Reward-Based Collision-Free Algorithm for Trajectory Planning of Autonomous Robots
作者: Jose D. Hoyos, Tianyu Zhou, Zehui Lu, Shaoshuai Mou
分类: cs.RO, eess.SY
发布日期: 2025-02-10 (更新: 2025-05-05)
💡 一句话要点
提出基于奖励的避障轨迹规划算法,用于自主机器人的最优路径选择
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 自主机器人 轨迹规划 遗传算法 奖金收集旅行商问题 差分平坦性 Clothoid曲线 路径优化 避障
📋 核心要点
- 现有轨迹规划方法难以在复杂约束下实现最优路径选择,尤其是在奖励驱动的任务中。
- 该算法结合遗传算法和几何优化,通过奖励函数引导搜索,并使用差分平坦性和clothoid曲线保证轨迹可行性。
- 通过地面车辆、四旋翼飞行器和四足机器人的实验验证了算法的有效性,并进行了基准测试和时间复杂度分析。
📝 摘要(中文)
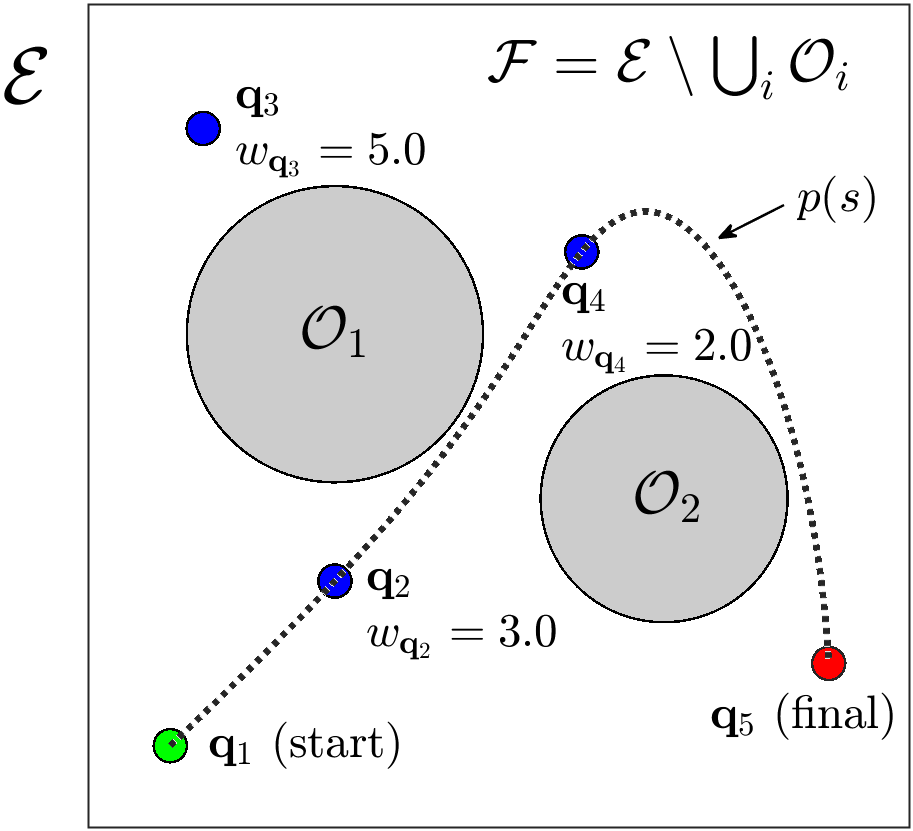
本文提出了一种新颖的自主机器人任务规划算法,该算法从预定义的航路点集合中选择最优序列,以最大化总奖励,同时满足避障、状态、输入、导数、任务时间和距离约束。该公式扩展了奖金收集旅行商问题。定制的遗传算法使用适应度函数、交叉和变异来进化候选解,并通过惩罚方法强制执行约束。差分平坦性和clothoid曲线用于有效地惩罚不可行的轨迹,而欧拉螺旋方法确保具有有界曲率的曲率连续轨迹,从而增强动态可行性并减轻最小加加速度参数化的典型振荡。由于离散变长优化空间,交叉是使用基于动态时间规整的方法和扩展的凸组合与投影来执行的。该算法的性能通过地面车辆、四旋翼飞行器和四足机器人的仿真和实验进行了验证,并辅以基准测试和时间复杂度分析。
🔬 方法详解
问题定义:论文旨在解决自主机器人在复杂约束下,如何从预定义的航路点集合中选择最优路径,以最大化总奖励的问题。现有方法在处理避障、状态约束、输入约束、导数约束、任务时间和距离约束等多种约束时,难以保证轨迹的可行性和最优性,尤其是在奖励驱动的任务场景下。
核心思路:论文的核心思路是将轨迹规划问题建模为奖金收集旅行商问题(Prize-Collecting Traveling Salesman Problem, PCTSP)的扩展,并利用遗传算法进行求解。通过奖励函数引导搜索,鼓励访问高奖励的航路点,同时使用惩罚函数处理各种约束,保证轨迹的可行性。此外,利用差分平坦性和clothoid曲线进行轨迹优化,提高轨迹的平滑性和动态可行性。
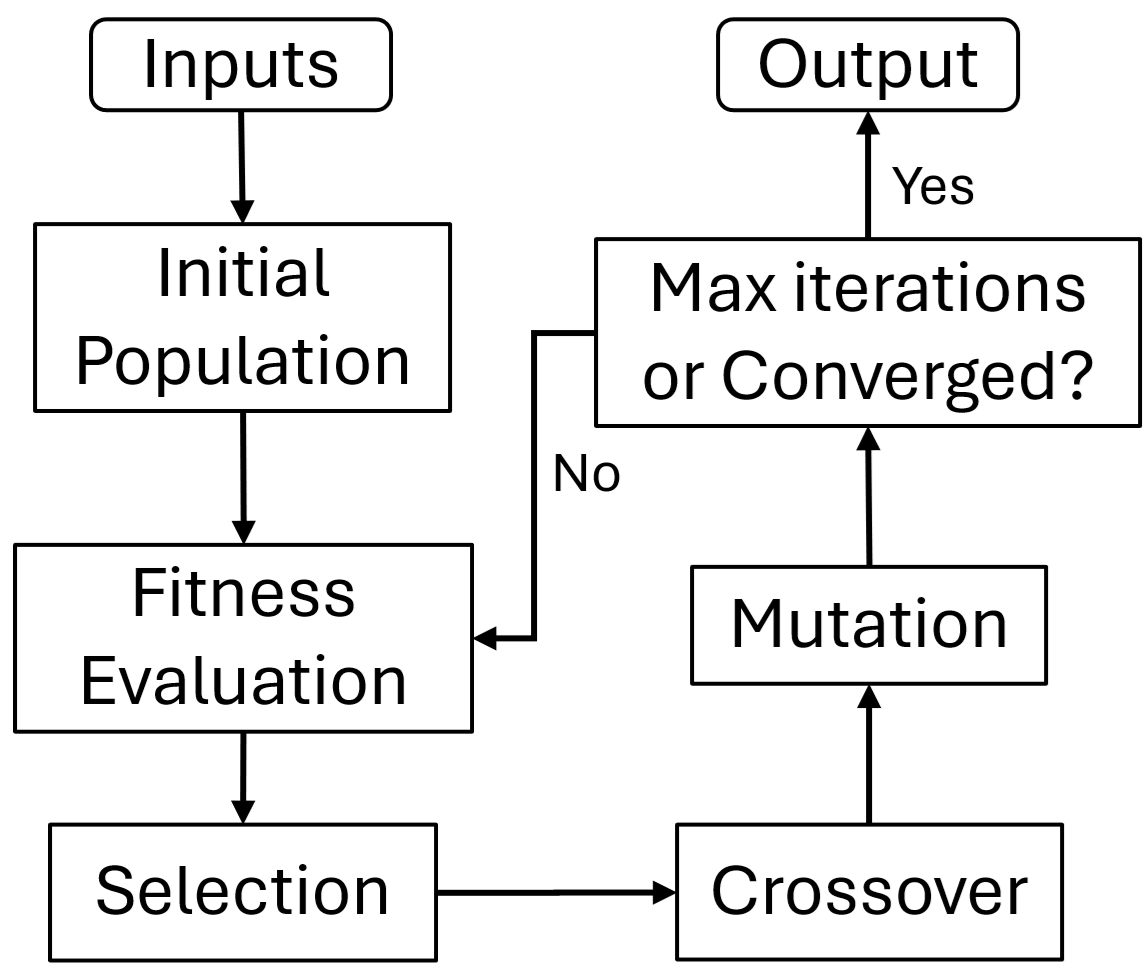
技术框架:该算法的整体框架包括以下几个主要模块:1) 航路点定义和奖励分配;2) 基于遗传算法的路径搜索,包括初始化、选择、交叉和变异等操作;3) 轨迹优化,利用差分平坦性和clothoid曲线生成平滑轨迹;4) 约束检查和惩罚,对不满足约束的轨迹施加惩罚;5) 评估和选择,根据奖励和惩罚选择最优路径。
关键创新:该论文的关键创新点在于:1) 将轨迹规划问题建模为扩展的PCTSP,能够有效处理奖励驱动的任务;2) 结合遗传算法和几何优化,实现全局搜索和局部优化的结合;3) 利用差分平坦性和clothoid曲线保证轨迹的平滑性和动态可行性;4) 提出了一种基于动态时间规整的交叉方法,适用于离散变长优化空间。
关键设计:在遗传算法中,适应度函数的设计至关重要,它综合考虑了奖励、约束惩罚和轨迹长度等因素。交叉操作采用基于动态时间规整的方法,以适应变长路径的特点。约束惩罚采用自适应策略,根据违反约束的程度动态调整惩罚力度。clothoid曲线的参数选择需要仔细调整,以保证轨迹的平滑性和曲率连续性。
🖼️ 关键图片

📊 实验亮点
通过地面车辆、四旋翼飞行器和四足机器人的仿真和实验验证了算法的有效性。实验结果表明,该算法能够在复杂环境中找到最优路径,并生成满足各种约束的平滑轨迹。与传统方法相比,该算法能够显著提高任务奖励,并降低轨迹的振荡。
🎯 应用场景
该研究成果可应用于多种自主机器人任务,如无人机物流配送、自动驾驶车辆路径规划、机器人巡检等。通过最大化任务奖励,同时满足各种约束,可以提高机器人的工作效率和安全性。未来,该算法可以进一步扩展到多机器人协同任务,实现更复杂的任务规划。
📄 摘要(原文)
This paper proposes a novel mission planning algorithm for autonomous robots that selects an optimal waypoint sequence from a predefined set to maximize total reward while satisfying obstacle avoidance, state, input, derivative, mission time, and distance constraints. The formulation extends the prize-collecting traveling salesman problem. A tailored genetic algorithm evolves candidate solutions using a fitness function, crossover, and mutation, with constraint enforcement via a penalty method. Differential flatness and clothoid curves are employed to penalize infeasible trajectories efficiently, while the Euler spiral method ensures curvature-continuous trajectories with bounded curvature, enhancing dynamic feasibility and mitigating oscillations typical of minimum-jerk and snap parameterizations. Due to the discrete variable length optimization space, crossover is performed using a dynamic time-warping-based method and extended convex combination with projection. The algorithm's performance is validated through simulations and experiments with a ground vehicle, quadrotor, and quadruped, supported by benchmarking and time-complexity analysis.