Certificated Actor-Critic: Hierarchical Reinforcement Learning with Control Barrier Functions for Safe Navigation
作者: Junjun Xie, Shuhao Zhao, Liang Hu, Huijun Gao
分类: cs.RO, cs.LG
发布日期: 2025-01-29
备注: Accepted to ICRA 2025
💡 一句话要点
提出基于控制屏障函数的分层强化学习算法CAC,用于机器人安全导航
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 控制屏障函数 安全导航 分层强化学习 机器人控制
📋 核心要点
- 现有基于控制屏障函数(CBF)的机器人安全导航方法,在计算效率、模型依赖性和性能指标方面存在不足。
- 提出Certificated Actor-Critic (CAC)算法,利用分层强化学习框架和基于CBF设计的奖励函数,实现安全导航。
- 通过仿真实验验证了CAC算法的有效性,表明其在安全性和导航性能上具有优势。
📝 摘要(中文)
控制屏障函数(CBFs)已成为设计机器人安全导航系统的常用方法。然而,现有的基于CBF的方法存在一些局限性:基于优化的安全控制技术要么是短视的,要么计算量大,并且依赖于简化的系统模型;另一方面,基于学习的方法在导航性能和安全性方面缺乏定量指标。本文提出了一种新的无模型强化学习算法,称为Certificated Actor-Critic (CAC),它引入了一个分层强化学习框架和从CBF导出的良好定义的奖励函数。我们对算法进行了理论分析和证明,并提出了算法实现的改进。通过两个仿真实验验证了我们的分析,表明了所提出的CAC算法的有效性。
🔬 方法详解
问题定义:论文旨在解决机器人安全导航问题,现有基于CBF的方法存在优化计算量大、依赖简化模型以及学习方法缺乏定量安全指标等痛点。这些问题限制了CBF在复杂环境和真实机器人系统中的应用。
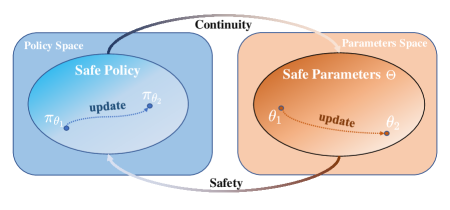
核心思路:论文的核心思路是结合控制屏障函数(CBF)和分层强化学习,利用CBF提供安全约束,并将其融入强化学习的奖励函数设计中,从而引导智能体学习安全的导航策略。分层结构允许智能体在高层进行决策,底层执行安全控制。
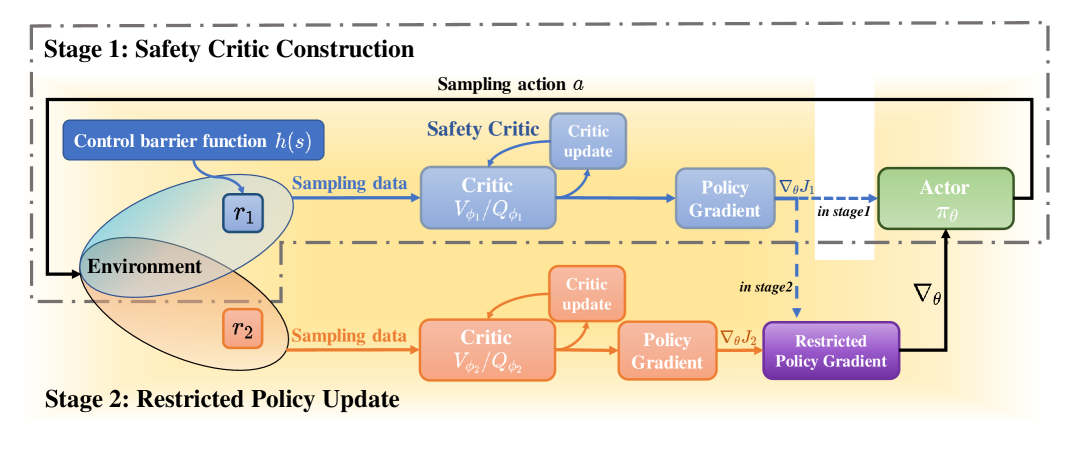
技术框架:CAC算法采用分层Actor-Critic架构。高层Actor-Critic网络学习全局导航策略,生成目标速度。底层控制器基于CBF,将高层目标速度转化为安全的实际控制指令,保证机器人不违反安全约束。整体流程包括:状态观测、高层Actor生成目标速度、底层CBF控制器计算安全控制指令、环境反馈新状态和奖励,以及Actor-Critic网络的更新。
关键创新:该算法的关键创新在于将CBF融入强化学习框架,通过CBF指导奖励函数的设计,使得智能体在学习过程中能够显式地考虑安全性。此外,分层结构将全局导航策略学习和局部安全控制解耦,降低了学习难度。
关键设计:奖励函数的设计是关键,它由两部分组成:一部分是导航奖励,鼓励智能体到达目标;另一部分是安全奖励,基于CBF,当智能体接近安全边界时,给予负奖励,引导智能体远离危险区域。Actor和Critic网络通常采用深度神经网络,损失函数包括Actor的策略梯度损失和Critic的时序差分误差。CBF控制器的设计需要根据具体的机器人动力学模型和安全约束进行调整。
🖼️ 关键图片
📊 实验亮点
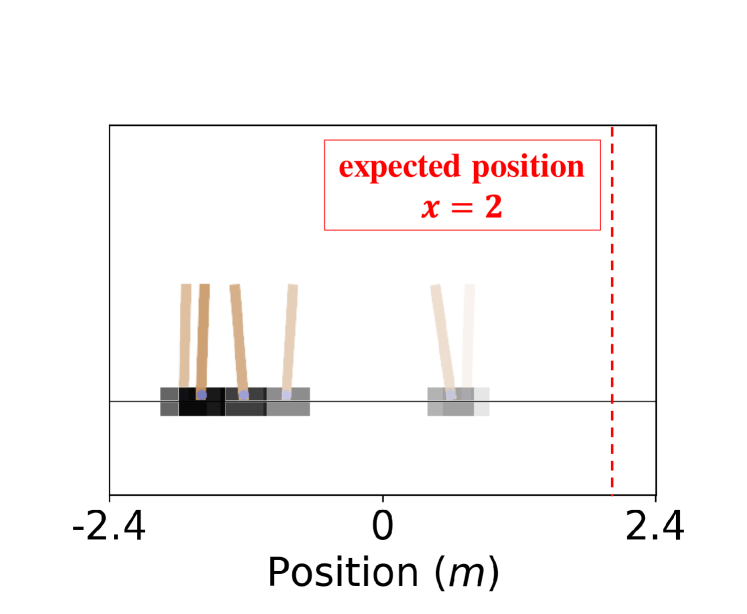
论文通过两个仿真实验验证了CAC算法的有效性。实验结果表明,CAC算法在保证安全性的前提下,能够有效地引导机器人到达目标点。与传统的强化学习算法相比,CAC算法在安全性和导航效率方面均有显著提升。具体性能数据和对比基线在论文中进行了详细展示。
🎯 应用场景
该研究成果可应用于各种需要安全导航的机器人系统,例如自动驾驶汽车、无人机、服务机器人和工业机器人。通过结合控制屏障函数和强化学习,可以提高机器人在复杂和动态环境中安全可靠运行的能力,降低事故风险,提升整体性能。
📄 摘要(原文)
Control Barrier Functions (CBFs) have emerged as a prominent approach to designing safe navigation systems of robots. Despite their popularity, current CBF-based methods exhibit some limitations: optimization-based safe control techniques tend to be either myopic or computationally intensive, and they rely on simplified system models; conversely, the learning-based methods suffer from the lack of quantitative indication in terms of navigation performance and safety. In this paper, we present a new model-free reinforcement learning algorithm called Certificated Actor-Critic (CAC), which introduces a hierarchical reinforcement learning framework and well-defined reward functions derived from CBFs. We carry out theoretical analysis and proof of our algorithm, and propose several improvements in algorithm implementation. Our analysis is validated by two simulation experiments, showing the effectiveness of our proposed CAC algorithm.