Scalable, Training-Free Visual Language Robotics: A Modular Multi-Model Framework for Consumer-Grade GPUs
作者: Marie Samson, Bastien Muraccioli, Fumio Kanehiro
分类: cs.RO
发布日期: 2025-02-03
期刊: 2025 IEEE/SICE International Symposium on System Integration
💡 一句话要点
提出SVLR:一种可扩展、免训练的视觉语言机器人框架,适用于消费级GPU
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言机器人 免训练学习 可扩展框架 模块化设计 消费级GPU 机器人控制 自然语言指令
📋 核心要点
- 现有的视觉语言动作(VLA)模型计算成本高昂,需要大量重新训练,可扩展性有限,难以广泛应用。
- SVLR框架通过结合轻量级开源模型,无需重新训练即可实现机器人控制,并具有良好的可扩展性和模块化。
- SVLR在消费级GPU上实现了抓取和放置任务,初步结果令人鼓舞,但仍需进一步评估泛化能力。
📝 摘要(中文)
本文介绍了一种名为SVLR(Scalable Visual Language Robotics)的开源、模块化框架,用于机器人控制,无需重新训练,并提供可扩展的解决方案。SVLR利用轻量级的开源AI模型组合,包括视觉语言模型(VLM) Mini-InternVL、零样本图像分割模型CLIPSeg、大型语言模型Phi-3和句子相似度模型all-MiniLM,来处理视觉和语言输入。这些模型协同工作,识别未知环境中的对象,并将它们用作任务执行的参数,并生成一系列动作以响应自然语言指令。SVLR的一个关键优势是其可扩展性。该框架允许通过简单地添加文本描述和任务定义来轻松集成新的机器人任务和机器人,而无需重新训练。这种模块化确保了SVLR可以不断适应AI技术的最新进展,并支持各种机器人和任务。SVLR在NVIDIA RTX 2070(移动版)GPU上有效运行,在执行抓取和放置任务方面表现出良好的性能。虽然这些初步结果令人鼓舞,但还需要在更广泛的任务集中进行进一步评估,并与现有的VLA模型进行比较,以评估SVLR在更复杂场景中的泛化能力和性能。
🔬 方法详解
问题定义:现有视觉语言动作模型(VLA)在机器人控制领域展现出潜力,但面临计算成本高、需要大量重新训练以及可扩展性不足的问题。这些问题限制了VLA模型在实际场景中的广泛应用,尤其是在资源受限的环境中。
核心思路:SVLR的核心思路是构建一个模块化、可扩展且无需重新训练的框架,通过组合轻量级的开源AI模型来处理视觉和语言输入,从而实现机器人控制。这种设计旨在降低计算成本,提高灵活性,并简化新任务和机器人的集成过程。
技术框架:SVLR框架包含以下主要模块:1) 视觉语言模型(VLM) Mini-InternVL,用于理解图像和文本之间的关系;2) 零样本图像分割模型CLIPSeg,用于识别图像中的对象;3) 大型语言模型Phi-3,用于生成动作序列;4) 句子相似度模型all-MiniLM,用于理解自然语言指令。这些模块协同工作,首先通过VLM和CLIPSeg识别环境中的对象,然后使用LLM根据自然语言指令生成相应的动作序列,最后控制机器人执行这些动作。
关键创新:SVLR最重要的技术创新在于其免训练的可扩展性。通过模块化的设计和轻量级模型的组合,SVLR可以轻松集成新的机器人任务和机器人,而无需进行耗时的重新训练。这使得SVLR能够快速适应新的环境和任务需求,并降低了部署和维护成本。
关键设计:SVLR的关键设计包括:1) 选择轻量级的开源模型,以降低计算成本;2) 采用模块化的架构,方便集成新的功能和模型;3) 使用自然语言指令作为输入,提高用户友好性;4) 通过文本描述和任务定义来扩展任务和机器人,无需重新训练。
🖼️ 关键图片
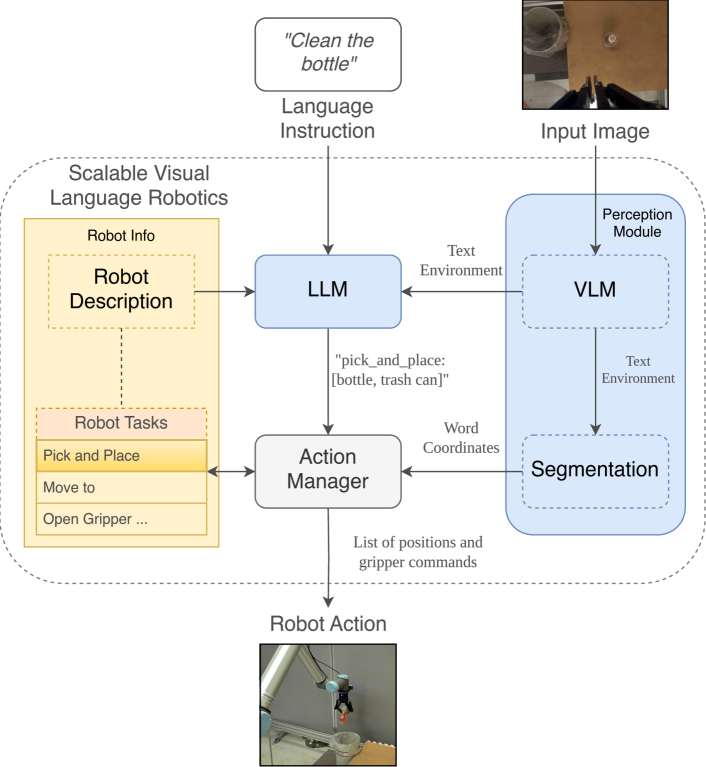


📊 实验亮点
SVLR框架在NVIDIA RTX 2070(移动版)GPU上成功运行,并在抓取和放置任务中表现出良好的性能。该框架无需重新训练即可适应新的任务和机器人,展示了其良好的可扩展性和泛化能力。虽然具体的性能数据和对比基线尚未给出,但初步结果表明SVLR具有很大的潜力。
🎯 应用场景
SVLR框架具有广泛的应用前景,可用于家庭服务机器人、工业自动化、仓储物流等领域。它能够使机器人理解自然语言指令,并自主完成各种任务,例如物品整理、环境清洁、产品组装等。SVLR的免训练特性使其能够快速部署到新的环境中,并适应不同的任务需求,具有很高的实际应用价值。
📄 摘要(原文)
The integration of language instructions with robotic control, particularly through Vision Language Action (VLA) models, has shown significant potential. However, these systems are often hindered by high computational costs, the need for extensive retraining, and limited scalability, making them less accessible for widespread use. In this paper, we introduce SVLR (Scalable Visual Language Robotics), an open-source, modular framework that operates without the need for retraining, providing a scalable solution for robotic control. SVLR leverages a combination of lightweight, open-source AI models including the Vision-Language Model (VLM) Mini-InternVL, zero-shot image segmentation model CLIPSeg, Large Language Model Phi-3, and sentence similarity model all-MiniLM to process visual and language inputs. These models work together to identify objects in an unknown environment, use them as parameters for task execution, and generate a sequence of actions in response to natural language instructions. A key strength of SVLR is its scalability. The framework allows for easy integration of new robotic tasks and robots by simply adding text descriptions and task definitions, without the need for retraining. This modularity ensures that SVLR can continuously adapt to the latest advancements in AI technologies and support a wide range of robots and tasks. SVLR operates effectively on an NVIDIA RTX 2070 (mobile) GPU, demonstrating promising performance in executing pick-and-place tasks. While these initial results are encouraging, further evaluation across a broader set of tasks and comparisons with existing VLA models are needed to assess SVLR's generalization capabilities and performance in more complex scenarios.