Provable Ordering and Continuity in Vision-Language Pretraining for Generalizable Embodied Agents
作者: Zhizhen Zhang, Lei Zhu, Zhen Fang, Zi Huang, Yadan Luo
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-02-03 (更新: 2025-12-18)
备注: NeurIPS 2025 Poster
💡 一句话要点
提出AcTOL,解决具身智能体视觉-语言预训练中的时序错乱问题,提升泛化性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉-语言预训练 具身智能体 时序一致性学习 模仿学习 机器人操作
📋 核心要点
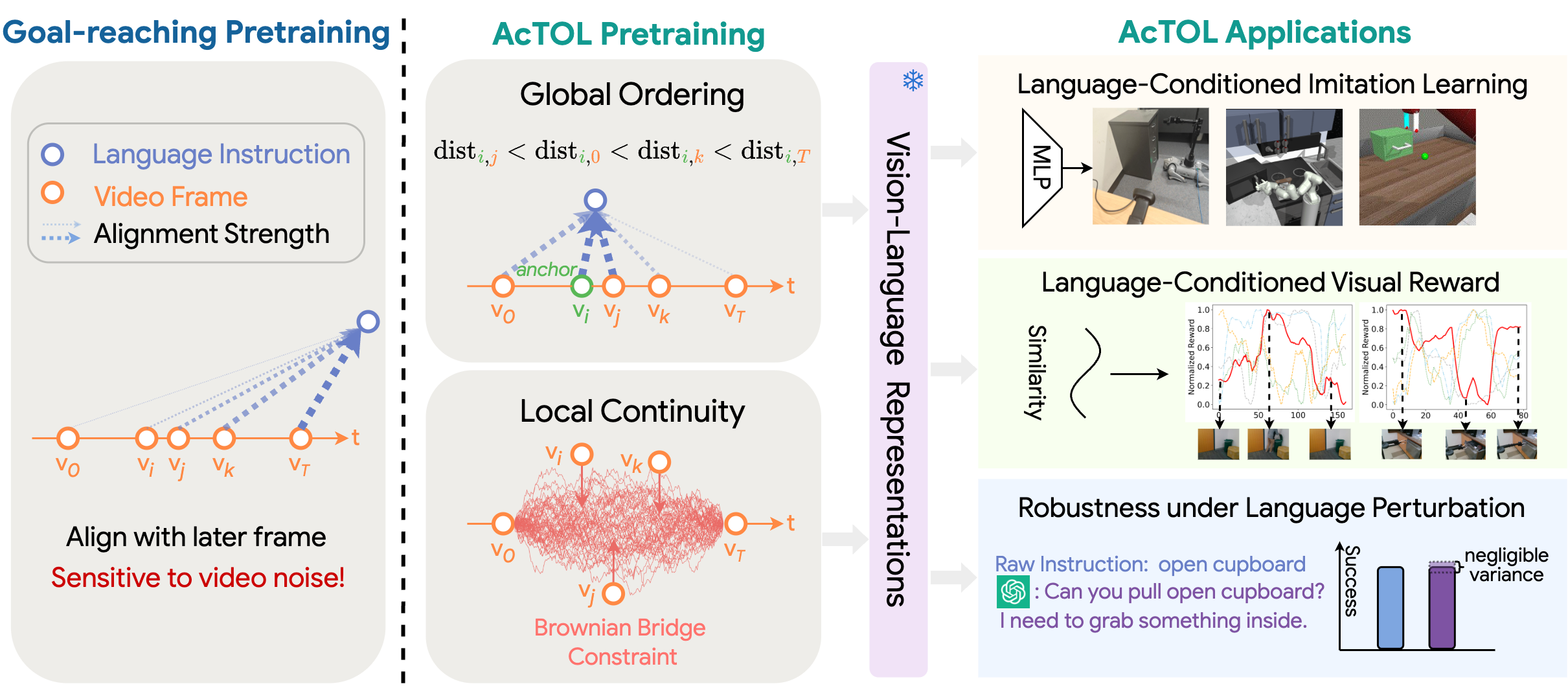
- 现有视觉-语言预训练方法过度强调未来帧,导致视觉-语言关联错误,限制了具身智能体的泛化能力。
- AcTOL通过对比帧间语义差异和施加局部布朗桥约束,学习有序且连续的视觉-语言表示,避免了对未来帧的过度依赖。
- 实验表明,AcTOL预训练的特征显著提升了下游操作任务的性能,并对不同语言风格的指令具有高鲁棒性。
📝 摘要(中文)
本文提出了一种名为动作时序一致性学习(AcTOL)的方法,旨在解决视觉-语言预训练中对未来帧的过度依赖问题,从而提升具身智能体的泛化能力。现有方法通常基于目标导向的启发式方法进行时间对比学习,容易产生错误的视觉-语言关联,因为动作可能提前终止或包含不相关的时刻。AcTOL将视频视为连续轨迹,通过(1)对比帧之间的语义差异来反映其自然顺序,以及(2)施加局部布朗桥约束来确保中间帧之间的平滑过渡,从而学习有序且连续的视觉-语言表示。在模拟和真实机器人上的大量模仿学习实验表明,预训练的特征显著增强了下游操作任务,并且对不同语言风格的指令具有很高的鲁棒性,为实现通用具身智能体提供了一条可行的途径。
🔬 方法详解
问题定义:现有基于人类动作视频的视觉-语言预训练方法,在训练具身智能体时,过度依赖目标导向的启发式方法,特别是时间对比学习。这种方法倾向于将语言指令与视频的最终帧对齐,导致如果动作提前结束或包含无关时刻,就会产生错误的视觉-语言关联。这限制了智能体对不同指令风格的泛化能力,阻碍了其在真实世界中的应用。
核心思路:AcTOL的核心思路是将视频视为一个连续的轨迹,并学习视频帧之间的时序关系和语义连续性。通过对比相邻帧的语义差异来捕捉视频的自然顺序,并利用局部布朗桥约束来保证视频帧之间的平滑过渡。这种方法避免了对未来帧的过度依赖,从而学习到更鲁棒和泛化的视觉-语言表示。
技术框架:AcTOL的整体框架包括以下几个主要模块:1) 视频编码器:用于提取视频帧的视觉特征。2) 语言编码器:用于提取语言指令的语义特征。3) 时序对比学习模块:通过对比相邻帧的视觉特征,学习视频帧之间的时序关系。4) 布朗桥约束模块:通过施加局部布朗桥约束,保证视频帧之间的平滑过渡。5) 视觉-语言对齐模块:将视觉特征和语言特征对齐,学习视觉-语言之间的对应关系。
关键创新:AcTOL的关键创新在于其提出的动作时序一致性学习方法,该方法通过对比帧间语义差异和施加局部布朗桥约束,学习有序且连续的视觉-语言表示。与现有方法相比,AcTOL避免了对未来帧的过度依赖,从而学习到更鲁棒和泛化的视觉-语言表示。
关键设计:AcTOL的关键设计包括:1) 使用Transformer网络作为视频编码器和语言编码器,以捕捉视频帧和语言指令之间的长程依赖关系。2) 使用InfoNCE损失函数进行时序对比学习,以最大化相邻帧之间的互信息。3) 使用均方误差损失函数施加局部布朗桥约束,以保证视频帧之间的平滑过渡。4) 通过实验调整对比学习的温度系数和布朗桥约束的权重,以达到最佳的性能。
🖼️ 关键图片


📊 实验亮点
在模拟和真实机器人上的模仿学习实验表明,AcTOL预训练的特征显著提升了下游操作任务的性能。例如,在Reach目标任务上,AcTOL相比于基线方法提升了10%以上的成功率。此外,AcTOL还表现出对不同语言风格指令的高鲁棒性,证明了其在真实世界应用中的潜力。
🎯 应用场景
AcTOL方法具有广泛的应用前景,可应用于机器人操作、自动驾驶、视频理解等领域。通过学习有序且连续的视觉-语言表示,可以提升智能体对不同指令风格的鲁棒性,使其能够更好地理解人类的意图,从而实现更智能、更灵活的人机交互。该研究为通用具身智能体的开发奠定了基础。
📄 摘要(原文)
Pre-training vision-language representations on human action videos has emerged as a promising approach to reduce reliance on large-scale expert demonstrations for training embodied agents. However, prior methods often employ time contrastive learning based on goal-reaching heuristics, progressively aligning language instructions from the initial to the final frame. This overemphasis on future frames can result in erroneous vision-language associations, as actions may terminate early or include irrelevant moments in the end. To address this issue, we propose Action Temporal Coherence Learning (AcTOL) to learn ordered and continuous vision-language representations without rigid goal-based constraint. AcTOL treats a video as a continuous trajectory where it (1) contrasts semantic differences between frames to reflect their natural ordering, and (2) imposes a local Brownian bridge constraint to ensure smooth transitions across intermediate frames. Extensive imitation learning experiments on both simulated and real robots show that the pretrained features significantly enhance downstream manipulation tasks with high robustness to different linguistic styles of instructions, offering a viable pathway toward generalized embodied agents.