SAM2Act: Integrating Visual Foundation Model with A Memory Architecture for Robotic Manipulation
作者: Haoquan Fang, Markus Grotz, Wilbert Pumacay, Yi Ru Wang, Dieter Fox, Ranjay Krishna, Jiafei Duan
分类: cs.RO
发布日期: 2025-01-30 (更新: 2025-07-13)
备注: Including Appendix, Project Page: https://sam2act.github.io
💡 一句话要点
SAM2Act:融合视觉基础模型与记忆架构的机器人操作策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉基础模型 Transformer 记忆架构 强化学习
📋 核心要点
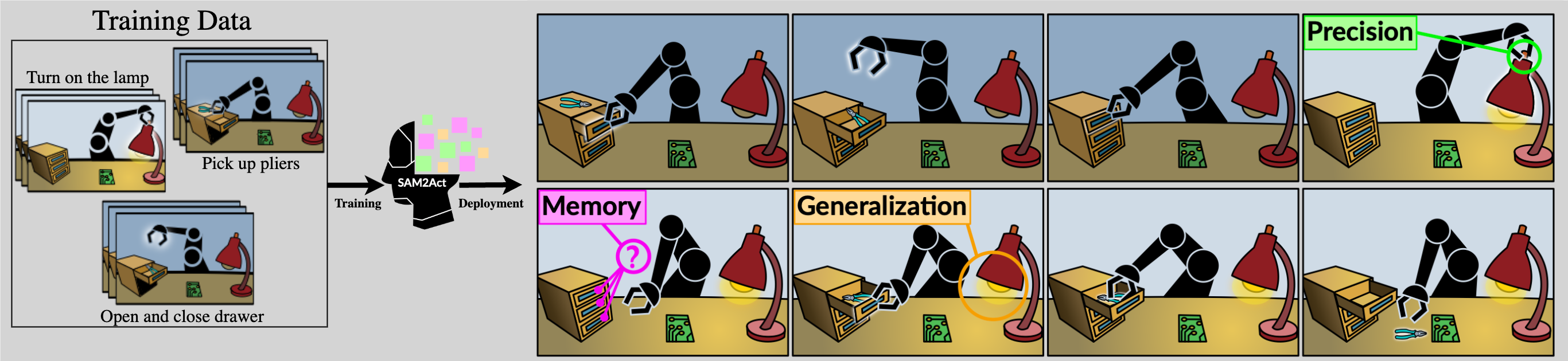
- 现有机器人操作方法在复杂环境变化和依赖记忆的任务中泛化能力不足,是当前面临的核心问题。
- SAM2Act利用视觉基础模型和Transformer策略,SAM2Act+引入记忆架构,增强空间记忆能力,解决上述问题。
- 实验表明,SAM2Act在RLBench和Colosseum上表现出色,SAM2Act+在MemoryBench上显著优于现有方法。
📝 摘要(中文)
本文提出SAM2Act,一种基于Transformer的多视角机器人策略,利用大规模视觉基础模型的多分辨率上采样视觉表征。SAM2Act在RLBench基准测试的18个任务中实现了86.8%的平均成功率,并在The Colosseum基准测试中表现出强大的泛化能力,在不同的环境扰动下仅有4.3%的性能差距。在此基础上,本文提出了SAM2Act+,一种受SAM2启发的基于记忆的架构,它结合了记忆库、编码器和注意力机制来增强空间记忆。为了评估依赖记忆的任务,本文引入了MemoryBench,这是一个用于评估机器人操作中空间记忆和动作回忆的新基准。SAM2Act+在MemoryBench的基于记忆的任务中实现了94.3%的平均成功率,显著优于现有方法,并推动了基于记忆的机器人系统的发展。
🔬 方法详解
问题定义:现有机器人操作系统在多样化、动态环境中,难以同时具备多任务交互、泛化到未见场景和空间记忆三种关键能力。尤其是在复杂环境变化和需要长期记忆的任务中,现有方法的性能会显著下降,无法有效完成任务。
核心思路:本文的核心思路是利用大规模视觉基础模型学习到的通用视觉表征,并结合Transformer架构来构建机器人操作策略。同时,为了增强机器人的空间记忆能力,引入了记忆模块,使其能够记住过去的状态和动作,从而更好地完成需要长期规划的任务。
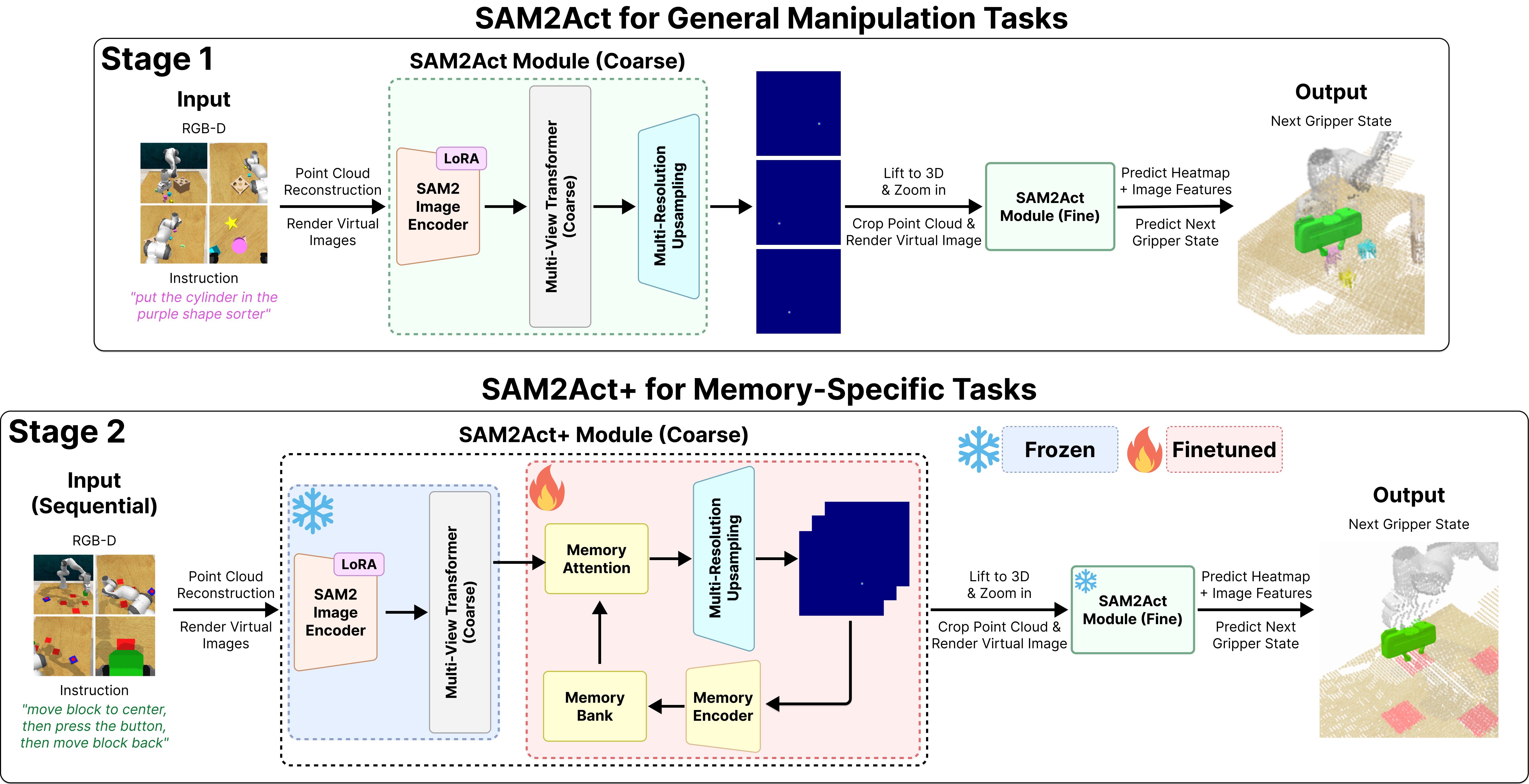
技术框架:SAM2Act是一个基于Transformer的多视角机器人策略,它利用多分辨率上采样技术提取视觉基础模型的特征。SAM2Act+则在SAM2Act的基础上增加了一个记忆模块,包括记忆库、编码器和注意力机制。整体流程如下:首先,从多个视角获取环境图像;然后,利用视觉基础模型提取图像特征;接着,使用Transformer策略根据当前状态和历史记忆生成动作;最后,执行动作并更新记忆库。
关键创新:本文的关键创新在于将大规模视觉基础模型与记忆架构相结合,从而提升了机器人操作系统的泛化能力和空间记忆能力。具体来说,利用视觉基础模型可以学习到通用的视觉表征,从而减少了对特定环境的依赖;而记忆模块则可以帮助机器人记住过去的状态和动作,从而更好地完成需要长期规划的任务。
关键设计:SAM2Act使用了多分辨率上采样技术,以融合不同尺度的视觉特征。SAM2Act+的记忆模块使用了一个可学习的编码器将历史状态和动作编码成记忆向量,并使用注意力机制来选择相关的记忆信息。损失函数包括模仿学习损失和强化学习损失,用于训练策略网络。
🖼️ 关键图片
📊 实验亮点
SAM2Act在RLBench基准测试的18个任务中实现了86.8%的平均成功率,超越了现有方法。在The Colosseum基准测试中,SAM2Act在不同的环境扰动下仅有4.3%的性能差距,表现出强大的泛化能力。SAM2Act+在MemoryBench的基于记忆的任务中实现了94.3%的平均成功率,显著优于现有方法,证明了记忆模块的有效性。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如家庭服务机器人、工业自动化机器人和医疗机器人等。通过提升机器人的泛化能力和空间记忆能力,可以使其更好地适应复杂多变的环境,完成更加复杂的任务。例如,家庭服务机器人可以利用该技术更好地理解用户的指令,并完成诸如清洁、整理和烹饪等任务。工业自动化机器人可以利用该技术更好地适应生产线的变化,并完成诸如装配、搬运和检测等任务。
📄 摘要(原文)
Robotic manipulation systems operating in diverse, dynamic environments must exhibit three critical abilities: multitask interaction, generalization to unseen scenarios, and spatial memory. While significant progress has been made in robotic manipulation, existing approaches often fall short in generalization to complex environmental variations and addressing memory-dependent tasks. To bridge this gap, we introduce SAM2Act, a multi-view robotic transformer-based policy that leverages multi-resolution upsampling with visual representations from large-scale foundation model. SAM2Act achieves a state-of-the-art average success rate of 86.8% across 18 tasks in the RLBench benchmark, and demonstrates robust generalization on The Colosseum benchmark, with only a 4.3% performance gap under diverse environmental perturbations. Building on this foundation, we propose SAM2Act+, a memory-based architecture inspired by SAM2, which incorporates a memory bank, an encoder, and an attention mechanism to enhance spatial memory. To address the need for evaluating memory-dependent tasks, we introduce MemoryBench, a novel benchmark designed to assess spatial memory and action recall in robotic manipulation. SAM2Act+ achieves an average success rate of 94.3% on memory-based tasks in MemoryBench, significantly outperforming existing approaches and pushing the boundaries of memory-based robotic systems. Project page: sam2act.github.io.