AnyPlace: Learning Generalized Object Placement for Robot Manipulation
作者: Yuchi Zhao, Miroslav Bogdanovic, Chengyuan Luo, Steven Tohme, Kourosh Darvish, Alán Aspuru-Guzik, Florian Shkurti, Animesh Garg
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-02-06 (更新: 2025-09-24)
备注: Accepted at CoRL 2025
💡 一句话要点
AnyPlace:学习通用物体放置,提升机器人操作能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人操作 物体放置 视觉-语言模型 合成数据 迁移学习 姿势预测 通用机器人
📋 核心要点
- 机器人操作中的物体放置因物体几何形状和放置配置的多样性而极具挑战性。
- AnyPlace利用视觉-语言模型确定粗略位置,聚焦局部区域,高效训练低级姿势预测模型。
- 实验表明,AnyPlace在仿真和真实环境中均优于基线,尤其在复杂场景下表现出色。
📝 摘要(中文)
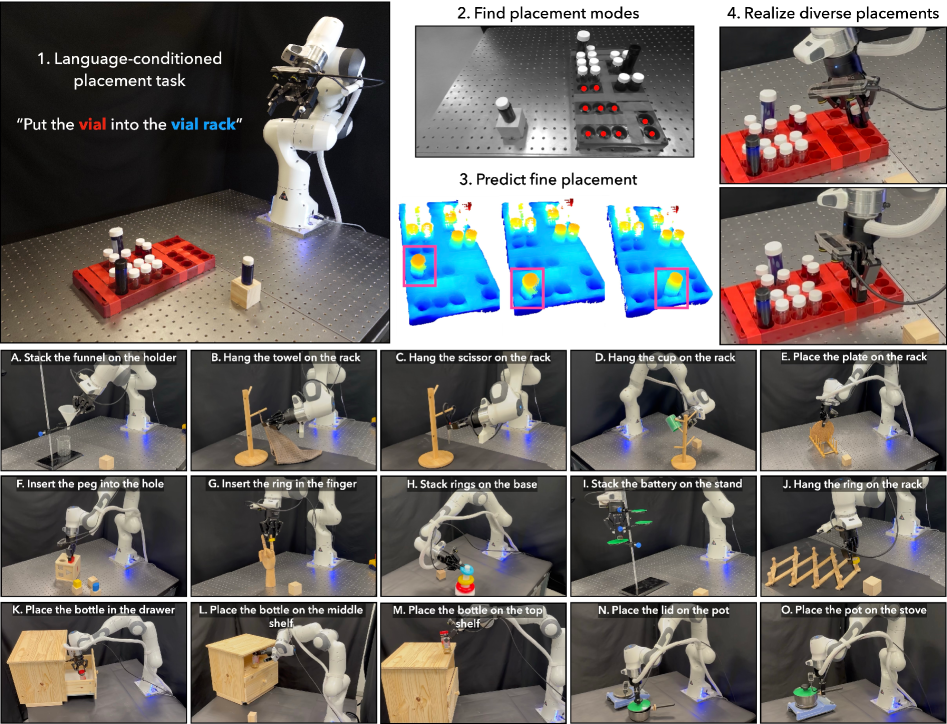
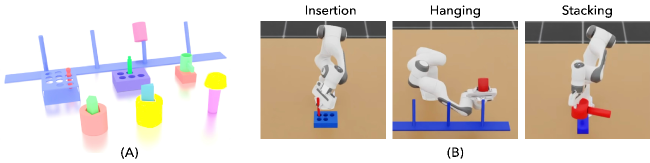
本文提出了一种名为AnyPlace的两阶段方法,用于解决机器人操作中物体放置的挑战。该方法完全在合成数据上训练,能够预测真实世界任务中各种可行的放置姿势。核心思想是利用视觉-语言模型(VLM)识别粗略的放置位置,从而将重点放在局部放置的相关区域,使得低级放置姿势预测模型能够有效地捕获各种放置方式。通过生成包含不同放置配置(插入、堆叠、悬挂)的随机生成物体的合成数据集来训练局部放置预测模型。在仿真和真实世界的实验中,证明了该方法在成功率、可能放置模式的覆盖率和精度方面优于基线方法,并且能够直接将纯粹在合成数据上训练的模型迁移到真实世界,成功地执行其他模型难以处理的放置任务,例如具有不同物体几何形状、多样化放置模式以及需要高精度精细放置的场景。
🔬 方法详解
问题定义:机器人操作中的物体放置任务,由于物体形状各异、放置方式多样,现有方法难以泛化到各种场景。尤其是在真实世界中,物体几何形状的复杂性和放置配置的多样性给机器人精确放置带来了挑战。现有方法通常难以同时处理多种放置模式,并且在精度方面存在不足。
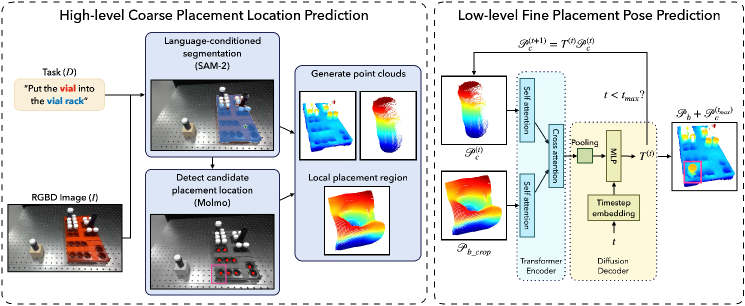
核心思路:AnyPlace的核心思路是将物体放置任务分解为两个阶段:首先,利用视觉-语言模型(VLM)识别物体大致的放置位置;然后,针对该局部区域,训练一个低级的放置姿势预测模型,以精确预测物体的放置姿势。通过这种两阶段的方法,可以有效地缩小搜索空间,并使模型能够专注于局部区域的精细化放置。
技术框架:AnyPlace包含两个主要阶段:1) 粗略位置识别:使用视觉-语言模型(VLM)来识别物体大致的放置位置。VLM接收场景图像和描述放置指令的文本作为输入,输出一个粗略的放置区域。2) 精细姿势预测:基于VLM提供的粗略位置,训练一个低级的放置姿势预测模型,该模型接收局部区域的图像作为输入,输出精确的物体放置姿势。这两个阶段共同完成物体放置任务。
关键创新:AnyPlace的关键创新在于利用视觉-语言模型来引导局部放置姿势的预测。通过VLM,模型可以理解放置指令,并根据场景信息确定大致的放置位置,从而缩小了搜索空间,提高了放置的效率和精度。此外,AnyPlace完全在合成数据上进行训练,并通过有效的训练策略,实现了从合成数据到真实世界的迁移。
关键设计:AnyPlace的关键设计包括:1) 合成数据生成:生成包含各种物体几何形状和放置配置(插入、堆叠、悬挂等)的合成数据集,用于训练放置姿势预测模型。2) 视觉-语言模型选择:选择合适的VLM,并对其进行微调,以适应物体放置任务的需求。3) 损失函数设计:设计合适的损失函数,以优化放置姿势预测模型的性能,例如,可以使用Chamfer Distance或Earth Mover's Distance来衡量预测姿势与目标姿势之间的差异。4) 网络结构设计:设计合适的网络结构,以有效地提取局部区域的特征,并预测精确的物体放置姿势。
🖼️ 关键图片
📊 实验亮点
AnyPlace在仿真和真实世界的实验中均取得了显著的成果。在仿真实验中,AnyPlace在成功率、可能放置模式的覆盖率和精度方面均优于基线方法。在真实世界的实验中,AnyPlace成功地将纯粹在合成数据上训练的模型迁移到真实世界,并在各种复杂场景下实现了精确的物体放置,例如具有不同物体几何形状、多样化放置模式以及需要高精度精细放置的场景。这些实验结果表明,AnyPlace具有很强的泛化能力和鲁棒性。
🎯 应用场景
AnyPlace具有广泛的应用前景,可应用于自动化装配、仓储物流、家庭服务机器人等领域。例如,在自动化装配中,机器人可以利用AnyPlace精确地将零件放置到指定位置;在仓储物流中,机器人可以利用AnyPlace高效地进行货物堆叠和整理;在家庭服务机器人中,机器人可以利用AnyPlace帮助人们整理物品、放置物品等。该研究的实际价值在于提高了机器人操作的智能化水平和泛化能力,为实现更高效、更灵活的机器人应用奠定了基础。
📄 摘要(原文)
Object placement in robotic tasks is inherently challenging due to the diversity of object geometries and placement configurations. To address this, we propose AnyPlace, a two-stage method trained entirely on synthetic data, capable of predicting a wide range of feasible placement poses for real-world tasks. Our key insight is that by leveraging a Vision-Language Model (VLM) to identify rough placement locations, we focus only on the relevant regions for local placement, which enables us to train the low-level placement-pose-prediction model to capture diverse placements efficiently. For training, we generate a fully synthetic dataset of randomly generated objects in different placement configurations (insertion, stacking, hanging) and train local placement-prediction models. We conduct extensive evaluations in simulation, demonstrating that our method outperforms baselines in terms of success rate, coverage of possible placement modes, and precision. In real-world experiments, we show how our approach directly transfers models trained purely on synthetic data to the real world, where it successfully performs placements in scenarios where other models struggle -- such as with varying object geometries, diverse placement modes, and achieving high precision for fine placement. More at: https://any-place.github.io.