STRIDE: Automating Reward Design, Deep Reinforcement Learning Training and Feedback Optimization in Humanoid Robotics Locomotion
作者: Zhenwei Wu, Jinxiong Lu, Yuxiao Chen, Yunxin Liu, Yueting Zhuang, Luhui Hu
分类: cs.RO, cs.LG
发布日期: 2025-02-07 (更新: 2025-02-12)
💡 一句话要点
STRIDE:自动化人形机器人运动控制中奖励函数设计与深度强化学习训练
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人形机器人 深度强化学习 奖励函数设计 自动化 大型语言模型
📋 核心要点
- 人形机器人运动控制的奖励函数设计依赖人工,耗时且需要专家知识,是深度强化学习应用的瓶颈。
- STRIDE框架结合智能体工程和大型语言模型,自动化奖励函数的设计、评估和迭代优化过程,无需特定任务的模板。
- 实验表明,STRIDE在不同机器人形态和复杂地形下,性能超越现有方法EUREKA,效率和任务性能平均提升250%。
📝 摘要(中文)
人形机器人控制是人工智能领域的一大挑战,需要对高自由度系统进行精确的协调和控制。为深度强化学习(DRL)设计有效的奖励函数仍然是一个关键瓶颈,需要大量的人工、领域专业知识和迭代改进。为了克服这些挑战,我们引入了STRIDE,这是一个建立在智能体工程上的新框架,用于自动化人形机器人运动任务的奖励设计、DRL训练和反馈优化。通过将智能体工程的结构化原则与大型语言模型(LLM)的代码编写、零样本生成和上下文优化相结合,STRIDE生成、评估和迭代改进奖励函数,而无需依赖于特定任务的提示或模板。在具有不同人形机器人形态的各种环境中,STRIDE优于最先进的奖励设计框架EUREKA,在效率和任务性能方面平均提高了约250%。使用STRIDE生成的奖励,模拟的人形机器人可以在复杂地形上实现冲刺级别的运动,突出了其推进DRL工作流程和人形机器人研究的能力。
🔬 方法详解
问题定义:人形机器人运动控制中的奖励函数设计是一个复杂且耗时的过程。传统方法依赖于人工设计,需要大量的领域知识和反复试验,难以适应不同的机器人形态和环境。现有的自动化奖励设计方法,如EUREKA,仍然需要任务特定的提示或模板,限制了其泛化能力。
核心思路:STRIDE的核心思路是利用智能体工程的结构化原则和大型语言模型(LLM)的强大能力,构建一个能够自主生成、评估和优化奖励函数的框架。通过将奖励函数设计视为一个智能体任务,STRIDE可以自动探索奖励函数空间,并根据性能反馈进行迭代改进。
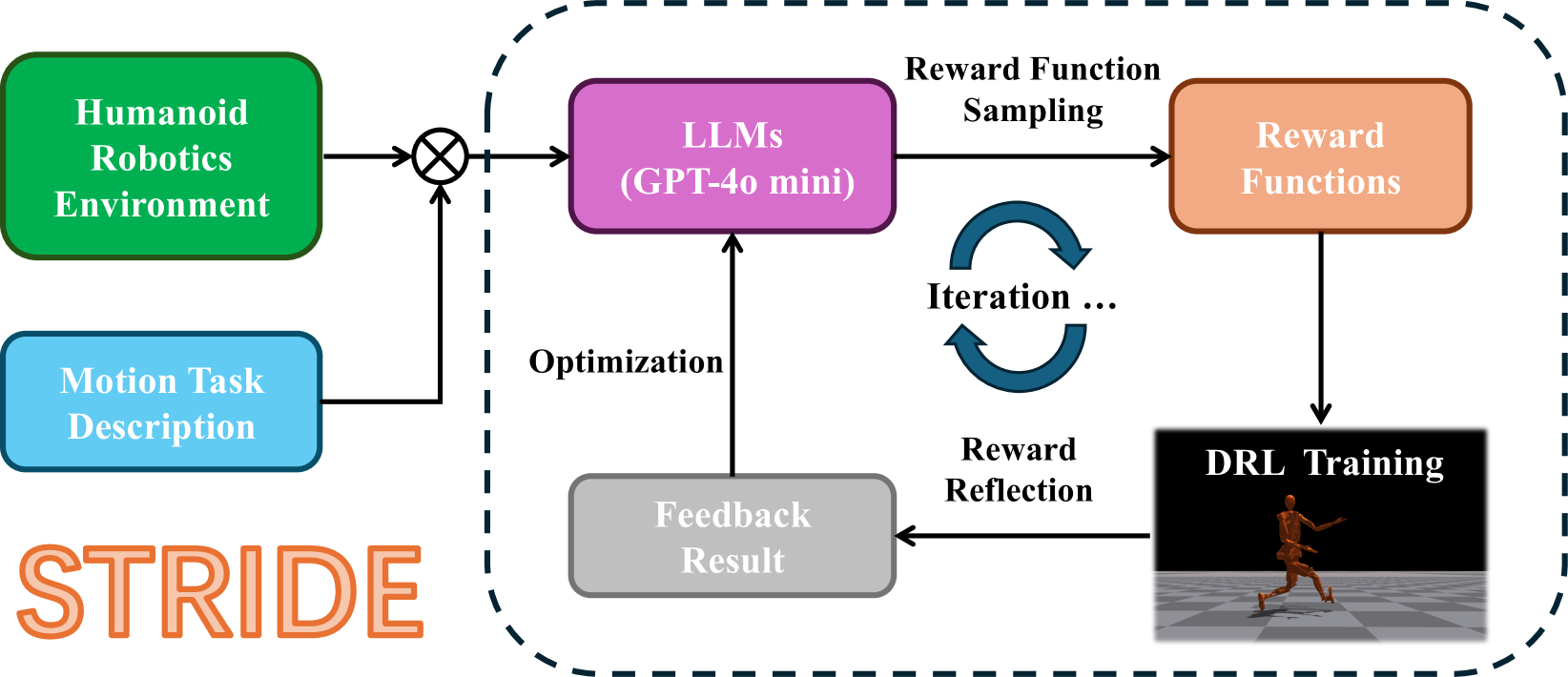
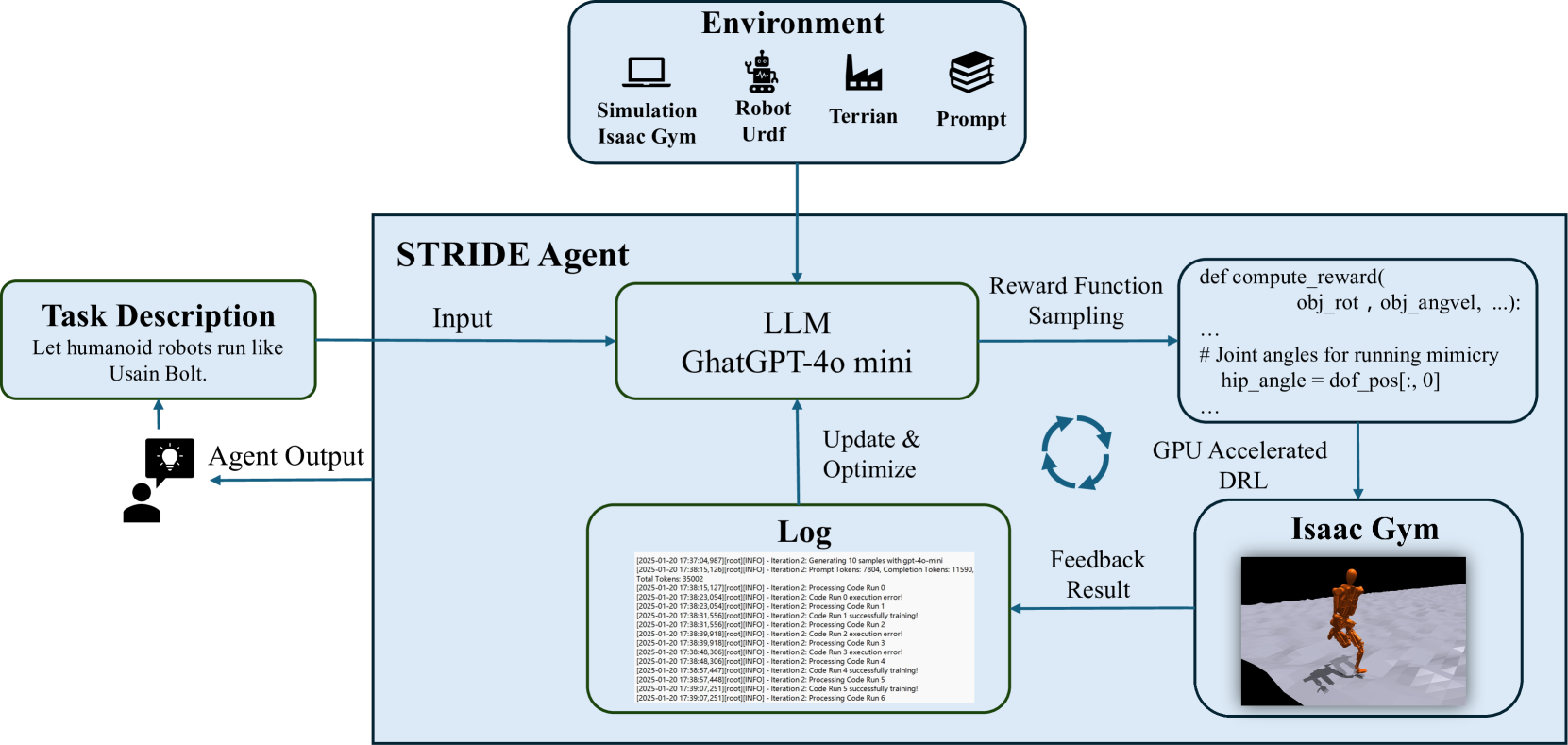
技术框架:STRIDE框架包含以下主要模块:1) 奖励函数生成器:利用LLM生成候选奖励函数;2) 奖励函数评估器:使用DRL训练智能体,评估候选奖励函数的性能;3) 反馈优化器:根据评估结果,利用LLM优化奖励函数,生成新的候选奖励函数。整个过程迭代进行,直到找到满足性能要求的奖励函数。
关键创新:STRIDE的关键创新在于将智能体工程和LLM相结合,实现奖励函数的自动化设计。与现有方法相比,STRIDE无需任务特定的提示或模板,具有更强的泛化能力。此外,STRIDE利用LLM进行代码编写、零样本生成和上下文优化,提高了奖励函数设计的效率和质量。
关键设计:STRIDE使用LLM(具体型号未知)作为奖励函数生成器和反馈优化器。奖励函数评估器使用常见的DRL算法(具体算法未知)进行训练。框架的关键参数包括LLM的提示策略、DRL算法的超参数以及迭代次数等。损失函数的设计目标是最大化机器人的运动速度、稳定性以及能量效率(具体公式未知)。网络结构方面,奖励函数通常被设计为输入机器人状态,输出奖励值的神经网络(具体结构未知)。
🖼️ 关键图片
📊 实验亮点
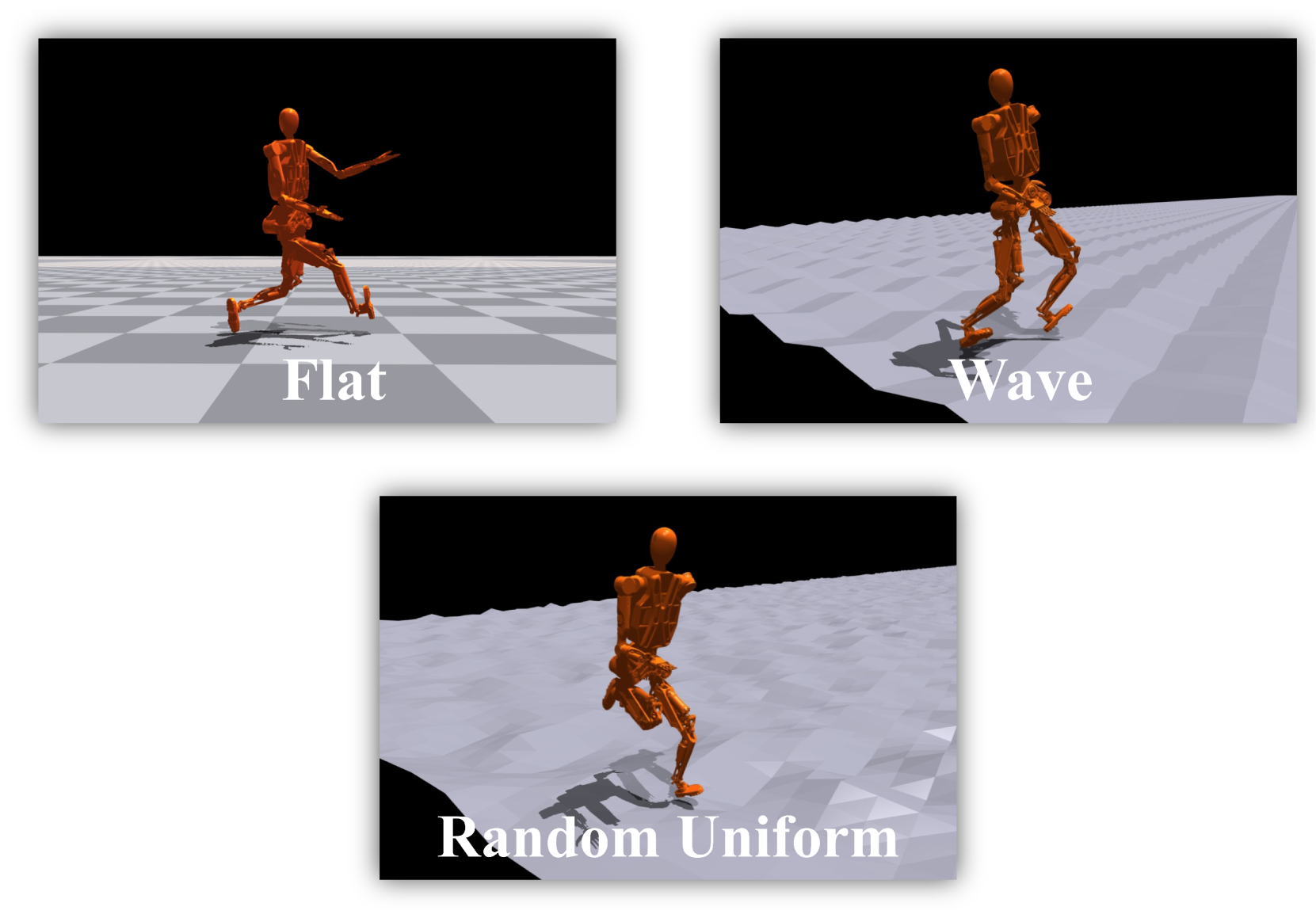
STRIDE在各种人形机器人形态和复杂地形下进行了实验,结果表明STRIDE优于最先进的奖励设计框架EUREKA,在效率和任务性能方面平均提高了约250%。使用STRIDE生成的奖励,模拟的人形机器人可以在复杂地形上实现冲刺级别的运动,证明了其有效性。
🎯 应用场景
STRIDE框架可应用于各种人形机器人运动控制任务,例如行走、跑步、跳跃和攀爬。该框架还可以扩展到其他机器人类型和控制任务,例如四足机器人、无人机和机械臂。STRIDE的自动化奖励设计能力可以显著降低机器人控制系统的开发成本和时间,加速机器人技术的应用。
📄 摘要(原文)
Humanoid robotics presents significant challenges in artificial intelligence, requiring precise coordination and control of high-degree-of-freedom systems. Designing effective reward functions for deep reinforcement learning (DRL) in this domain remains a critical bottleneck, demanding extensive manual effort, domain expertise, and iterative refinement. To overcome these challenges, we introduce STRIDE, a novel framework built on agentic engineering to automate reward design, DRL training, and feedback optimization for humanoid robot locomotion tasks. By combining the structured principles of agentic engineering with large language models (LLMs) for code-writing, zero-shot generation, and in-context optimization, STRIDE generates, evaluates, and iteratively refines reward functions without relying on task-specific prompts or templates. Across diverse environments featuring humanoid robot morphologies, STRIDE outperforms the state-of-the-art reward design framework EUREKA, achieving an average improvement of round 250% in efficiency and task performance. Using STRIDE-generated rewards, simulated humanoid robots achieve sprint-level locomotion across complex terrains, highlighting its ability to advance DRL workflows and humanoid robotics research.