Curriculum-based Sample Efficient Reinforcement Learning for Robust Stabilization of a Quadrotor
作者: Fausto Mauricio Lagos Suarez, Akshit Saradagi, Vidya Sumathy, Shruti Kotpaliwar, George Nikolakopoulos
分类: cs.RO, cs.AI
发布日期: 2025-01-30 (更新: 2025-04-17)
备注: 8 pages, 7 figures
💡 一句话要点
提出基于课程学习的强化学习方法,用于四旋翼飞行器鲁棒稳定控制。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四旋翼飞行器 强化学习 课程学习 鲁棒控制 近端策略优化
📋 核心要点
- 传统强化学习方法在四旋翼控制中面临样本效率低、奖励函数设计复杂等挑战,导致训练困难。
- 论文提出一种基于课程学习的强化学习框架,通过分解任务难度,逐步训练四旋翼飞行器。
- 实验结果表明,该方法在收敛速度、资源消耗和鲁棒性方面均优于单阶段强化学习方法。
📝 摘要(中文)
本文提出了一种基于课程学习的强化学习方法,用于开发四旋翼飞行器的鲁棒稳定控制器,使其满足预定义的性能指标。学习目标是在满足瞬态和稳态性能规范的同时,从随机初始条件达到期望位置。由于位置和姿态动力学的强耦合性、奖励函数设计和调整的复杂性以及样本效率低下,传统的单阶段端到端强化学习难以实现此目标,这需要大量的计算资源并导致较长的收敛时间。为了解决这些挑战,本文将学习目标分解为三个阶段的课程,逐步增加任务的复杂性。课程从学习从固定初始条件实现稳定悬停开始,然后逐步引入初始位置、姿态和速度的随机化。提出了一种新的加性奖励函数,以结合瞬态和稳态性能规范。结果表明,基于近端策略优化(PPO)的课程学习方法,结合所提出的奖励结构,与使用相同奖励函数的单阶段PPO训练策略相比,实现了卓越的性能,同时显著降低了计算资源需求和收敛时间。经过课程训练的策略的性能和鲁棒性在随机初始条件和存在扰动的情况下得到了充分验证。
🔬 方法详解
问题定义:论文旨在解决四旋翼飞行器在复杂环境下的鲁棒稳定控制问题。传统的强化学习方法由于状态空间大、探索困难、奖励函数设计复杂等原因,导致样本效率低,训练时间长,难以满足实际应用需求。特别是,四旋翼的位置和姿态动力学强耦合,使得控制策略的学习更加困难。
核心思路:论文的核心思路是采用课程学习的思想,将复杂的控制任务分解为多个难度递增的子任务。通过先学习简单的任务,逐步引入复杂性,可以有效地提高样本效率,加速学习过程,并最终获得更鲁棒的控制策略。这种方法模仿了人类学习的过程,从易到难,逐步掌握复杂的技能。
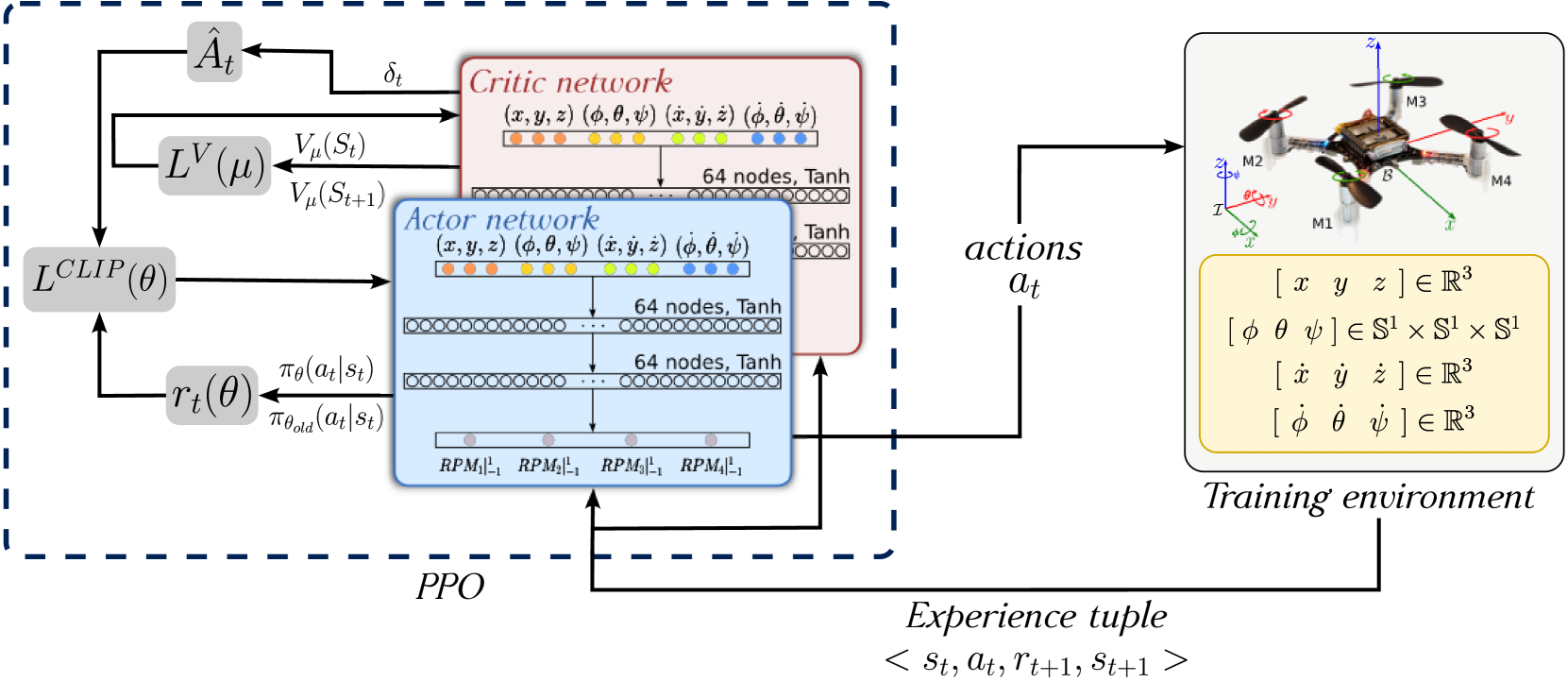
技术框架:整体框架包含三个阶段的课程:第一阶段,学习从固定初始位置实现稳定悬停;第二阶段,在固定初始位置的基础上,引入初始姿态和速度的随机化;第三阶段,进一步引入初始位置的随机化。每个阶段都使用PPO算法进行训练,并使用一个共享的神经网络作为策略网络。
关键创新:论文的关键创新在于课程学习策略和加性奖励函数的设计。课程学习策略通过逐步增加任务难度,提高了样本效率和学习速度。加性奖励函数综合考虑了瞬态和稳态性能指标,使得控制策略能够同时满足稳定性和精度要求。
关键设计:论文设计了一个加性奖励函数,包括位置误差、速度误差、姿态误差和角速度误差等多个部分。每个部分都经过精心设计,以保证奖励函数的有效性和可训练性。此外,论文还对PPO算法的超参数进行了调整,以适应四旋翼控制任务的特点。
🖼️ 关键图片
📊 实验亮点
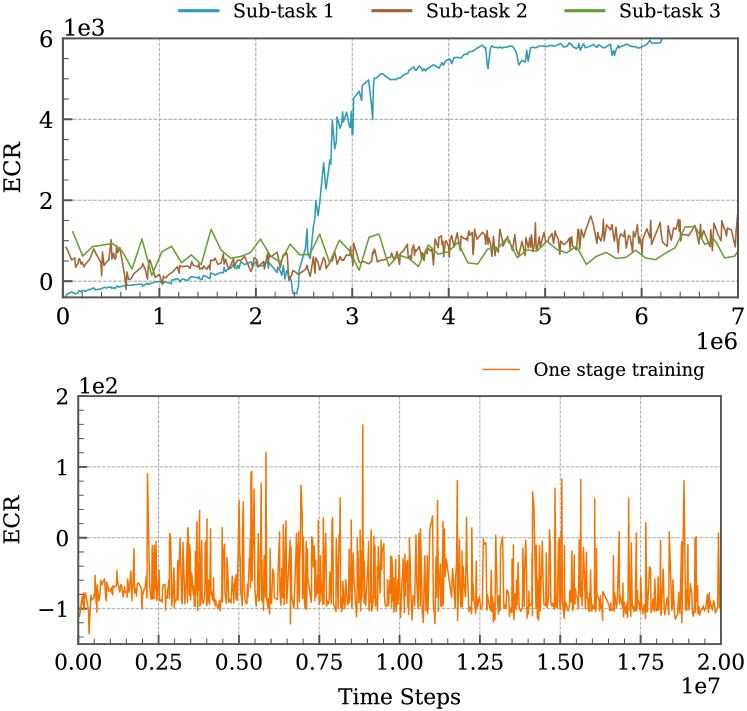
实验结果表明,基于课程学习的PPO算法在收敛速度上比单阶段PPO算法快得多,并且能够获得更好的控制性能。在随机初始条件和存在扰动的情况下,课程学习训练的策略表现出更强的鲁棒性。具体性能数据未知,但论文强调了显著的性能提升和资源节约。
🎯 应用场景
该研究成果可应用于无人机自主导航、智能巡检、物流配送等领域。通过课程学习强化学习方法,可以训练出更鲁棒、更高效的四旋翼飞行器控制策略,使其能够在复杂环境中安全可靠地完成任务。未来,该方法还可以扩展到其他类型的机器人控制问题中。
📄 摘要(原文)
This article introduces a curriculum learning approach to develop a reinforcement learning-based robust stabilizing controller for a Quadrotor that meets predefined performance criteria. The learning objective is to achieve desired positions from random initial conditions while adhering to both transient and steady-state performance specifications. This objective is challenging for conventional one-stage end-to-end reinforcement learning, due to the strong coupling between position and orientation dynamics, the complexity in designing and tuning the reward function, and poor sample efficiency, which necessitates substantial computational resources and leads to extended convergence times. To address these challenges, this work decomposes the learning objective into a three-stage curriculum that incrementally increases task complexity. The curriculum begins with learning to achieve stable hovering from a fixed initial condition, followed by progressively introducing randomization in initial positions, orientations and velocities. A novel additive reward function is proposed, to incorporate transient and steady-state performance specifications. The results demonstrate that the Proximal Policy Optimization (PPO)-based curriculum learning approach, coupled with the proposed reward structure, achieves superior performance compared to a single-stage PPO-trained policy with the same reward function, while significantly reducing computational resource requirements and convergence time. The curriculum-trained policy's performance and robustness are thoroughly validated under random initial conditions and in the presence of disturbances.