Mobile Manipulation Instruction Generation from Multiple Images with Automatic Metric Enhancement
作者: Kei Katsumata, Motonari Kambara, Daichi Yashima, Ryosuke Korekata, Komei Sugiura
分类: cs.RO
发布日期: 2025-01-28
备注: Accepted for IEEE RA-L 2025
💡 一句话要点
提出一种基于多图和自动指标增强的移动操作指令生成方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 移动操作 指令生成 多模态学习 自动评估指标 机器人操作
📋 核心要点
- 现有图像描述模型针对单图优化,难以生成适用于移动操作的指令。
- 提出一种多图输入模型,并结合学习和n-gram的自动评估指标作为奖励进行训练。
- 实验表明,该方法在自动评估指标上优于现有模型,并能提升多模态语言理解模型的性能。
📝 摘要(中文)
本文研究了基于目标物体图像和容器图像生成自由形式的移动操作指令的问题。传统的图像描述模型通常针对单张图像进行优化,因此无法生成合适的指令。本文提出了一种能够同时处理目标物体和容器图像的模型,用于生成移动操作任务的自由形式指令语句。此外,我们还引入了一种新颖的训练方法,该方法有效地将基于学习和基于n-gram的自动评估指标的分数作为奖励纳入其中。这种方法使模型能够学习单词之间的共现关系和适当的释义。结果表明,我们提出的方法在标准自动评估指标上优于包括代表性的多模态大型语言模型在内的基线方法。此外,物理实验表明,使用我们的方法来扩充语言指令数据可以提高现有用于移动操作的多模态语言理解模型的性能。
🔬 方法详解
问题定义:论文旨在解决移动操作任务中,如何根据目标物体图像和容器图像自动生成自然语言指令的问题。现有图像描述模型通常只处理单张图像,无法有效捕捉目标物体与容器之间的关系,导致生成的指令不准确或不完整。此外,如何有效地训练模型生成符合人类习惯的指令也是一个挑战。
核心思路:论文的核心思路是构建一个能够同时处理目标物体和容器图像的多模态模型,并利用自动评估指标作为奖励信号来指导模型的训练。通过这种方式,模型可以学习到目标物体和容器之间的关联,并生成更准确、更自然的指令。同时,利用自动评估指标可以避免人工标注的成本,并提高训练效率。
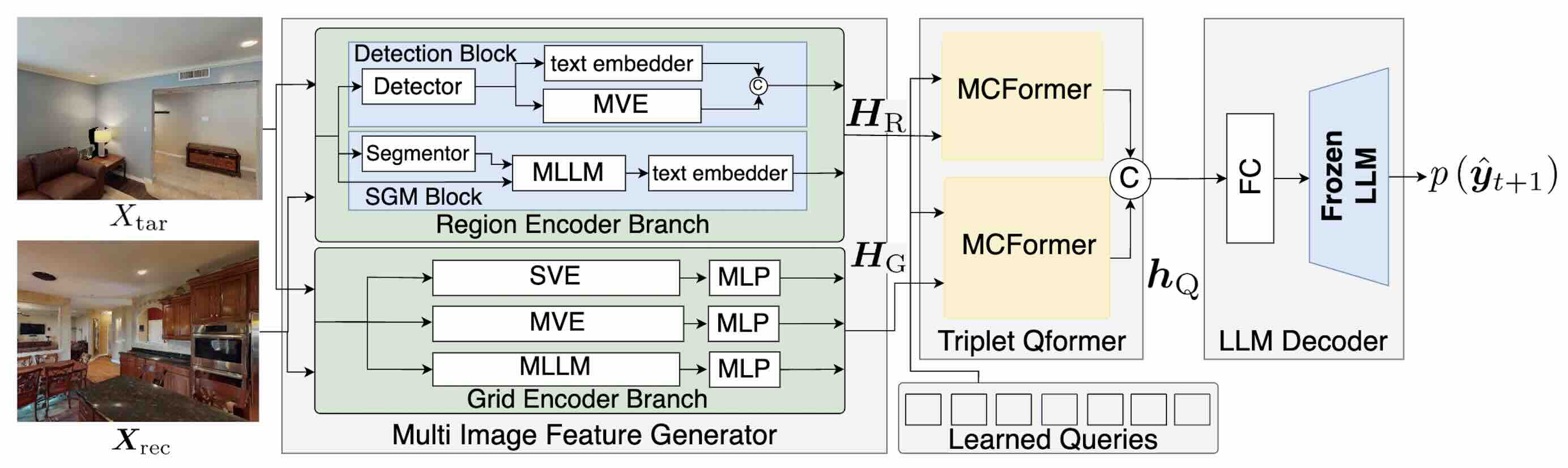
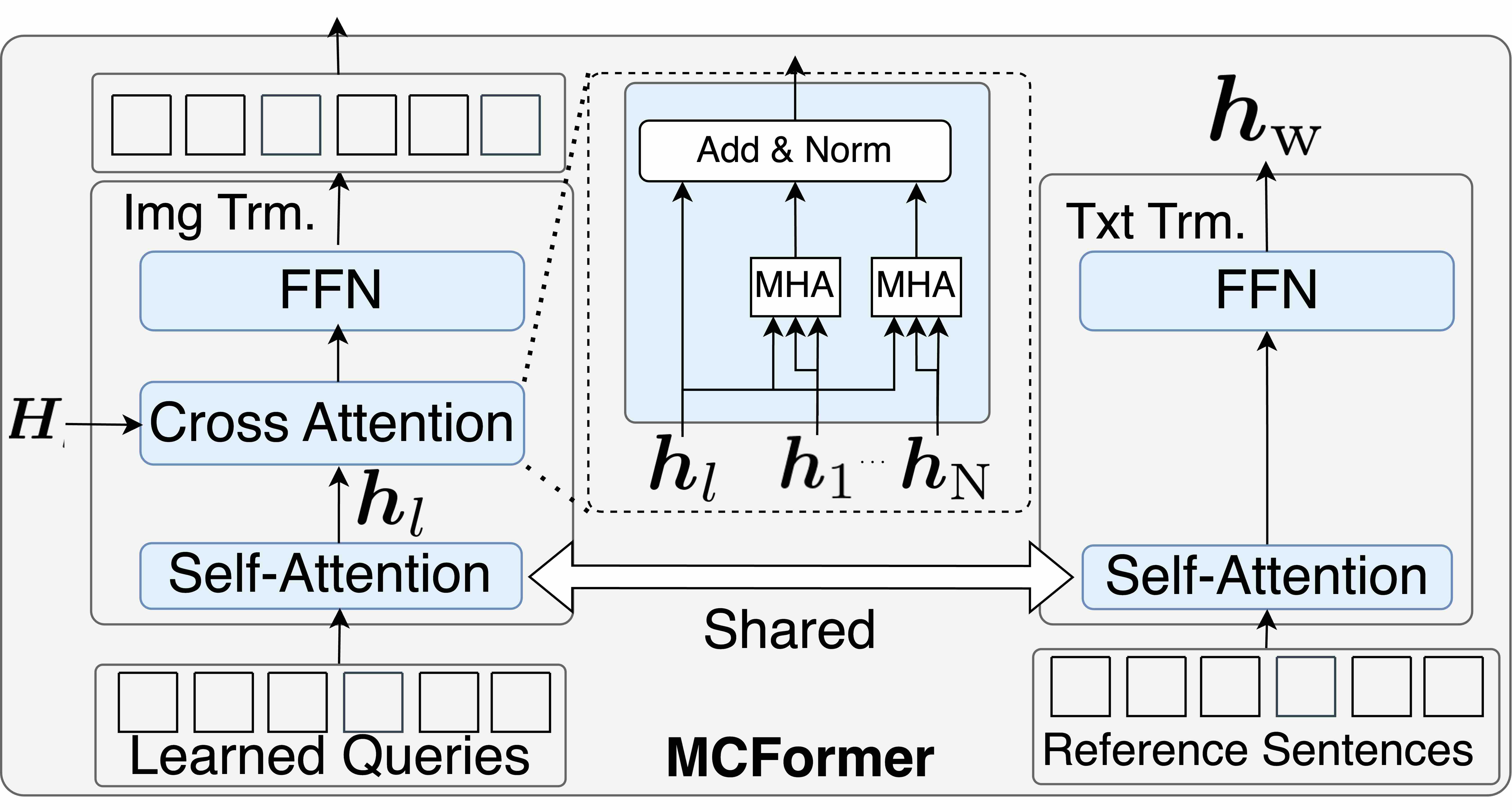
技术框架:该方法包含一个多模态编码器-解码器框架。编码器接收目标物体图像和容器图像作为输入,提取视觉特征。解码器则利用这些视觉特征生成自然语言指令。训练过程中,模型生成的指令会通过自动评估指标(例如BLEU、ROUGE等)进行评估,并将评估分数作为奖励信号反馈给模型,用于调整模型的参数。
关键创新:该方法的关键创新在于将自动评估指标作为奖励信号引入到指令生成模型的训练中。传统的训练方法通常依赖于人工标注的数据,而该方法可以利用自动评估指标来指导模型的训练,从而避免了人工标注的成本,并提高了训练效率。此外,该方法还能够学习单词之间的共现关系和适当的释义,从而生成更自然、更符合人类习惯的指令。
关键设计:论文中使用了基于Transformer的编码器-解码器架构。编码器部分,图像特征提取可以使用预训练的CNN模型(例如ResNet)或Transformer模型(例如ViT)。解码器部分,可以使用标准的Transformer解码器。奖励函数的设计至关重要,需要综合考虑多个自动评估指标,并进行适当的加权。此外,还可以使用强化学习算法(例如REINFORCE)来优化模型的参数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在标准自动评估指标(例如BLEU、ROUGE)上优于包括代表性的多模态大型语言模型在内的基线方法。此外,物理实验表明,使用该方法生成的数据可以有效提升现有用于移动操作的多模态语言理解模型的性能,验证了该方法的有效性和实用性。
🎯 应用场景
该研究成果可应用于机器人操作、自动化装配、智能家居等领域。例如,在机器人操作中,可以利用该方法生成指导机器人完成特定任务的指令,提高机器人的自主性和智能化水平。在智能家居领域,可以生成指导用户操作家电设备的指令,提升用户体验。
📄 摘要(原文)
We consider the problem of generating free-form mobile manipulation instructions based on a target object image and receptacle image. Conventional image captioning models are not able to generate appropriate instructions because their architectures are typically optimized for single-image. In this study, we propose a model that handles both the target object and receptacle to generate free-form instruction sentences for mobile manipulation tasks. Moreover, we introduce a novel training method that effectively incorporates the scores from both learning-based and n-gram based automatic evaluation metrics as rewards. This method enables the model to learn the co-occurrence relationships between words and appropriate paraphrases. Results demonstrate that our proposed method outperforms baseline methods including representative multimodal large language models on standard automatic evaluation metrics. Moreover, physical experiments reveal that using our method to augment data on language instructions improves the performance of an existing multimodal language understanding model for mobile manipulation.