The Temporal Trap: Entanglement in Pre-Trained Visual Representations for Visuomotor Policy Learning
作者: Nikolaos Tsagkas, Andreas Sochopoulos, Duolikun Danier, Chris Xiaoxuan Lu, Oisin Mac Aodha
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-02-05 (更新: 2025-11-13)
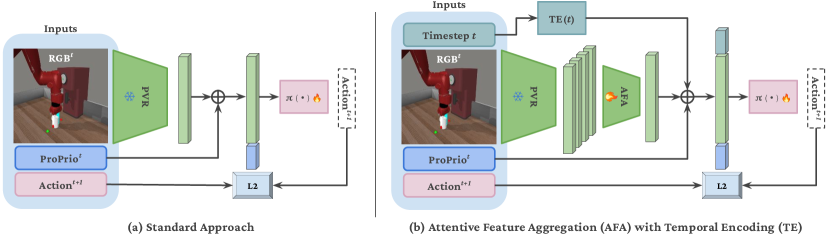
备注: This submission replaces our earlier work "When Pre-trained Visual Representations Fall Short: Limitations in Visuo-Motor Robot Learning." The original paper was split into two studies; this version focuses on temporal entanglement in pre-trained visual representations. The companion paper is "Attentive Feature Aggregation."
💡 一句话要点
针对视觉运动策略学习,提出解耦预训练视觉表征时序纠缠的方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉运动策略学习 预训练视觉表征 时间纠缠 时间解耦 序列决策 机器人控制 强化学习
📋 核心要点
- 现有预训练视觉表征(PVRs)在视觉运动策略学习中存在时间纠缠问题,阻碍了策略有效利用时序信息。
- 论文提出一种解耦基线,旨在缓解PVRs中的时间纠缠,从而提升策略学习的性能。
- 实验结果表明,仅通过时间组件丰富特征是不够的,明确的时间解耦对于鲁棒的视觉运动策略学习至关重要。
📝 摘要(中文)
预训练视觉表征(PVRs)的集成显著推进了视觉运动策略学习。然而,如何有效地利用这些模型仍然是一个挑战。我们发现时间纠缠是使用这些时间不变模型在序列决策任务中一个关键的、固有的问题。这种纠缠的产生是因为PVRs针对静态图像理解进行了优化,难以表示对视觉运动控制至关重要的时间依赖性。在这项工作中,我们量化了时间纠缠的影响,证明了策略的成功率与其潜在空间捕获任务进展线索的能力之间存在很强的相关性。基于这些见解,我们提出了一种简单而有效的解耦基线,旨在减轻时间纠缠。我们的实验结果表明,旨在用时间分量丰富特征的传统方法本身是不够的,突出了明确解决时间解耦对于鲁棒的视觉运动策略学习的必要性。
🔬 方法详解
问题定义:论文旨在解决视觉运动策略学习中,预训练视觉表征(PVRs)由于其时间不变性而导致的时间纠缠问题。现有方法直接将PVRs应用于序列决策任务,忽略了PVRs在静态图像理解上的优化,无法有效捕捉任务进展的时序依赖关系,导致策略学习效果不佳。
核心思路:论文的核心思路是显式地解耦PVRs中的时间信息,从而缓解时间纠缠。通过解耦,策略可以更好地利用PVRs提取的视觉特征,并学习到更鲁棒的视觉运动策略。论文通过量化时间纠缠的影响,验证了解耦的必要性。
技术框架:论文提出了一种简单而有效的解耦基线。该基线包含两个主要模块:视觉表征模块和时间解耦模块。视觉表征模块使用预训练的视觉模型(例如ResNet)提取图像特征。时间解耦模块则负责从视觉特征中分离出与时间相关的信息。策略网络基于解耦后的特征进行动作预测。
关键创新:论文的关键创新在于识别并量化了预训练视觉表征在视觉运动策略学习中的时间纠缠问题,并提出了一种显式的时间解耦方法。与以往侧重于用时间组件丰富特征的方法不同,该论文强调了时间解耦的重要性,并证明了其有效性。
关键设计:时间解耦模块的具体实现方式未知,论文中提到是一种“简单而有效的解耦基线”,但没有给出具体的技术细节。损失函数的设计可能包含鼓励时间信息分离的正则项,网络结构可能包含专门用于处理时序信息的模块(例如LSTM或Transformer)。具体参数设置未知。
🖼️ 关键图片
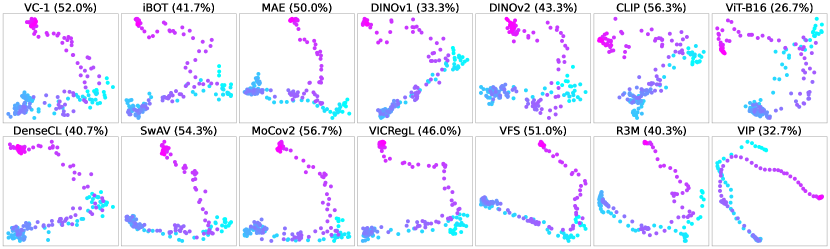

📊 实验亮点
论文通过实验验证了时间纠缠对视觉运动策略学习的影响,并证明了所提出的解耦基线的有效性。实验结果表明,传统的旨在用时间分量丰富特征的方法效果有限,而显式的时间解耦能够显著提升策略的性能。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域。通过解耦视觉表征中的时间信息,可以提升智能体在复杂动态环境中的感知和决策能力,使其能够更好地完成各种任务,例如物体抓取、路径规划、导航等。未来,该方法有望推动机器人和人工智能技术在实际场景中的应用。
📄 摘要(原文)
The integration of pre-trained visual representations (PVRs) has significantly advanced visuomotor policy learning. However, effectively leveraging these models remains a challenge. We identify temporal entanglement as a critical, inherent issue when using these time-invariant models in sequential decision-making tasks. This entanglement arises because PVRs, optimised for static image understanding, struggle to represent the temporal dependencies crucial for visuomotor control. In this work, we quantify the impact of temporal entanglement, demonstrating a strong correlation between a policy's success rate and the ability of its latent space to capture task-progression cues. Based on these insights, we propose a simple, yet effective disentanglement baseline designed to mitigate temporal entanglement. Our empirical results show that traditional methods aimed at enriching features with temporal components are insufficient on their own, highlighting the necessity of explicitly addressing temporal disentanglement for robust visuomotor policy learning.