Flow-based Domain Randomization for Learning and Sequencing Robotic Skills
作者: Aidan Curtis, Eric Li, Michael Noseworthy, Nishad Gothoskar, Sachin Chitta, Hui Li, Leslie Pack Kaelbling, Nicole Carey
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-02-03 (更新: 2025-05-05)
💡 一句话要点
提出基于流模型的领域随机化方法,提升机器人技能学习与泛化能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 领域随机化 强化学习 归一化流 机器人技能学习 鲁棒性 泛化能力 采样分布学习
📋 核心要点
- 领域随机化是提升强化学习策略鲁棒性的有效手段,但手动设计随机化分布存在局限性。
- 论文提出基于归一化流的神经采样分布,通过熵正则化奖励最大化自动学习环境参数的采样分布。
- 实验表明,该方法在多个机器人任务中优于现有方法,并在真实机器人环境中验证了其有效性。
📝 摘要(中文)
本文研究了强化学习中领域随机化技术,旨在提升仿真训练的控制策略的鲁棒性。传统方法通常手动指定环境属性的随机化分布,本文则探索通过基于归一化流的神经采样分布,利用熵正则化的奖励最大化自动发现采样分布。实验结果表明,该架构比学习简单参数化采样分布的现有方法更灵活,并提供了更强的鲁棒性,这在六个模拟机器人领域和一个真实机器人领域中得到了验证。最后,本文还探讨了如何将这些学习到的采样分布与特权值函数相结合,用于不确定性感知的多步操作规划中的分布外检测。
🔬 方法详解
问题定义:领域随机化旨在通过在模拟环境中随机改变环境参数,使训练得到的策略对真实环境中的不确定性具有鲁棒性。然而,手动设计合适的随机化分布需要大量的领域知识和实验,且难以覆盖所有可能的变化。现有方法尝试学习参数化的采样分布,但其表达能力有限,难以适应复杂环境。
核心思路:本文的核心思路是利用归一化流(Normalizing Flow)强大的表达能力,学习一个能够生成复杂环境参数分布的采样器。通过最大化熵正则化的奖励,鼓励采样器探索更多样化的环境,从而提升策略的泛化能力。这种方法可以自动发现有效的随机化策略,无需手动设计。
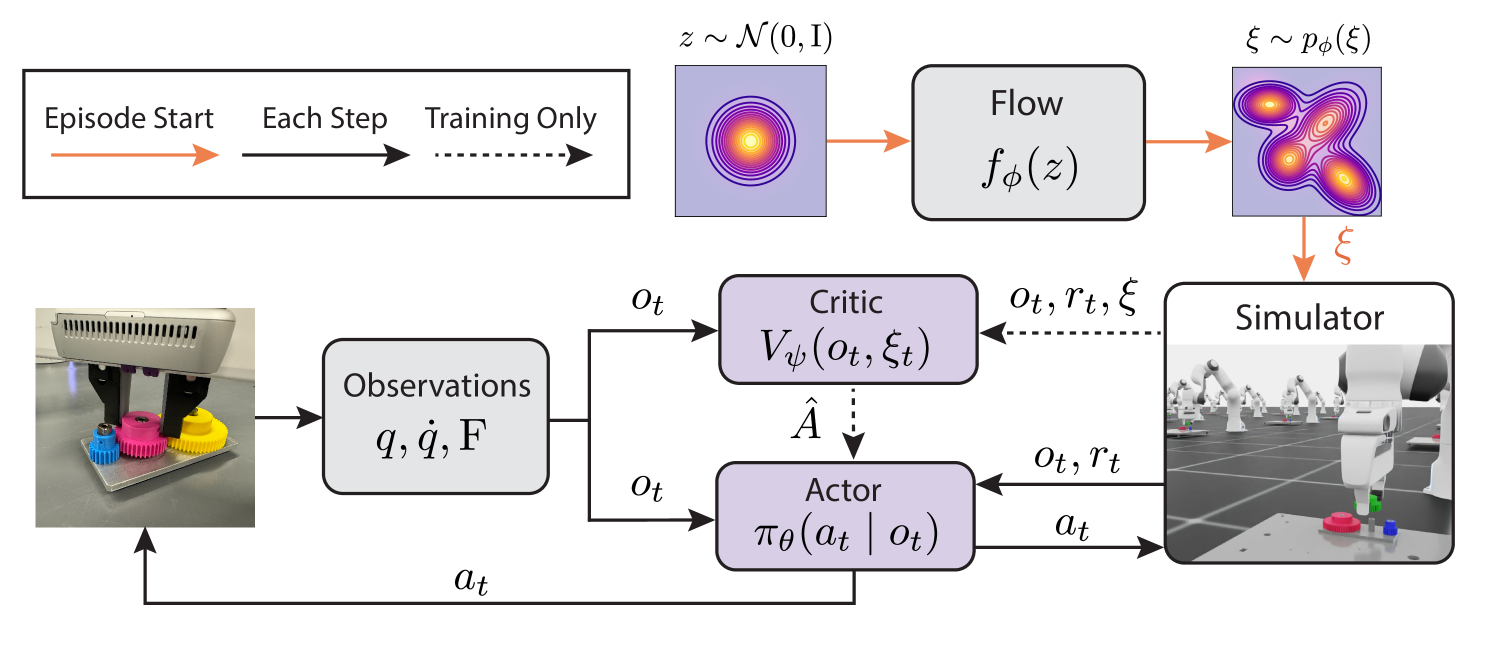
技术框架:整体框架包含一个基于归一化流的采样器和一个强化学习智能体。采样器从潜在空间生成环境参数,这些参数被用于配置模拟环境。智能体在这些随机化的环境中进行训练,并获得奖励。采样器的目标是最大化智能体的期望奖励,同时保持采样分布的熵。该框架使用策略梯度方法更新智能体,并使用反向传播更新采样器的参数。
关键创新:最重要的创新点在于使用归一化流来学习领域随机化的采样分布。与传统的参数化方法相比,归一化流具有更强的表达能力,可以学习更复杂的分布。此外,熵正则化的引入鼓励采样器探索更多样化的环境,从而进一步提升策略的鲁棒性。将学习到的采样分布与特权值函数结合,用于不确定性感知的多步操作规划中的分布外检测也是一个创新点。
关键设计:归一化流的具体结构未知,但通常采用堆叠多个可逆变换层的方式构建。损失函数包含两部分:智能体的期望奖励和采样分布的熵。熵正则化系数是一个重要的超参数,需要根据具体任务进行调整。特权值函数可能是在理想状态下训练得到的,用于评估当前状态的价值。
🖼️ 关键图片

📊 实验亮点
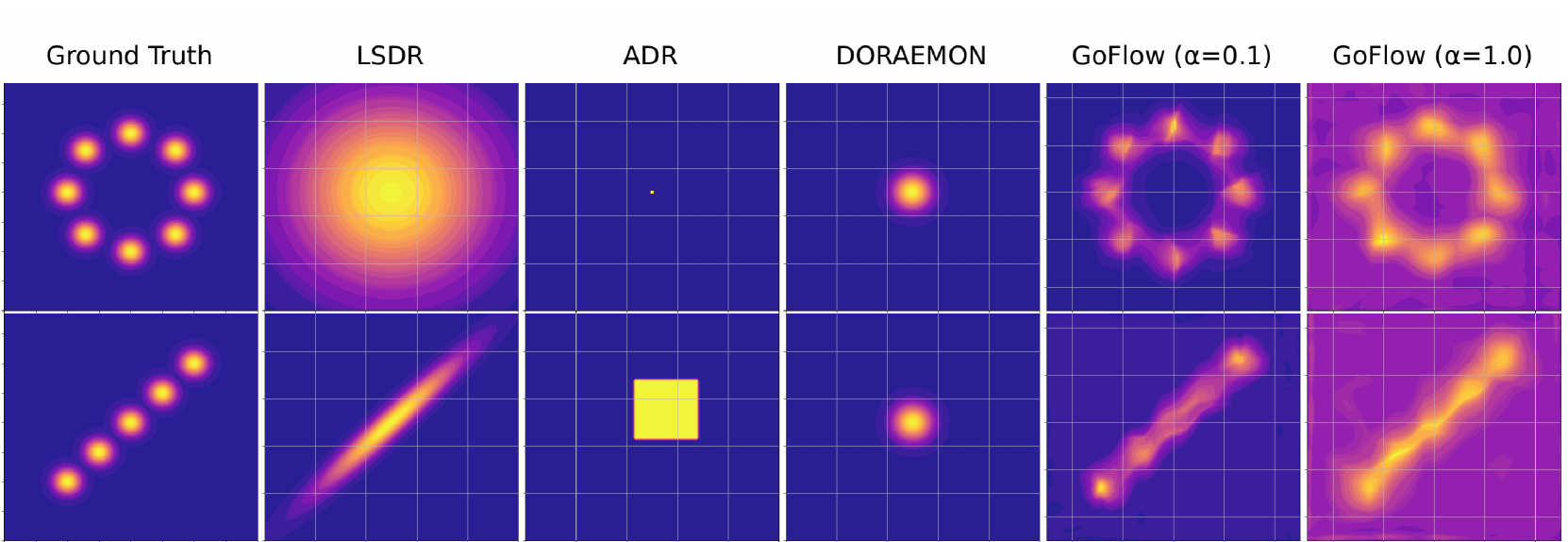
实验结果表明,该方法在六个模拟机器人领域和一个真实机器人领域中均优于现有的领域随机化方法。具体而言,该方法能够学习到更有效的随机化策略,从而使训练得到的策略在真实环境中具有更高的成功率和更强的鲁棒性。具体的性能提升数据未知,但文中强调了其优于现有方法的灵活性和鲁棒性。
🎯 应用场景
该研究成果可应用于各种机器人技能学习任务,尤其是在真实环境与模拟环境存在差异的情况下。例如,可用于训练能够在复杂环境中执行抓取、装配等任务的机器人。此外,该方法还可以扩展到其他领域,如自动驾驶、游戏AI等,以提升智能体的鲁棒性和泛化能力。
📄 摘要(原文)
Domain randomization in reinforcement learning is an established technique for increasing the robustness of control policies trained in simulation. By randomizing environment properties during training, the learned policy can become robust to uncertainties along the randomized dimensions. While the environment distribution is typically specified by hand, in this paper we investigate automatically discovering a sampling distribution via entropy-regularized reward maximization of a normalizing-flow-based neural sampling distribution. We show that this architecture is more flexible and provides greater robustness than existing approaches that learn simpler, parameterized sampling distributions, as demonstrated in six simulated and one real-world robotics domain. Lastly, we explore how these learned sampling distributions, combined with a privileged value function, can be used for out-of-distribution detection in an uncertainty-aware multi-step manipulation planner.