A Survey of World Models for Autonomous Driving
作者: Tuo Feng, Wenguan Wang, Yi Yang
分类: cs.RO, cs.CV
发布日期: 2025-01-20 (更新: 2025-09-10)
备注: Ongoing project. Paper list: https://github.com/FengZicai/AwesomeWMAD Benchmark: https://github.com/FengZicai/WMAD-Benchmarks
💡 一句话要点
综述自动驾驶世界模型,提出三层分类体系,分析训练范式与未来挑战。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 世界模型 行为规划 运动预测 多模态融合
📋 核心要点
- 现有自动驾驶方法在复杂动态场景理解和安全决策方面存在不足,难以准确预测未来状态。
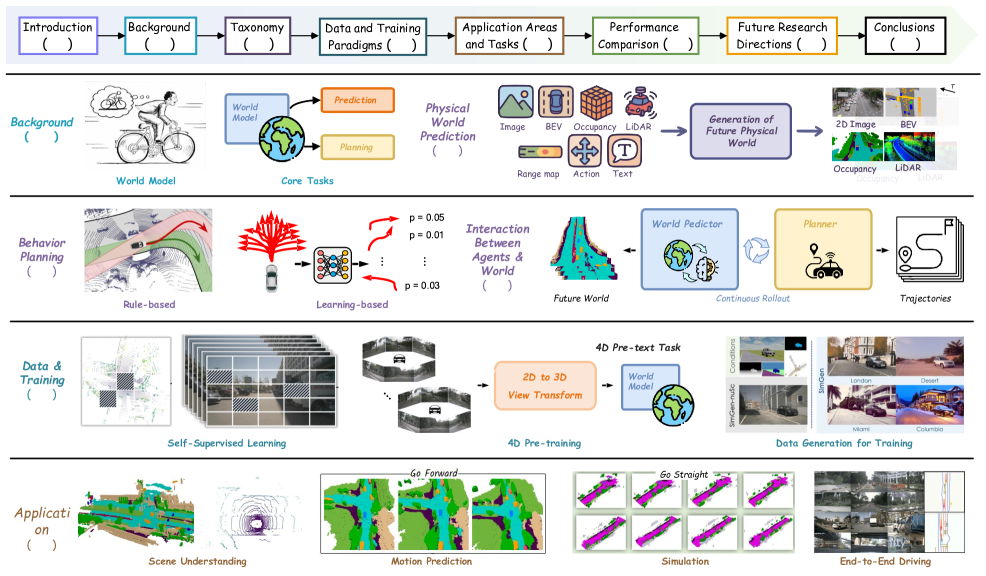
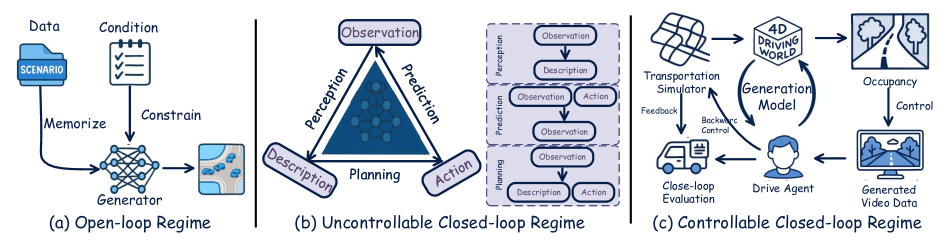
- 本文提出一个三层分类体系,涵盖世界模型的生成、规划和交互,并分析了训练范式。
- 分析了世界模型在场景理解和运动预测任务中的性能,并指出了未来研究方向。
📝 摘要(中文)
本文系统性地回顾了自动驾驶领域世界模型的最新进展,并提出了一个三层分类体系:(i) 未来物理世界的生成,涵盖了基于图像、BEV、OG和PC的生成方法,通过扩散模型和4D occupancy预测来增强场景演化建模;(ii) 智能体的行为规划,结合了规则驱动和学习驱动的范式,利用代价地图优化和强化学习在复杂交通条件下生成轨迹;(iii) 预测与规划之间的交互,通过潜在空间扩散和记忆增强架构实现多智能体协同决策。此外,本文还分析了训练范式,包括自监督学习、多模态预训练和生成式数据增强,并评估了世界模型在场景理解和运动预测任务中的性能。未来的研究必须解决自监督表征学习、多模态融合和高级仿真等关键挑战,以推动世界模型在复杂城市环境中的实际部署。总而言之,这项全面的分析为利用世界模型的变革潜力,推进安全可靠的自动驾驶解决方案提供了一个技术路线图。
🔬 方法详解
问题定义:现有自动驾驶方法难以准确建模复杂动态环境,尤其是在多智能体交互和长期预测方面存在挑战。痛点在于缺乏对未来场景演化的有效表示和推理能力,以及难以实现预测与规划的有效结合。
核心思路:本文的核心思路是对现有世界模型进行系统性梳理和分类,从生成、规划和交互三个层面理解其在自动驾驶中的作用。通过分析不同方法的优缺点,为未来的研究方向提供指导。
技术框架:本文构建了一个三层分类体系:(1) 未来物理世界的生成,关注如何利用各种模态的数据生成未来场景的表示;(2) 智能体的行为规划,研究如何利用世界模型进行轨迹生成和决策;(3) 预测与规划之间的交互,探讨如何实现多智能体之间的协同决策。
关键创新:本文的创新在于提出了一个全面的世界模型分类体系,并深入分析了各种训练范式和评估方法。此外,本文还指出了未来研究的关键挑战,例如自监督表征学习和多模态融合。
关键设计:本文主要关注对现有方法的归纳和分析,没有提出新的算法或模型。关键设计体现在对现有方法的分类和对未来研究方向的展望上,例如强调了自监督学习在提升表征能力方面的重要性,以及多模态融合在提升场景理解能力方面的潜力。
🖼️ 关键图片

📊 实验亮点
本文对现有世界模型进行了全面的综述和分类,并分析了不同训练范式和评估方法。虽然没有提供具体的性能数据,但通过对现有方法的优缺点分析,为未来的研究方向提供了有价值的指导,例如强调了自监督学习和多模态融合的重要性。
🎯 应用场景
该研究成果可应用于自动驾驶系统的感知、预测和规划模块,提升车辆在复杂交通环境下的安全性和可靠性。通过更精确的场景理解和未来预测,车辆可以做出更合理的决策,减少事故风险。此外,该研究也有助于开发更逼真的自动驾驶仿真平台,加速算法的迭代和验证。
📄 摘要(原文)
Recent breakthroughs in autonomous driving have been propelled by advances in robust world modeling, fundamentally transforming how vehicles interpret dynamic scenes and execute safe decision-making. World models have emerged as a linchpin technology, offering high-fidelity representations of the driving environment that integrate multi-sensor data, semantic cues, and temporal dynamics. This paper systematically reviews recent advances in world models for autonomous driving, proposing a three-tiered taxonomy: (i) Generation of Future Physical World, covering Image-, BEV-, OG-, and PC-based generation methods that enhance scene evolution modeling through diffusion models and 4D occupancy forecasting; (ii) Behavior Planning for Intelligent Agents, combining rule-driven and learning-based paradigms with cost map optimization and reinforcement learning for trajectory generation in complex traffic conditions; (ii) Interaction between Prediction and Planning, achieving multi-agent collaborative decision-making through latent space diffusion and memory-augmented architectures. The study further analyzes training paradigms, including self-supervised learning, multimodal pretraining, and generative data augmentation, while evaluating world models' performance in scene understanding and motion prediction tasks. Future research must address key challenges in self-supervised representation learning, multimodal fusion, and advanced simulation to advance the practical deployment of world models in complex urban environments. Overall, the comprehensive analysis provides a technical roadmap for harnessing the transformative potential of world models in advancing safe and reliable autonomous driving solutions.