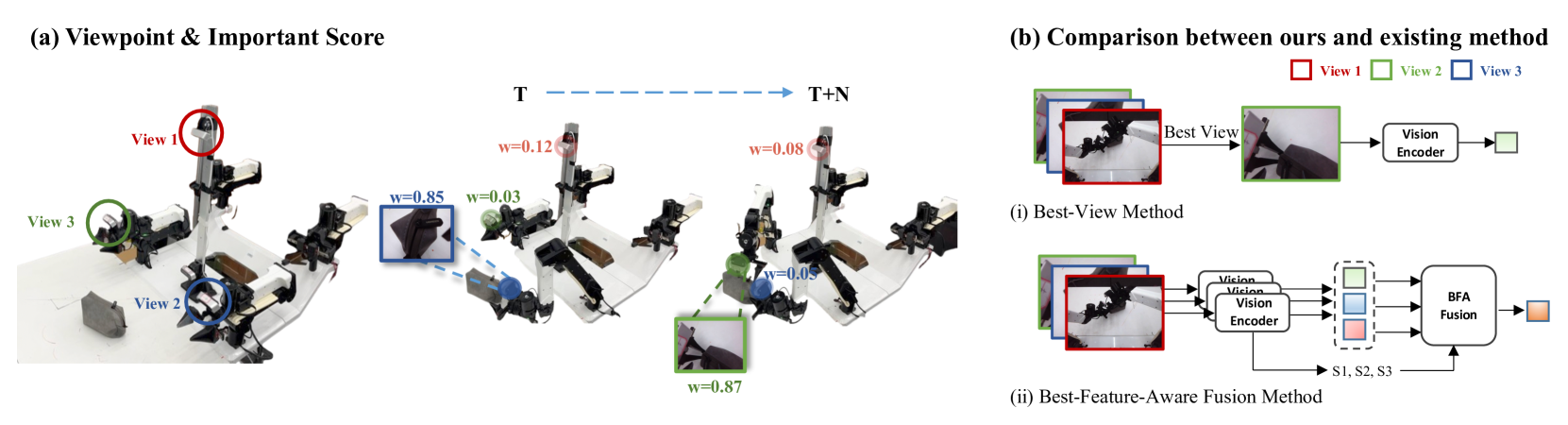
问题定义:现有基于多视角信息的机器人操作方法,例如ACT,通常平等地对待来自不同视角的特征,直接进行拼接融合。这种方式没有考虑到不同视角在不同操作阶段的重要性差异,引入了冗余信息,增加了计算负担,最终影响了操作的精度和效率。特别是在精细操作任务中,不同阶段可能需要依赖不同的视角信息。
核心思路:论文的核心思路是学习一个视角重要性预测模块,根据当前的操作状态,动态地评估每个视角的重要性,并根据重要性得分对不同视角的特征进行加权融合。这样可以突出重要视角的信息,抑制不相关视角的信息,从而提高操作策略的效率和精度。
技术框架:BFA方法作为一个即插即用的模块,可以嵌入到现有的策略网络中。其整体框架包括:1) 视觉骨干网络:用于提取多视角图像的特征;2) 视角重要性预测网络:一个轻量级的网络,输入视觉特征,输出每个视角的重要性得分;3) 特征融合模块:根据视角重要性得分,对多视角特征进行加权融合;4) 策略网络:接收融合后的特征,输出操作指令。
关键创新:BFA的关键创新在于提出了最佳特征感知的融合策略,能够根据操作状态动态地选择和融合最重要的视角特征。与现有方法直接拼接所有视角特征相比,BFA能够更有效地利用多视角信息,提高操作的精度和效率。这种动态选择机制使得模型能够专注于对当前操作阶段最有帮助的视角,从而更好地完成精细操作任务。
关键设计:视角重要性预测网络是一个轻量级的神经网络,可以使用全连接层或卷积层实现。损失函数可以采用交叉熵损失或均方误差损失,用于监督视角重要性得分的预测。在特征融合模块中,可以使用加权平均或注意力机制来实现特征的融合。具体参数设置和网络结构需要根据具体的任务和数据集进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,BFA方法在多个精细操作任务中显著优于现有基线方法,成功率提升了22-46%。例如,在XXX任务上,BFA方法的成功率达到了XX%,而基线方法只有XX%。这些结果表明,BFA方法能够有效地利用多视角信息,提高机器人的操作性能。
🎯 应用场景
该研究成果可广泛应用于需要多视角信息融合的机器人操作任务中,例如:医疗手术机器人、精密仪器装配、自动化生产线等。通过自适应地选择和融合最佳视角特征,可以提高机器人的操作精度和效率,降低对环境光照和遮挡的敏感性,从而实现更智能、更可靠的机器人操作。
📄 摘要(原文)
In real-world scenarios, multi-view cameras are typically employed for fine-grained manipulation tasks. Existing approaches (e.g., ACT) tend to treat multi-view features equally and directly concatenate them for policy learning. However, it will introduce redundant visual information and bring higher computational costs, leading to ineffective manipulation. For a fine-grained manipulation task, it tends to involve multiple stages while the most contributed view for different stages is varied over time. In this paper, we propose a plug-and-play best-feature-aware (BFA) fusion strategy for multi-view manipulation tasks, which is adaptable to various policies. Built upon the visual backbone of the policy network, we design a lightweight network to predict the importance score of each view. Based on the predicted importance scores, the reweighted multi-view features are subsequently fused and input into the end-to-end policy network, enabling seamless integration. Notably, our method demonstrates outstanding performance in fine-grained manipulations. Experimental results show that our approach outperforms multiple baselines by 22-46% success rate on different tasks. Our work provides new insights and inspiration for tackling key challenges in fine-grained manipulations.