Learn from the Past: Language-conditioned Object Rearrangement with Large Language Models
作者: Guanqun Cao, Ryan Mckenna, Erich Graf, John Oyekan
分类: cs.RO
发布日期: 2025-01-30 (更新: 2025-03-05)
💡 一句话要点
提出基于LLM的语言条件物体重排列框架,实现零样本泛化
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 物体重排列 大型语言模型 机器人操作 零样本学习 语言条件控制
📋 核心要点
- 现有物体重排列方法依赖预训练数据集,泛化能力受限,难以处理复杂指令和多样化物体。
- 该方法利用LLM理解语言指令,并借鉴历史经验推理物体重排列策略,无需特定数据集训练。
- 实验表明,该方法能有效执行包含长序列指令的机器人重排列任务,具备良好的泛化能力。
📝 摘要(中文)
本文提出了一种基于大型语言模型(LLM)的灵活的语言条件物体重排列框架,用于协作机器人。该方法模仿人类的推理方式,利用过去的成功经验作为参考,推断实现当前期望目标位置的最佳策略。与依赖预收集数据集训练模型来预测目标位置的现有方法不同,该方法利用LLM强大的自然语言理解和推理能力,以零样本的方式泛化到各种日常物体和自由形式的语言指令。实验结果表明,该方法能够有效地执行机器人重排列任务,即使是涉及长序列指令的任务。
🔬 方法详解
问题定义:论文旨在解决机器人物体重排列任务中,现有方法依赖大量预训练数据、泛化能力差的问题。现有方法难以处理自由形式的语言指令和各种日常物体,限制了其在实际场景中的应用。此外,物体放置的精确性是关键挑战,错位会增加任务复杂性和碰撞风险。
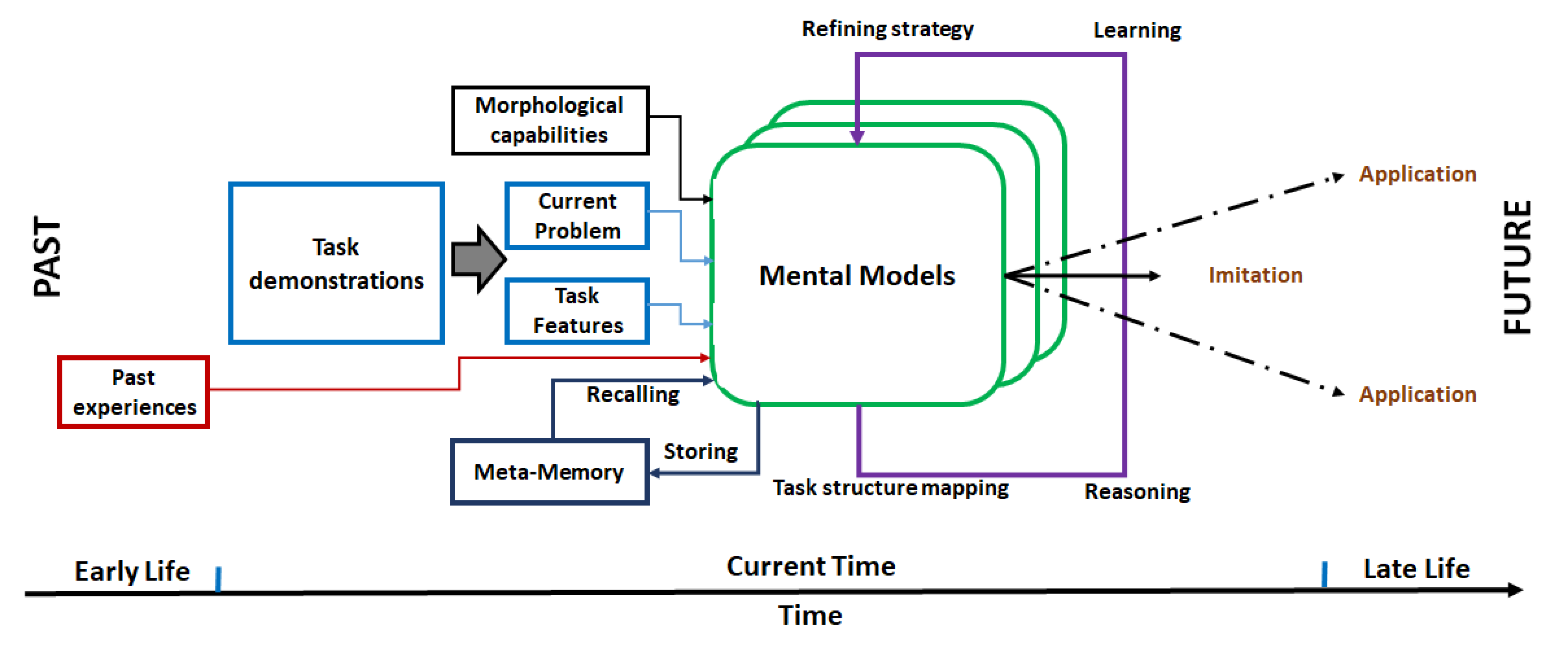
核心思路:论文的核心思路是模仿人类的推理方式,利用LLM强大的语言理解和推理能力,将过去的成功经验作为参考,推断出实现当前期望目标位置的最佳策略。通过借鉴历史经验,模型能够更好地理解指令意图,并规划出合理的物体重排列方案。
技术框架:该框架主要包含以下几个阶段:1) 接收自然语言指令,描述目标状态;2) LLM根据指令,结合历史经验(例如,过去的成功重排列案例),推理出当前任务的执行策略;3) 机器人根据LLM的推理结果,执行物体抓取和放置操作,完成重排列任务。整个过程无需针对特定物体或指令进行训练,实现零样本泛化。
关键创新:该方法最重要的技术创新点在于利用LLM的上下文学习能力,将历史经验融入到物体重排列任务中。与传统的监督学习方法不同,该方法不需要大量的标注数据,而是通过LLM的推理能力,实现对新任务的零样本泛化。这种方法更接近人类的解决问题方式,具有更强的适应性和灵活性。
关键设计:论文中并没有详细描述具体的参数设置、损失函数或网络结构,因为其核心在于利用预训练的LLM的推理能力。关键设计在于如何有效地将历史经验输入到LLM中,并引导LLM生成合理的重排列策略。具体实现细节(例如,如何存储和检索历史经验)可能因具体应用场景而异,论文中没有明确说明。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法能够有效地执行机器人重排列任务,即使是涉及长序列指令的任务。由于论文摘要中没有提供具体的性能数据和对比基线,因此无法量化提升幅度。但该方法在零样本条件下的泛化能力是其主要亮点。
🎯 应用场景
该研究成果可应用于智能仓储、家庭服务机器人、自动化装配等领域。例如,在智能仓储中,机器人可以根据订单指令,自动完成货物的拣选和重排列。在家庭服务中,机器人可以根据用户的语言指令,整理房间,摆放物品。该技术有望提升机器人的智能化水平,使其能够更好地服务于人类。
📄 摘要(原文)
Object manipulation for rearrangement into a specific goal state is a significant task for collaborative robots. Accurately determining object placement is a key challenge, as misalignment can increase task complexity and the risk of collisions, affecting the efficiency of the rearrangement process. Most current methods heavily rely on pre-collected datasets to train the model for predicting the goal position. As a result, these methods are restricted to specific instructions, which limits their broader applicability and generalisation. In this paper, we propose a framework of flexible language-conditioned object rearrangement based on the Large Language Model (LLM). Our approach mimics human reasoning by making use of successful past experiences as a reference to infer the best strategies to achieve a current desired goal position. Based on LLM's strong natural language comprehension and inference ability, our method generalises to handle various everyday objects and free-form language instructions in a zero-shot manner. Experimental results demonstrate that our methods can effectively execute the robotic rearrangement tasks, even those involving long sequences of orders.