Dream to Fly: Model-Based Reinforcement Learning for Vision-Based Drone Flight
作者: Angel Romero, Ashwin Shenai, Ismail Geles, Elie Aljalbout, Davide Scaramuzza
分类: cs.RO
发布日期: 2025-01-24
备注: 11 pages, 7 Figures
💡 一句话要点
提出基于DreamerV3的视觉无人机模型强化学习方法,实现端到端自主飞行。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无人机 强化学习 模型预测控制 视觉控制 自主飞行
📋 核心要点
- 现有基于视觉的无人机控制依赖中间表示或模仿学习,限制了其泛化性和自主性。
- 利用DreamerV3,直接从原始像素学习控制策略,无需人工设计的奖励函数或中间状态估计。
- 实验表明,该方法在模拟和真实环境中均能实现敏捷飞行,优于传统无模型强化学习方法。
📝 摘要(中文)
自主无人机竞速已成为测试学习、感知、规划和控制极限的机器人基准。优秀的人类飞行员能够通过将来自单个机载摄像头的实时信息直接映射到控制指令,从而敏捷地驾驶无人机通过赛道。最近在自主无人机竞速方面的工作,试图采用直接的像素到命令控制策略(没有显式状态估计),依赖于简化观察空间的中间表示,或者使用模仿学习(IL)进行大量的引导。本文提出了一种从头开始学习策略的方法,使四旋翼飞行器能够像人类飞行员一样,通过直接将原始机载摄像头像素映射到控制命令,从而自主导航赛道。通过利用基于模型的强化学习(RL)——特别是DreamerV3——我们训练了能够仅使用原始像素观察进行敏捷飞行的视觉运动策略。虽然诸如PPO之类的无模型RL方法在这种条件下难以学习,但DreamerV3有效地获得了复杂的视觉运动行为。此外,由于我们的策略直接从像素输入中学习,因此不再需要先前RL方法中使用的感知感知奖励项来指导训练过程。我们的实验在模拟和真实飞行中都证明了所提出的方法如何部署在敏捷四旋翼飞行器上。这种方法推进了基于视觉的自主飞行的前沿,并表明基于模型的RL是现实世界机器人技术的一个有希望的方向。
🔬 方法详解
问题定义:现有基于视觉的无人机自主飞行方法,通常依赖于人工设计的中间表示(如光流、深度图)来简化视觉输入,或者需要大量的模仿学习数据进行引导。这些方法限制了无人机的泛化能力和自主性,难以适应复杂环境和未知赛道。此外,设计合适的奖励函数来指导强化学习训练也是一个挑战。
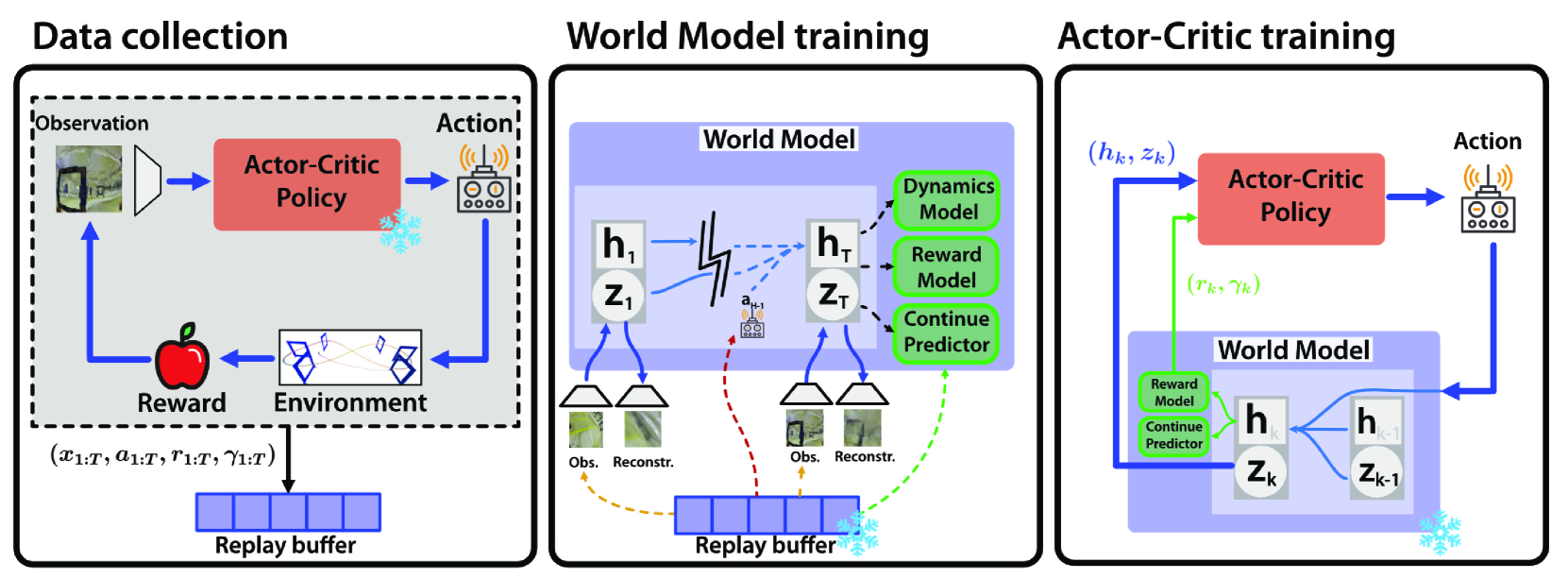
核心思路:本文的核心思路是利用基于模型的强化学习算法DreamerV3,直接从原始像素输入学习无人机的控制策略。DreamerV3通过学习环境的内部模型,可以有效地进行长期规划和探索,从而克服了传统无模型强化学习方法在视觉控制任务中的困难。这种端到端的学习方式避免了人工设计中间表示和奖励函数,提高了无人机的自主性和适应性。
技术框架:整体框架包括三个主要模块:(1) 视觉编码器:将原始像素输入编码成低维的潜在状态表示。(2) 世界模型:学习环境的动态模型,包括状态转移概率和奖励函数。(3) 策略网络:根据世界模型预测的未来状态,生成无人机的控制指令。训练过程采用DreamerV3算法,通过最大化累积奖励来优化策略网络和世界模型。
关键创新:最重要的技术创新点在于将DreamerV3应用于视觉无人机控制,实现了端到端的自主飞行。与现有方法相比,该方法无需人工设计中间表示和奖励函数,可以直接从原始像素学习控制策略。此外,DreamerV3的模型预测能力使得无人机能够进行长期规划,从而实现更敏捷和高效的飞行。
关键设计:视觉编码器采用卷积神经网络,将原始像素输入编码成低维的潜在状态表示。世界模型采用循环神经网络,学习环境的动态模型。策略网络采用多层感知机,根据世界模型预测的未来状态,生成无人机的控制指令。损失函数包括重构损失、KL散度和奖励预测损失,用于优化视觉编码器、世界模型和策略网络。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
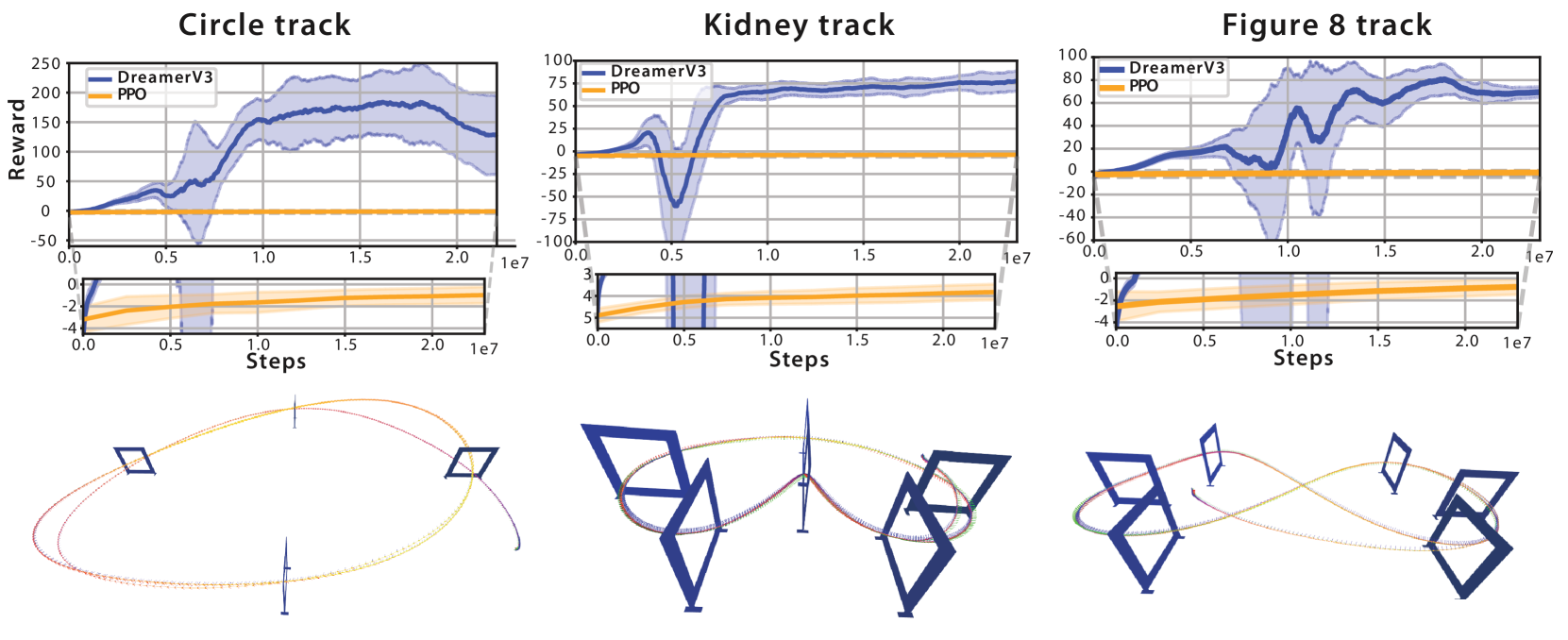
实验结果表明,该方法在模拟和真实环境中均能实现敏捷飞行。在模拟环境中,该方法能够成功完成赛道导航任务,并取得优于传统无模型强化学习方法(如PPO)的性能。在真实环境中,该方法也能够成功部署在敏捷四旋翼飞行器上,实现自主飞行。具体的性能数据未知。
🎯 应用场景
该研究成果可应用于无人机竞速、自主巡检、灾害救援、物流配送等领域。通过端到端的视觉学习,无人机能够更好地适应复杂环境,实现更高效、更安全的自主飞行。未来,该技术有望推动无人机在更多领域的应用,并促进机器人技术的进一步发展。
📄 摘要(原文)
Autonomous drone racing has risen as a challenging robotic benchmark for testing the limits of learning, perception, planning, and control. Expert human pilots are able to agilely fly a drone through a race track by mapping the real-time feed from a single onboard camera directly to control commands. Recent works in autonomous drone racing attempting direct pixel-to-commands control policies (without explicit state estimation) have relied on either intermediate representations that simplify the observation space or performed extensive bootstrapping using Imitation Learning (IL). This paper introduces an approach that learns policies from scratch, allowing a quadrotor to autonomously navigate a race track by directly mapping raw onboard camera pixels to control commands, just as human pilots do. By leveraging model-based reinforcement learning~(RL) - specifically DreamerV3 - we train visuomotor policies capable of agile flight through a race track using only raw pixel observations. While model-free RL methods such as PPO struggle to learn under these conditions, DreamerV3 efficiently acquires complex visuomotor behaviors. Moreover, because our policies learn directly from pixel inputs, the perception-aware reward term employed in previous RL approaches to guide the training process is no longer needed. Our experiments demonstrate in both simulation and real-world flight how the proposed approach can be deployed on agile quadrotors. This approach advances the frontier of vision-based autonomous flight and shows that model-based RL is a promising direction for real-world robotics.