Data efficient Robotic Object Throwing with Model-Based Reinforcement Learning
作者: Niccolò Turcato, Giulio Giacomuzzo, Matteo Terreran, Davide Allegro, Ruggero Carli, Alberto Dalla Libera
分类: cs.RO
发布日期: 2025-02-08
备注: Preprint under review
💡 一句话要点
提出MC-PILOT,一种基于模型的强化学习方法,用于数据高效的机器人投掷任务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人投掷 模型预测控制 强化学习 数据高效 动力学建模
📋 核心要点
- 现有Pick-and-Place方法受限于工作空间,而Pick-and-Throw虽然潜力巨大,但其高动态性和复杂性带来了挑战。
- MC-PILOT结合了数据驱动建模和策略优化,通过基于模型的强化学习,实现了高效且精确的机器人投掷任务。
- 实验表明,MC-PILOT在仿真和真实环境中均表现出色,能够快速适应新目标,优于传统解析方法和无模型强化学习。
📝 摘要(中文)
本文提出了一种基于模型的强化学习(MBRL)框架MC-PILOT,用于高效且精确的机器人投掷(PnT)任务。拣选放置(PnP)操作是工业机器人应用的基础,但受到工作空间限制。PnT是一种有前景的替代方案,它利用重力等外部资源来提高效率和扩展工作空间。然而,PnT执行复杂,需要精确协调高速运动和物体动力学。现有的PnT解决方案分为解析方法和基于学习的方法。解析方法侧重于系统建模和轨迹生成,但耗时且泛化能力有限。基于学习的解决方案,特别是无模型强化学习(MFRL),提供了自动化和适应性,但需要大量的交互时间。MC-PILOT考虑了模型不确定性和释放误差,在Franka Emika Panda机械臂的仿真和真实测试中表现出卓越的性能。该方法能够快速泛化到新的目标,优于解析方法和无模型方法。
🔬 方法详解
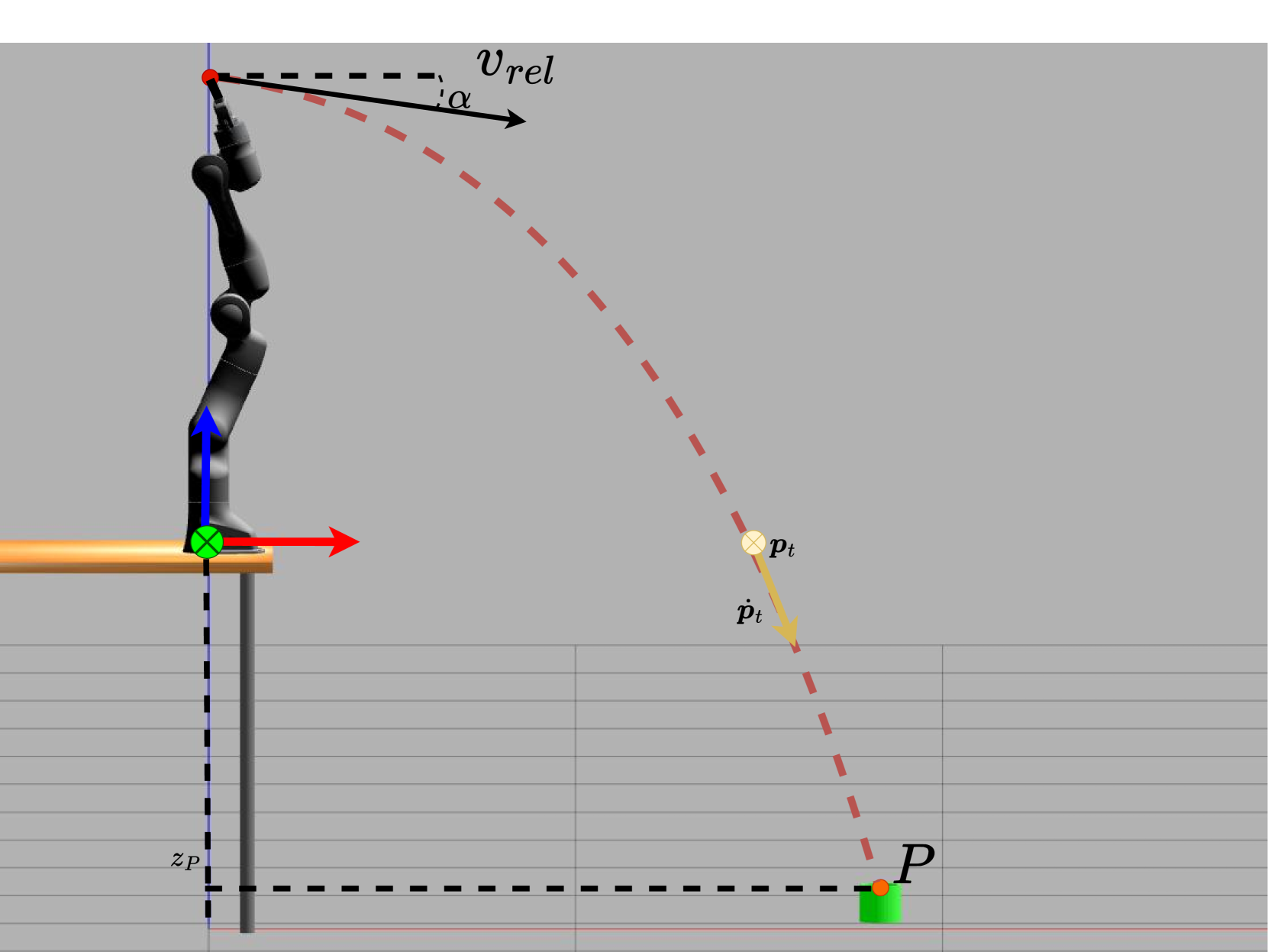
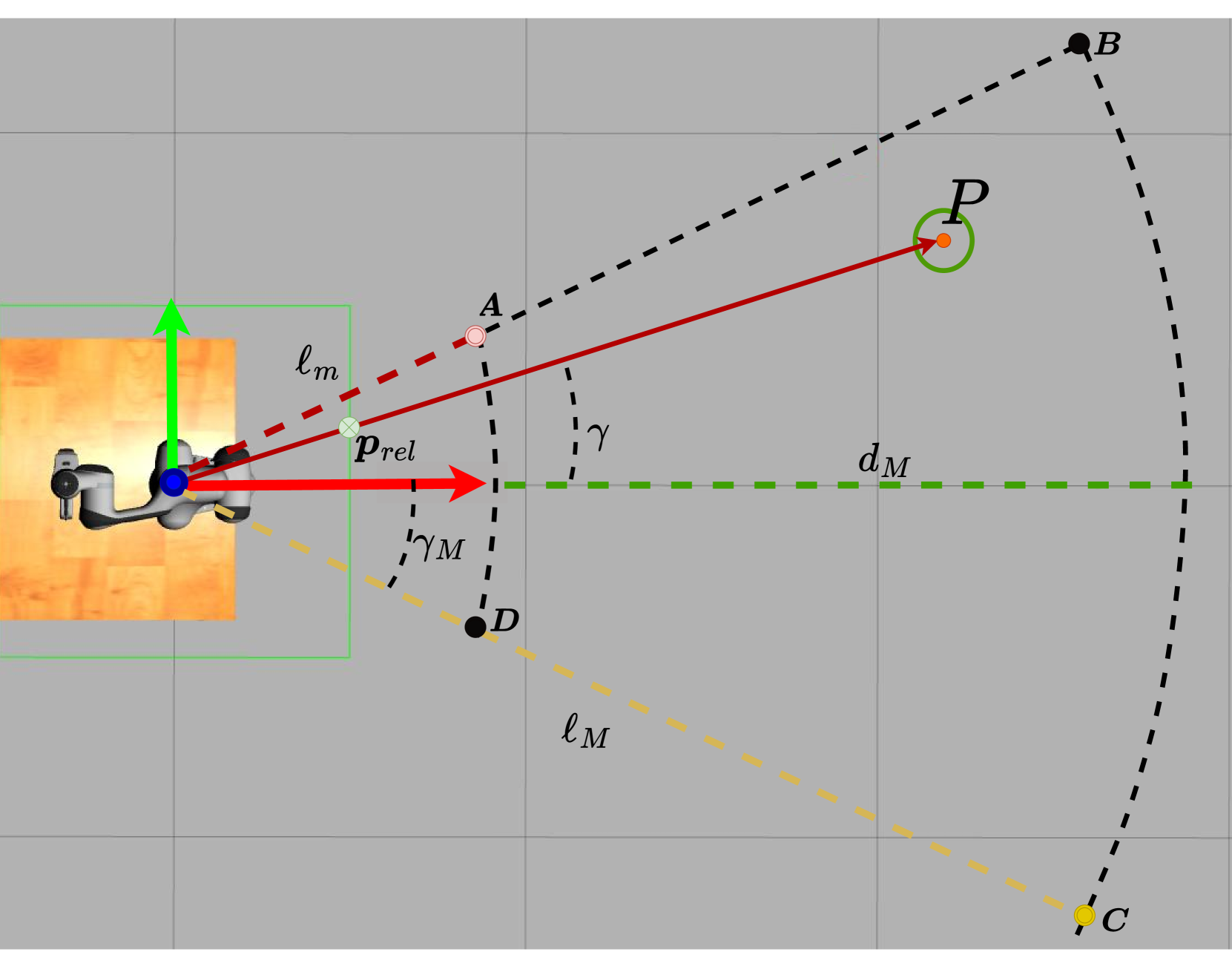
问题定义:论文旨在解决机器人投掷物体到目标位置的问题(Pick-and-Throw, PnT)。现有解析方法建模复杂、泛化性差,无模型强化学习方法需要大量数据进行训练,效率低下。因此,如何在数据有限的情况下,实现高效、精确且泛化能力强的机器人投掷成为关键问题。
核心思路:论文的核心思路是利用基于模型的强化学习(MBRL),结合数据驱动的动力学模型学习和策略优化,从而在少量数据下学习到有效的投掷策略。通过对环境进行建模,可以减少对大量真实世界交互数据的依赖,提高学习效率。
技术框架:MC-PILOT框架包含以下主要模块:1) 数据收集:通过少量真实或仿真环境交互收集数据;2) 动力学模型学习:利用收集到的数据学习一个预测物体运动的动力学模型;3) 策略优化:使用学习到的动力学模型,通过模型预测控制(MPC)或策略梯度等方法优化投掷策略;4) 策略执行:将优化后的策略部署到真实机器人上执行投掷任务。
关键创新:该方法的核心创新在于将模型预测控制(MPC)与强化学习相结合,利用学习到的动力学模型进行策略优化,从而在数据效率上优于传统的无模型强化学习方法。此外,该方法还考虑了模型的不确定性和释放误差,提高了鲁棒性。
关键设计:论文中可能涉及的关键设计包括:1) 动力学模型的选择(例如高斯过程、神经网络等);2) 模型预测控制器的设计(例如预测步长、控制频率等);3) 奖励函数的设计(例如目标距离、能量消耗等);4) 模型不确定性的建模方法(例如使用集成模型、贝叶斯方法等)。具体参数设置和网络结构等细节需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
论文提出的MC-PILOT方法在仿真和真实机器人实验中均取得了显著成果。相较于传统的解析方法和无模型强化学习方法,MC-PILOT在数据效率和泛化能力方面表现更优。具体性能数据(例如成功率、误差范围等)需要在论文中查找。
🎯 应用场景
该研究成果可应用于自动化装配、物流分拣、危险品处理等领域。通过机器人投掷,可以扩展机器人的工作空间,提高生产效率,并降低人工操作的风险。未来,该技术有望应用于更复杂的场景,例如在非结构化环境中进行目标投掷。
📄 摘要(原文)
Pick-and-place (PnP) operations, featuring object grasping and trajectory planning, are fundamental in industrial robotics applications. Despite many advancements in the field, PnP is limited by workspace constraints, reducing flexibility. Pick-and-throw (PnT) is a promising alternative where the robot throws objects to target locations, leveraging extrinsic resources like gravity to improve efficiency and expand the workspace. However, PnT execution is complex, requiring precise coordination of high-speed movements and object dynamics. Solutions to the PnT problem are categorized into analytical and learning-based approaches. Analytical methods focus on system modeling and trajectory generation but are time-consuming and offer limited generalization. Learning-based solutions, in particular Model-Free Reinforcement Learning (MFRL), offer automation and adaptability but require extensive interaction time. This paper introduces a Model-Based Reinforcement Learning (MBRL) framework, MC-PILOT, which combines data-driven modeling with policy optimization for efficient and accurate PnT tasks. MC-PILOT accounts for model uncertainties and release errors, demonstrating superior performance in simulations and real-world tests with a Franka Emika Panda manipulator. The proposed approach generalizes rapidly to new targets, offering advantages over analytical and Model-Free methods.