Learning to Push, Group, and Grasp: A Diffusion Policy Approach for Multi-Object Delivery
作者: Takahiro Yonemaru, Weiwei Wan, Tatsuki Nishimura, Kensuke Harada
分类: cs.RO
发布日期: 2025-02-12 (更新: 2025-08-01)
💡 一句话要点
提出基于扩散策略的模仿学习方法,解决多物体抓取与放置问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多物体抓取 扩散策略 模仿学习 机器人操作 策略学习
📋 核心要点
- 传统方法难以灵活适应复杂场景下的多物体抓取与放置任务,面临物体分布和机器人硬件约束等挑战。
- 论文提出基于模仿学习的扩散策略网络,通过学习专家演示数据,使机器人能够动态生成动作序列。
- 实验结果表明,该方法在不同训练数据量、物体数量和真实场景下均能有效生成多物体分组和抓取策略。
📝 摘要(中文)
本文提出了一种基于模仿学习的方法,用于解决同时抓取和放置多个物体的问题,旨在提高机器人工作效率。该方法通过远程操作收集专家演示数据,并训练一个扩散策略网络,使机器人能够动态生成推送、分组和抓取动作序列,从而实现高效的多物体抓取和放置。实验结果表明,该方法能够有效地生成多物体分组和抓取策略,并且随着训练数据量的增加,模仿学习有望成为解决多物体抓取问题的有效途径。
🔬 方法详解
问题定义:论文旨在解决机器人同时抓取和放置多个物体的问题。现有基于规则的方法难以适应不同物体分布和机器人硬件约束,缺乏灵活性和泛化能力。因此,需要一种能够根据场景动态生成动作序列的方法,实现高效的多物体抓取和放置。
核心思路:论文的核心思路是利用模仿学习,通过学习专家演示数据,训练一个扩散策略网络。该网络能够根据当前场景状态,预测一系列动作,包括推送、分组和抓取,从而实现多物体的协同操作。这种方法避免了手动设计规则的复杂性,并能够从数据中学习到更优的策略。
技术框架:整体框架包括数据收集和策略学习两个阶段。首先,通过远程操作收集专家演示数据,记录机器人的动作序列和环境状态。然后,利用这些数据训练一个扩散策略网络,该网络以当前状态为输入,输出一系列动作。在推理阶段,机器人根据扩散策略网络生成的动作序列,执行推送、分组和抓取操作。
关键创新:论文的关键创新在于将扩散模型应用于机器人操作策略的学习。扩散模型能够生成多样化的动作序列,从而提高机器人在复杂环境中的适应能力。此外,通过模仿学习,可以有效地利用专家知识,避免了从零开始学习的困难。
关键设计:论文使用扩散模型作为策略网络,具体网络结构未知。损失函数的设计目标是使生成的动作序列尽可能接近专家演示数据。具体的参数设置和训练细节在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片
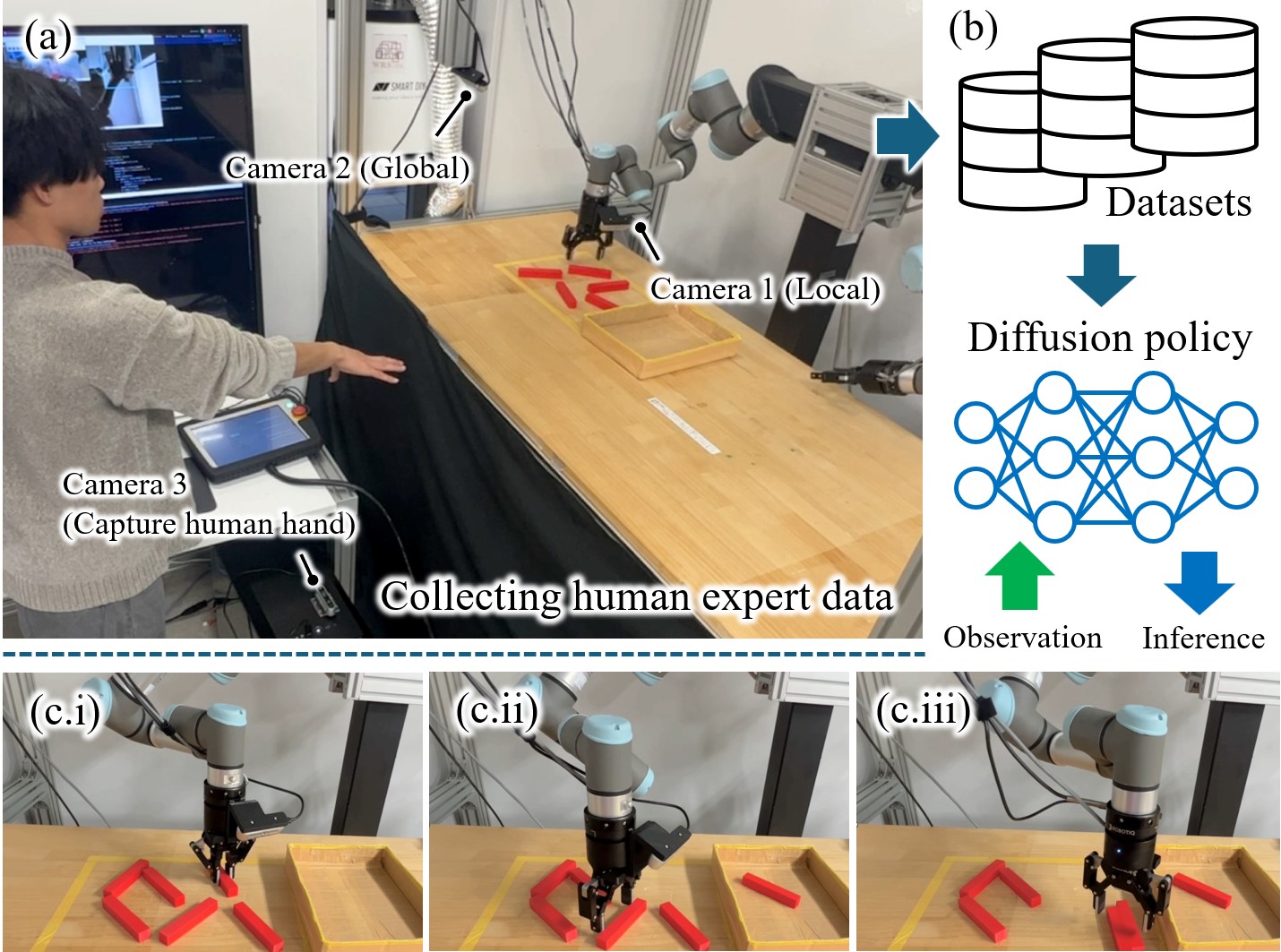
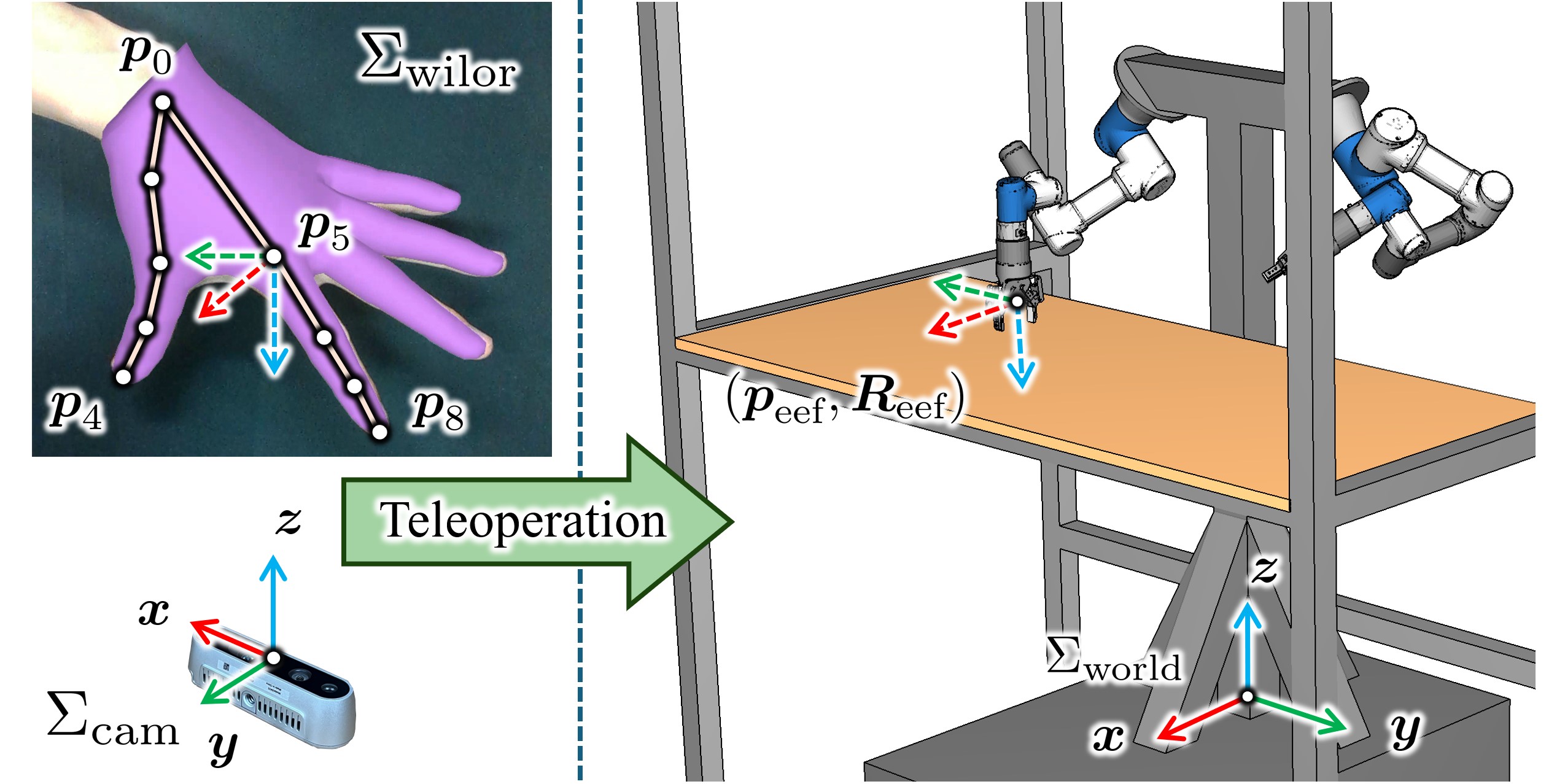

📊 实验亮点
实验结果表明,提出的方法能够有效地生成多物体分组和抓取策略。在不同训练数据量、物体数量和真实场景下均进行了验证,结果显示该方法具有良好的泛化能力。随着训练数据量的增加,性能进一步提升,表明模仿学习在解决多物体抓取问题上的潜力。
🎯 应用场景
该研究成果可应用于自动化仓库、物流分拣、家庭服务机器人等领域。通过提高机器人同时处理多个物体的能力,可以显著提升工作效率,降低人力成本。未来,该技术有望应用于更复杂的场景,例如灾难救援和太空探索等。
📄 摘要(原文)
Simultaneously grasping and delivering multiple objects can significantly enhance robotic work efficiency and has been a key research focus for decades. The primary challenge lies in determining how to push objects, group them, and execute simultaneous grasping for respective groups while considering object distribution and the hardware constraints of the robot. Traditional rule-based methods struggle to flexibly adapt to diverse scenarios. To address this challenge, this paper proposes an imitation learning-based approach. We collect a series of expert demonstrations through teleoperation and train a diffusion policy network, enabling the robot to dynamically generate action sequences for pushing, grouping, and grasping, thereby facilitating efficient multi-object grasping and delivery. We conducted experiments to evaluate the method under different training dataset sizes, varying object quantities, and real-world object scenarios. The results demonstrate that the proposed approach can effectively and adaptively generate multi-object grouping and grasping strategies. With the support of more training data, imitation learning is expected to be an effective approach for solving the multi-object grasping problem.