An Atomic Skill Library Construction Method for Data-Efficient Embodied Manipulation
作者: Dongjiang Li, Bo Peng, Chang Li, Ning Qiao, Qi Zheng, Lei Sun, Yusen Qin, Bangguo Li, Yifeng Luan, Bo Wu, Yibing Zhan, Mingang Sun, Tong Xu, Lusong Li, Hui Shen, Xiaodong He
分类: cs.RO
发布日期: 2025-01-25 (更新: 2025-02-05)
💡 一句话要点
提出一种数据高效的具身操作原子技能库构建方法,提升泛化能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 具身操作 原子技能 技能库 视觉-语言-规划 视觉-语言-动作 数据高效 机器人学习
📋 核心要点
- 现有具身操作模型在复杂环境中泛化性差,且端到端训练需要大量数据。
- 提出三轮数据驱动方法构建原子技能库,将任务分解为可复用的原子技能。
- 实验表明,该方法显著降低数据需求,同时保持高性能并能有效适应新任务。
📝 摘要(中文)
具身操作是具身人工智能领域的一项基本能力。尽管当前的具身操作模型在特定环境中表现出一定的泛化能力,但由于现实场景的复杂性和多样性,它们在新环境和任务中表现不佳。传统的端到端数据收集和训练方式导致大量的数据需求。将端到端任务分解为原子技能有助于减少数据需求并提高任务成功率。然而,现有方法受到预定义技能集的限制,无法动态更新。为了解决这个问题,我们引入了一种三轮数据驱动的方法来构建原子技能库。我们使用视觉-语言-规划(VLP)将任务分解为子任务。然后,通过抽象子任务来形成原子技能定义。最后,通过数据收集和视觉-语言-动作(VLA)微调来构建原子技能库。随着原子技能库通过三轮更新策略动态扩展,它可以覆盖的任务范围自然增长。通过这种方式,我们的方法将重点从端到端任务转移到原子技能,从而显著降低数据成本,同时保持高性能,并能够有效地适应新任务。在真实环境中的大量实验证明了我们方法的有效性和效率。
🔬 方法详解
问题定义:现有具身操作模型在面对新的环境和任务时,泛化能力不足。传统的端到端训练方式需要大量的数据,成本高昂。此外,已有的原子技能方法依赖于预定义的技能集合,无法动态更新和扩展,限制了其适应性和覆盖范围。
核心思路:论文的核心思路是将复杂的具身操作任务分解为一系列更小的、可复用的原子技能。通过构建一个动态扩展的原子技能库,模型可以根据任务需求灵活组合这些原子技能,从而提高泛化能力和数据效率。这种方法将学习的重点从整个任务转移到更小的、更通用的技能单元上。
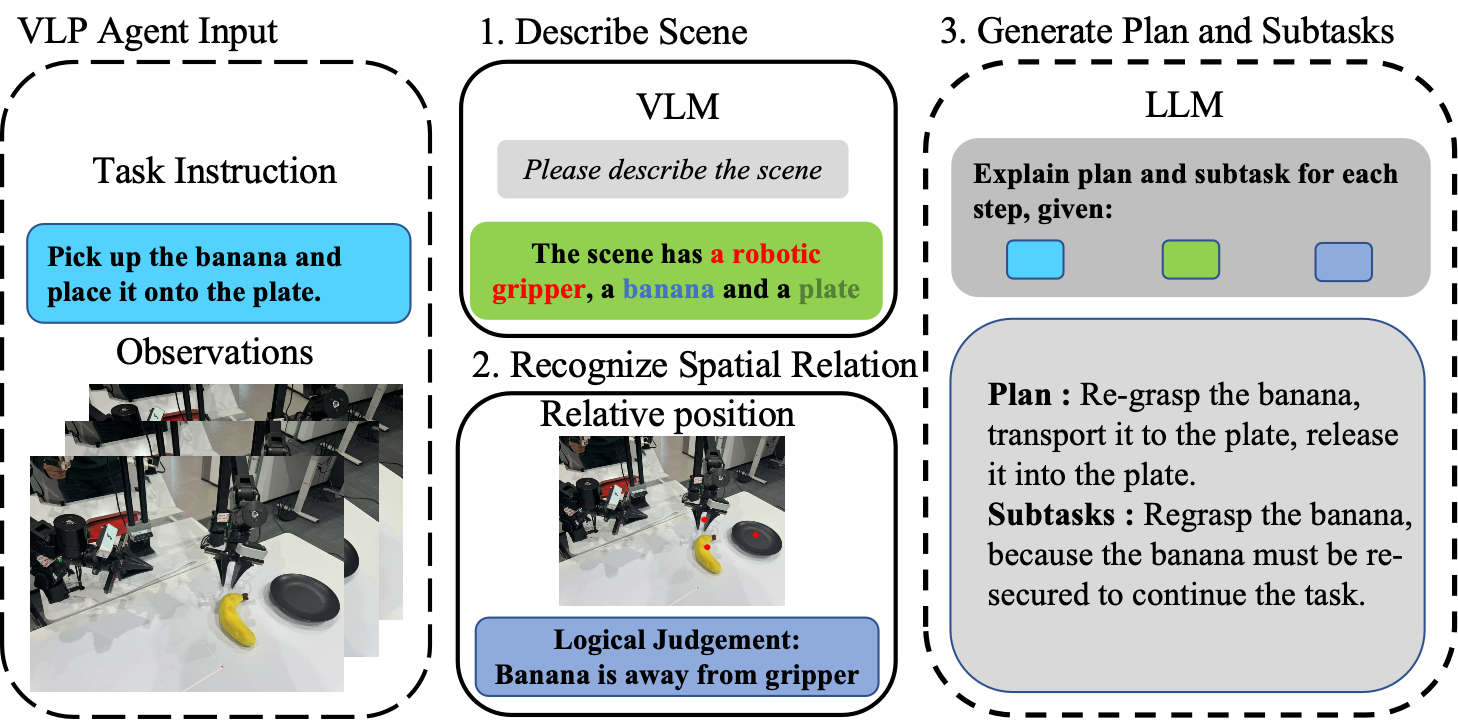
技术框架:该方法采用三轮数据驱动的框架来构建原子技能库。第一轮,使用视觉-语言-规划(VLP)模型将任务分解为子任务。第二轮,对子任务进行抽象,形成原子技能的定义。第三轮,通过数据收集和视觉-语言-动作(VLA)微调来训练和完善原子技能。随着技能库的扩展,模型可以覆盖的任务范围也随之增长。
关键创新:该方法的关键创新在于其动态扩展的原子技能库和三轮数据驱动的构建流程。与传统的预定义技能集合方法不同,该方法能够根据实际任务需求动态地添加和更新原子技能,从而提高了模型的适应性和泛化能力。此外,VLP和VLA模型的结合使得模型能够理解任务的语义信息,并将其转化为具体的动作指令。
关键设计:VLP模型用于将任务分解为子任务,其输出作为原子技能定义的依据。VLA模型用于学习原子技能的执行策略,其输入包括视觉信息、语言指令和当前状态,输出为具体的动作指令。损失函数的设计旨在鼓励模型学习到具有泛化能力的原子技能,例如,可以使用对比学习或模仿学习的方法来训练VLA模型。
🖼️ 关键图片


📊 实验亮点
论文在真实环境中进行了大量实验,验证了该方法的有效性和效率。实验结果表明,该方法能够在显著降低数据需求的同时,保持较高的任务成功率。与传统的端到端方法相比,该方法能够更快地适应新的任务,并具有更好的泛化能力。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于各种需要具身智能的场景,例如家庭服务机器人、工业自动化、医疗辅助机器人等。通过构建可扩展的原子技能库,机器人可以更高效地学习和执行各种复杂任务,从而提高其在实际应用中的可用性和智能化水平。该方法还有助于降低机器人开发的成本和周期,促进具身智能技术的普及。
📄 摘要(原文)
Embodied manipulation is a fundamental ability in the realm of embodied artificial intelligence. Although current embodied manipulation models show certain generalizations in specific settings, they struggle in new environments and tasks due to the complexity and diversity of real-world scenarios. The traditional end-to-end data collection and training manner leads to significant data demands. Decomposing end-to-end tasks into atomic skills helps reduce data requirements and improves the task success rate. However, existing methods are limited by predefined skill sets that cannot be dynamically updated. To address the issue, we introduce a three-wheeled data-driven method to build an atomic skill library. We divide tasks into subtasks using the Vision-Language-Planning (VLP). Then, atomic skill definitions are formed by abstracting the subtasks. Finally, an atomic skill library is constructed via data collection and Vision-Language-Action (VLA) fine-tuning. As the atomic skill library expands dynamically with the three-wheel update strategy, the range of tasks it can cover grows naturally. In this way, our method shifts focus from end-to-end tasks to atomic skills, significantly reducing data costs while maintaining high performance and enabling efficient adaptation to new tasks. Extensive experiments in real-world settings demonstrate the effectiveness and efficiency of our approach.