Training-free Task-oriented Grasp Generation
作者: Jiaming Wang, Diwen Liu, Jizhuo Chen, Harold Soh
分类: cs.RO
发布日期: 2025-02-07 (更新: 2025-10-05)
备注: Jiaming Wang, Diwen Liu, and Jizhuo Chen contributed equally
💡 一句话要点
提出一种免训练的面向任务抓取生成方法,结合预训练模型与视觉语言模型。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人抓取 视觉语言模型 任务导向 免训练 人机交互
📋 核心要点
- 现有抓取生成方法主要关注抓取的稳定性,忽略了任务的特定需求,限制了其在复杂场景中的应用。
- 该方法利用视觉语言模型(VLMs)的语义推理能力,将任务需求融入抓取生成过程,无需额外训练。
- 实验结果表明,该方法在抓取成功率和任务依从率方面均优于基线方法,总体成功率提升显著。
📝 摘要(中文)
本文提出了一种免训练的面向任务抓取生成流程,该流程结合了预训练抓取生成模型与视觉语言模型(VLMs)。与传统方法仅关注稳定抓取不同,我们的方法通过利用VLMs的语义推理能力,整合了特定任务的需求。我们评估了五种查询策略,每种策略都利用了候选抓取的不同视觉表示,并证明了相对于基线方法,在抓取成功率和任务依从率方面都有显著提高,总体成功率绝对提升高达36.9%。我们的结果强调了VLMs在增强面向任务操作方面的潜力,为机器人抓取和人机交互的未来研究提供了见解。
🔬 方法详解
问题定义:论文旨在解决机器人抓取任务中,传统方法仅关注抓取稳定性而忽略任务特定需求的问题。现有方法的痛点在于,生成的抓取姿态可能稳定,但并不一定能完成用户指定的任务,例如“拿起红色的苹果”或“将物体放入盒子中”。
核心思路:论文的核心思路是利用视觉语言模型(VLMs)的强大语义理解能力,将任务描述融入到抓取生成过程中。通过VLMs对候选抓取姿态进行评估,选择最符合任务描述的抓取姿态。这样可以在保证抓取稳定性的同时,最大程度地满足任务需求。
技术框架:整体流程包括以下几个主要步骤:1. 使用预训练的抓取生成模型生成多个候选抓取姿态。2. 将每个候选抓取姿态的视觉表示(例如,抓取前后的图像、深度图等)输入到视觉语言模型中。3. 使用自然语言描述任务需求,例如“拿起红色的苹果”。4. VLM根据视觉表示和任务描述,对每个候选抓取姿态进行评分,评估其完成任务的可能性。5. 选择得分最高的抓取姿态作为最终的抓取方案。
关键创新:最重要的技术创新点在于将视觉语言模型引入到抓取生成流程中,实现了任务驱动的抓取。与传统方法相比,该方法不再仅仅关注抓取的稳定性,而是更加关注抓取姿态是否能够完成特定的任务。这种方法可以显著提高机器人在复杂场景中的操作能力。
关键设计:论文评估了五种不同的查询策略,这些策略使用不同的视觉表示作为VLM的输入。这些视觉表示包括:抓取前的场景图像、抓取后的场景图像、抓取姿态的深度图等。论文还研究了不同的VLM模型对抓取性能的影响。此外,论文还设计了一种新的评估指标,用于衡量抓取姿态的任务依从性。
🖼️ 关键图片


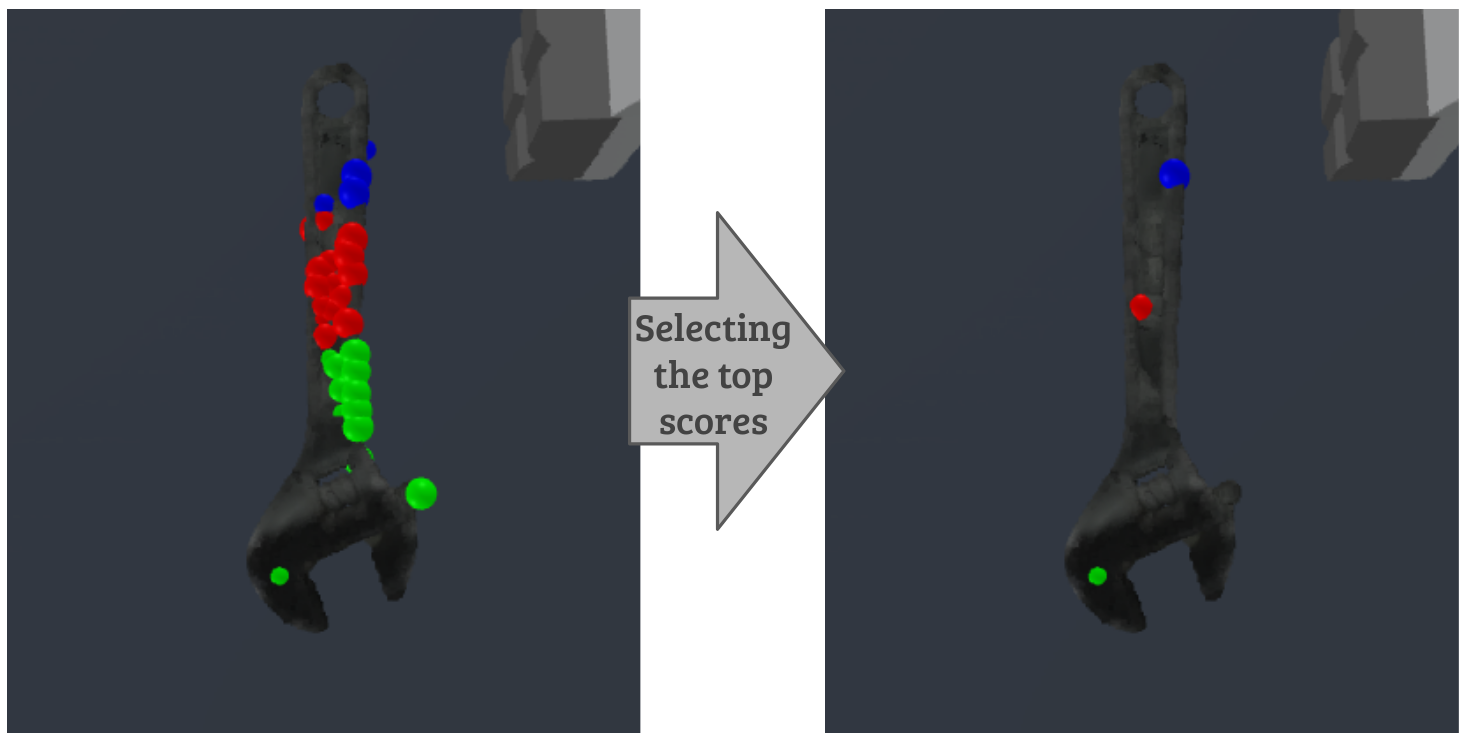
📊 实验亮点
实验结果表明,该方法在抓取成功率和任务依从率方面均优于基线方法。具体而言,总体成功率绝对提升高达36.9%。这表明,利用视觉语言模型可以显著提高机器人在复杂场景中的抓取性能。此外,实验还评估了不同查询策略和VLM模型对抓取性能的影响,为未来的研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于各种需要任务导向抓取的机器人应用场景,例如:智能仓储、家庭服务机器人、工业自动化等。通过结合视觉语言模型,机器人可以更好地理解人类指令,并执行更加复杂的抓取任务。未来,该技术有望推动人机协作的进一步发展,使机器人能够更好地服务于人类。
📄 摘要(原文)
This paper presents a training-free pipeline for task-oriented grasp generation that combines pre-trained grasp generation models with vision-language models (VLMs). Unlike traditional approaches that focus solely on stable grasps, our method incorporates task-specific requirements by leveraging the semantic reasoning capabilities of VLMs. We evaluate five querying strategies, each utilizing different visual representations of candidate grasps, and demonstrate significant improvements over a baseline method in both grasp success and task compliance rates, with absolute gains of up to 36.9\% in overall success rate. Our results underline the potential of VLMs to enhance task-oriented manipulation, providing insights for future research in robotic grasping and human-robot interaction.