DHP: Discrete Hierarchical Planning for Hierarchical Reinforcement Learning Agents
作者: Shashank Sharma, Janina Hoffmann, Vinay Namboodiri
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-02-04 (更新: 2025-12-19)
💡 一句话要点
DHP:面向分层强化学习智能体的离散分层规划方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分层强化学习 离散规划 可达性检查 长时程规划 优势估计 机器人导航 数据效率
📋 核心要点
- 传统分层强化学习在长时程视觉规划中依赖易错的距离度量,导致规划效果不佳。
- DHP使用离散可达性检查替代连续距离估计,并结合优势估计策略,鼓励生成更短且泛化性强的计划。
- 实验表明,DHP在导航任务中达到100%成功率,并在OGBench上取得SOTA结果,尤其在HumanoidMaze任务中提升显著。
📝 摘要(中文)
分层强化学习(HRL)智能体通常难以进行长时程视觉规划,因为它们依赖于容易出错的距离度量。我们提出了离散分层规划(DHP),该方法用离散可达性检查代替连续距离估计来评估子目标的可行性。DHP通过将长期目标分解为一系列更简单的子任务,递归地构建树状结构的计划,使用一种新颖的优势估计策略,该策略固有地奖励更短的计划,并推广到训练深度之外。此外,为了解决数据效率挑战,我们引入了一种探索策略,该策略为规划模块生成有针对性的训练示例,而无需专家数据。在25个房间的导航环境中进行的实验表明,成功率达到100%(基线为90%)。我们还展示了一个离线变体,在OGBench基准测试中实现了最先进的结果,在巨型HumanoidMaze任务中获得了高达71%的绝对收益,证明了我们的核心贡献与架构无关。该方法还推广到基于动量的控制任务,并且只需要log N步进行重新规划。理论分析和消融实验验证了我们的设计选择。
🔬 方法详解
问题定义:现有的分层强化学习(HRL)方法在处理长时程、视觉复杂的任务时,通常依赖于连续的距离度量来评估子目标的可行性。然而,这些距离度量容易出错,导致规划效果不佳,尤其是在视觉输入具有噪声或遮挡的情况下。此外,HRL智能体在探索和学习有效的层级策略时,往往面临数据效率低下的问题。
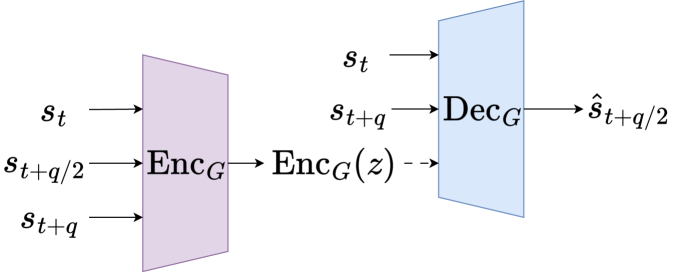
核心思路:DHP的核心思路是将连续的距离估计替换为离散的可达性检查。通过判断从当前状态是否能够到达某个子目标,来评估子目标的可行性。这种离散化的方法更加鲁棒,不易受到视觉噪声的影响。同时,DHP采用递归的方式构建树状结构的计划,将长期目标分解为一系列更简单的子任务,从而降低了规划的难度。
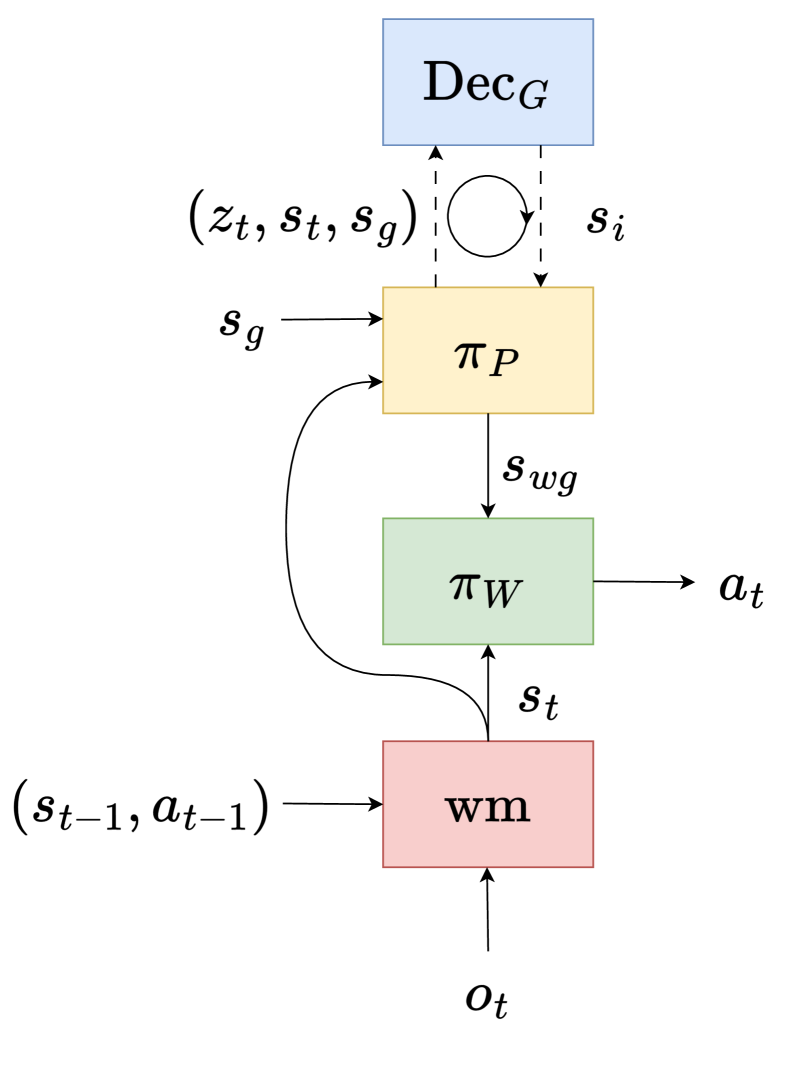
技术框架:DHP的整体框架包含以下几个主要模块:1)子目标选择模块:负责从候选子目标集合中选择合适的子目标。2)可达性检查模块:判断从当前状态是否能够到达选定的子目标。3)优势估计模块:评估不同计划的优劣,并选择最优计划。4)探索策略模块:生成有针对性的训练样本,提高数据效率。DHP通过递归地调用这些模块,构建完整的层级计划。
关键创新:DHP最重要的技术创新在于使用离散的可达性检查替代连续的距离估计。这种方法不仅更加鲁棒,而且可以更好地利用环境的离散结构。此外,DHP提出的优势估计策略能够有效地奖励更短的计划,并提高泛化能力。与现有方法相比,DHP不需要依赖专家数据,而是通过自主探索来学习有效的层级策略。
关键设计:DHP的关键设计包括:1)离散可达性检查的实现方式:可以使用各种方法来实现可达性检查,例如基于搜索的算法或基于学习的分类器。2)优势估计函数的具体形式:优势估计函数需要能够有效地评估不同计划的优劣,并鼓励生成更短的计划。3)探索策略的设计:探索策略需要能够生成有针对性的训练样本,提高数据效率。论文中具体的技术细节(参数设置、损失函数、网络结构等)未知。
🖼️ 关键图片

📊 实验亮点
DHP在25个房间的导航环境中实现了100%的成功率,相比基线方法提升了10%。在OGBench基准测试中,DHP的离线变体取得了最先进的结果,尤其是在巨型HumanoidMaze任务中,获得了高达71%的绝对收益。此外,DHP只需要log N步进行重新规划,表明其具有较高的效率。
🎯 应用场景
DHP具有广泛的应用前景,例如机器人导航、游戏AI、自动驾驶等领域。该方法可以帮助智能体在复杂环境中进行长时程规划,并提高任务完成的成功率和效率。此外,DHP的离线变体可以应用于图数据分析,例如药物发现、社交网络分析等。未来,DHP有望成为一种通用的分层强化学习方法,应用于更多实际场景。
📄 摘要(原文)
Hierarchical Reinforcement Learning (HRL) agents often struggle with long-horizon visual planning due to their reliance on error-prone distance metrics. We propose Discrete Hierarchical Planning (DHP), a method that replaces continuous distance estimates with discrete reachability checks to evaluate subgoal feasibility. DHP recursively constructs tree-structured plans by decomposing long-term goals into sequences of simpler subtasks, using a novel advantage estimation strategy that inherently rewards shorter plans and generalizes beyond training depths. In addition, to address the data efficiency challenge, we introduce an exploration strategy that generates targeted training examples for the planning modules without needing expert data. Experiments in 25-room navigation environments demonstrate a 100% success rate (vs. 90% baseline). We also present an offline variant that achieves state-of-the-art results on OGBench benchmarks, with up to 71% absolute gains on giant HumanoidMaze tasks, demonstrating our core contributions are architecture-agnostic. The method also generalizes to momentum-based control tasks and requires only log N steps for replanning. Theoretical analysis and ablations validate our design choices.