Learning to Hop for a Single-Legged Robot with Parallel Mechanism
作者: Hongbo Zhang, Xiangyu Chu, Yanlin Chen, Yunxi Tang, Linzhu Yue, Yun-Hui Liu, Kwok Wai Samuel Au
分类: cs.RO
发布日期: 2025-01-21
💡 一句话要点
提出一种基于强化学习的单腿并联机器人跳跃控制方法,解决仿真和实际部署难题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 并联机器人 跳跃控制 Sim-to-Real 机器人控制
📋 核心要点
- 并联机构由于其复杂的运动学约束和闭环结构,难以进行精确的仿真,这给基于仿真的强化学习控制带来了挑战。
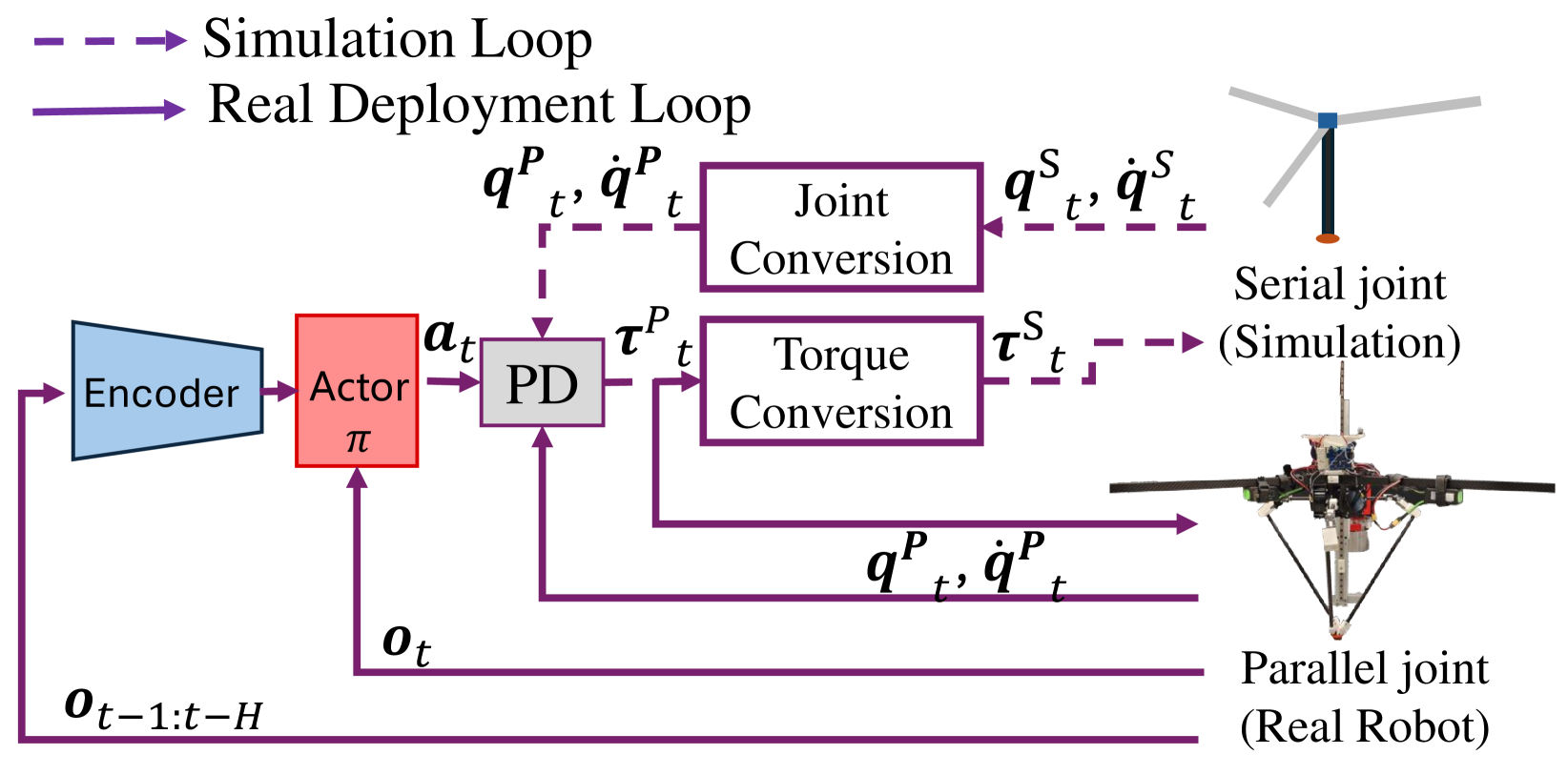
- 论文提出一种学习框架,通过编码长时历史反馈来解决空中阶段的欠驱动问题,并使用简化的串联配置来避免直接仿真并联结构。
- 通过仿真和硬件实验验证了该框架的有效性,表明该方法能够成功地应用于实际的单腿并联机器人跳跃控制。
📝 摘要(中文)
本文提出了一种利用强化学习来提升具有并联机构的高动态跳跃系统性能的方法。与串联机构不同,并联机构由于其运动学约束和闭环结构的复杂性,难以进行精确的仿真。此外,跳跃学习面临着长时间的空中阶段和稀疏奖励的问题。为了解决这些问题,我们提出了一个学习框架,该框架对长时历史反馈进行编码,以解决长时间空中阶段带来的欠驱动问题。在该框架中,我们还为并联设计引入了一个简化的串联配置,以避免在训练期间直接仿真并联结构。设计了一种扭矩级别的转换来处理并联-串联转换,以解决从仿真到实际的问题。仿真和硬件实验验证了该框架的有效性。
🔬 方法详解
问题定义:论文旨在解决单腿并联机器人的跳跃控制问题。现有方法在处理并联机构时,由于其复杂的运动学约束和闭环结构,难以进行精确的仿真,导致仿真结果与实际情况存在较大差异。此外,跳跃运动中存在较长的空中阶段,导致系统欠驱动,以及奖励信号稀疏,使得强化学习训练更加困难。
核心思路:论文的核心思路是利用强化学习,通过编码长时历史反馈来解决空中阶段的欠驱动问题,并使用简化的串联配置来避免直接仿真并联结构。通过这种方式,可以在仿真环境中有效地训练控制器,并将其迁移到实际机器人上。
技术框架:整体框架包括以下几个主要模块:1) 简化模型:将并联机构简化为串联机构,以降低仿真难度。2) 强化学习训练:使用强化学习算法训练控制器,使其能够控制机器人的跳跃运动。3) 扭矩转换:设计扭矩级别的转换,将串联模型的控制指令转换为并联机构的实际控制指令。4) 仿真环境:构建仿真环境,用于训练和验证控制器。5) 硬件实验:在实际机器人上进行实验,验证控制器的有效性。
关键创新:论文的关键创新点在于:1) 提出了一种针对并联机构的简化建模方法,避免了直接仿真复杂并联结构的难题。2) 设计了一种长时历史反馈编码机制,解决了空中阶段的欠驱动问题。3) 提出了一种扭矩级别的转换方法,实现了从仿真到实际的有效迁移。
关键设计:论文的关键设计包括:1) 并联机构的简化方式:具体如何将并联机构简化为串联机构,需要详细说明简化过程和假设。2) 强化学习算法的选择:选择合适的强化学习算法,例如PPO、SAC等,并调整超参数以获得最佳性能。3) 奖励函数的设计:设计合适的奖励函数,鼓励机器人实现期望的跳跃高度和距离,并惩罚不稳定的运动。4) 扭矩转换的具体实现:详细说明扭矩转换的数学公式和实现方法,确保控制指令的准确传递。
🖼️ 关键图片


📊 实验亮点
仿真实验和硬件实验验证了所提出框架的有效性。具体而言,该方法能够使单腿并联机器人在仿真环境中稳定跳跃,并且通过扭矩转换,成功地将训练好的控制器迁移到实际机器人上,实现了稳定的跳跃运动。虽然论文中没有给出具体的性能数据和提升幅度,但实验结果表明该方法具有良好的可行性和有效性。
🎯 应用场景
该研究成果可应用于各种需要高动态运动的并联机器人系统,例如跳跃机器人、仿生机器人和外骨骼机器人。通过强化学习方法,可以实现对这些复杂系统的精确控制,提高其运动性能和适应性,在搜索救援、物流运输和康复医疗等领域具有潜在的应用价值。
📄 摘要(原文)
This work presents the application of reinforcement learning to improve the performance of a highly dynamic hopping system with a parallel mechanism. Unlike serial mechanisms, parallel mechanisms can not be accurately simulated due to the complexity of their kinematic constraints and closed-loop structures. Besides, learning to hop suffers from prolonged aerial phase and the sparse nature of the rewards. To address them, we propose a learning framework to encode long-history feedback to account for the under-actuation brought by the prolonged aerial phase. In the proposed framework, we also introduce a simplified serial configuration for the parallel design to avoid directly simulating parallel structure during the training. A torque-level conversion is designed to deal with the parallel-serial conversion to handle the sim-to-real issue. Simulation and hardware experiments have been conducted to validate this framework.