CAIMAN: Causal Action Influence Detection for Sample-efficient Loco-manipulation
作者: Yuanchen Yuan, Jin Cheng, Núria Armengol Urpí, Stelian Coros
分类: cs.RO, cs.LG
发布日期: 2025-02-02 (更新: 2025-04-28)
💡 一句话要点
CAIMAN:基于因果作用影响的采样高效足式机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 足式机器人 强化学习 因果作用影响 内在动机 非抓取操作
📋 核心要点
- 足式机器人进行非抓取操作(如推动物体)需要复杂的规划或任务特定的奖励塑造,尤其是在非结构化环境中。
- CAIMAN利用因果作用影响作为内在动机,鼓励智能体学习控制环境中的其他物体,从而提升学习效率。
- CAIMAN在仿真和真实机器人上验证了其采样效率和适应性,无需额外微调即可迁移到真实环境。
📝 摘要(中文)
本文提出CAIMAN,一个实用的强化学习框架,旨在提升足式机器人非抓取操作能力,使其能够有效地控制环境中的其他实体。CAIMAN利用因果作用影响作为内在动机目标,即使在稀疏奖励下,也能使足式机器人高效地学习物体推动技能。该方法采用分层控制策略,结合低层运动模块和高层策略,高层策略生成任务相关的速度指令,并通过最大化内在奖励进行训练。为了估计因果作用影响,通过整合运动学先验和训练数据来学习环境动力学。实验结果表明,CAIMAN在仿真环境中具有卓越的采样效率和对不同场景的适应性,并且无需进一步微调即可成功迁移到真实世界系统。
🔬 方法详解
问题定义:论文旨在解决足式机器人在非结构化环境中进行物体推动等非抓取操作时,需要大量样本学习和复杂奖励函数设计的问题。现有方法通常依赖于精细的任务特定奖励函数或复杂的规划策略,导致泛化能力差,采样效率低。
核心思路:论文的核心思路是将因果作用影响作为内在动机,引导机器人学习如何有效地影响环境中的物体。通过最大化对环境的因果影响,机器人能够自主地探索和学习有用的动作,从而提高采样效率和泛化能力。
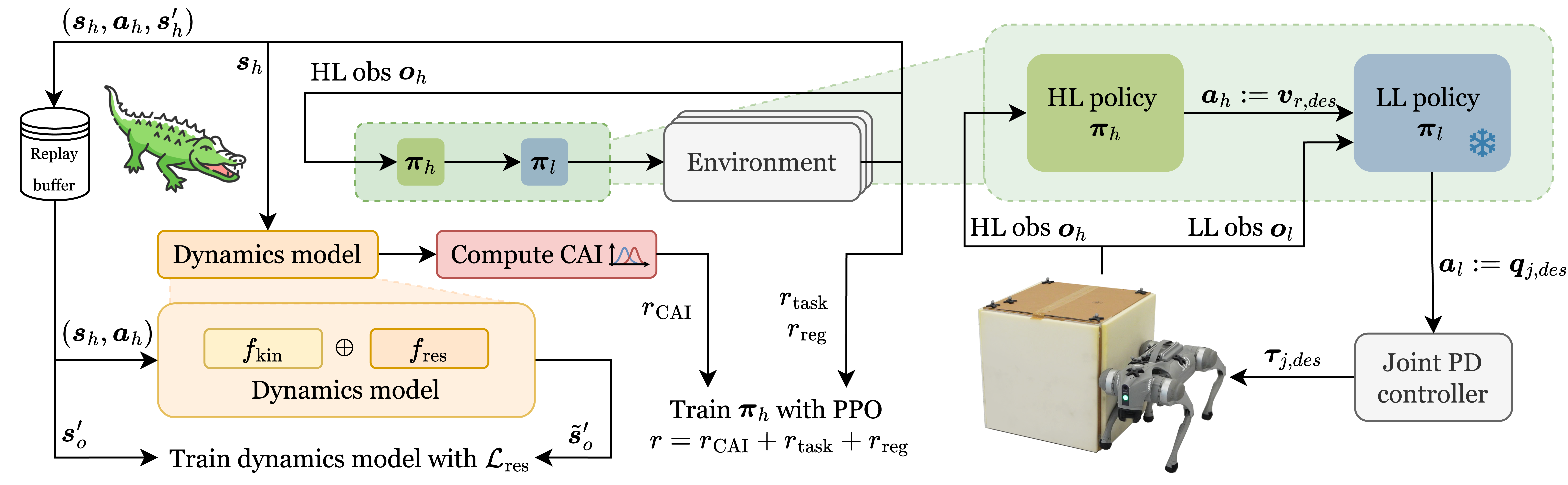
技术框架:CAIMAN采用分层控制结构。低层是一个预训练的运动模块,负责执行基本的运动控制。高层策略则负责生成任务相关的速度指令,并通过强化学习进行训练,以最大化内在奖励(即因果作用影响)。为了估计因果作用影响,系统会学习环境的动力学模型,该模型结合了运动学先验知识和训练数据。
关键创新:CAIMAN的关键创新在于将因果作用影响引入强化学习,作为一种内在动机。与传统的基于任务奖励的强化学习方法不同,CAIMAN鼓励机器人主动探索和学习如何影响环境,从而提高了采样效率和泛化能力。此外,结合运动学先验知识学习环境动力学模型也提高了模型的准确性和鲁棒性。
关键设计:CAIMAN使用TD3算法训练高层策略。因果作用影响的计算基于学习到的环境动力学模型,具体而言,通过比较在采取动作前后,物体状态的变化来估计动作的影响。损失函数包括内在奖励(因果作用影响)和可选的任务奖励。运动学先验知识被用来约束动力学模型的学习,提高模型的泛化能力。
🖼️ 关键图片


📊 实验亮点
CAIMAN在仿真环境中表现出优于基线方法的采样效率,在多个不同场景下成功学习了物体推动技能。更重要的是,CAIMAN无需任何微调即可成功迁移到真实世界的足式机器人系统,验证了其鲁棒性和泛化能力。实验结果表明,CAIMAN能够有效地利用因果作用影响作为内在动机,提高强化学习的效率。
🎯 应用场景
CAIMAN可应用于物流、仓储、搜索救援等领域,提升足式机器人在复杂环境中进行物体操作的能力。例如,在仓库中,机器人可以利用CAIMAN推动箱子,整理货物;在灾难现场,机器人可以推动障碍物,开辟救援通道。该研究有助于实现更智能、更灵活的足式机器人,使其能够更好地适应各种实际应用场景。
📄 摘要(原文)
Enabling legged robots to perform non-prehensile loco-manipulation is crucial for enhancing their versatility. Learning behaviors such as whole-body object pushing often requires sophisticated planning strategies or extensive task-specific reward shaping, especially in unstructured environments. In this work, we present CAIMAN, a practical reinforcement learning framework that encourages the agent to gain control over other entities in the environment. CAIMAN leverages causal action influence as an intrinsic motivation objective, allowing legged robots to efficiently acquire object pushing skills even under sparse task rewards. We employ a hierarchical control strategy, combining a low-level locomotion module with a high-level policy that generates task-relevant velocity commands and is trained to maximize the intrinsic reward. To estimate causal action influence, we learn the dynamics of the environment by integrating a kinematic prior with data collected during training.We empirically demonstrate CAIMAN's superior sample efficiency and adaptability to diverse scenarios in simulation, as well as its successful transfer to real-world systems without further fine-tuning.