Learning More With Less: Sample Efficient Model-Based RL for Loco-Manipulation
作者: Benjamin Hoffman, Jin Cheng, Chenhao Li, Stelian Coros
分类: cs.RO
发布日期: 2025-01-17 (更新: 2025-09-26)
💡 一句话要点
提出基于贝叶斯神经网络的Model-Based RL方法,高效解决Loco-Manipulation控制问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: Loco-Manipulation 模型预测控制 强化学习 贝叶斯神经网络 动力学模型学习 机器人控制
📋 核心要点
- 现有Loco-Manipulation平台控制复杂,商用平台黑盒特性导致难以获取精确动力学模型和鲁棒控制策略。
- 利用四足机器人手臂平台的运动学模型作为先验,结合贝叶斯神经网络高效学习动力学模型,再用强化学习生成控制策略。
- 在Boston Dynamics Spot上验证,即使在少量数据下,也能准确跟踪动态末端执行器轨迹,证明了方法的有效性。
📝 摘要(中文)
本文提出了一种基于模型的强化学习(RL)方法,用于解决Loco-Manipulation平台的控制难题。Loco-Manipulation平台结合了腿式运动的灵活性和机械臂的操作能力,在现实世界应用中具有巨大潜力。然而,Loco-Manipulation控制的复杂性以及商用平台的黑盒特性,给精确动力学模型的推导和鲁棒控制策略的设计带来了挑战。本文利用四足机器人手臂平台的运动学模型作为物理先验,并结合贝叶斯神经网络(BNN)的最新进展,从有限的数据中高效学习精确的动力学模型。然后,利用学习到的模型,通过RL推导出Loco-Manipulation的控制策略。在Boston Dynamics Spot等先进硬件上的实验结果表明,即使在低数据情况下,该方法也能准确地执行动态末端执行器轨迹跟踪。
🔬 方法详解
问题定义:论文旨在解决Loco-Manipulation平台在数据有限的情况下,难以学习精确动力学模型和鲁棒控制策略的问题。现有方法通常需要大量数据进行训练,或者难以处理商用平台的黑盒特性,导致控制性能不佳。
核心思路:论文的核心思路是利用先验知识(四足机器人手臂平台的运动学模型)来指导动力学模型的学习,从而减少对数据的需求。通过结合贝叶斯神经网络,可以有效地融合先验知识和观测数据,提高模型的学习效率和泛化能力。
技术框架:整体框架包含以下几个主要步骤:1) 构建四足机器人手臂平台的运动学模型;2) 利用贝叶斯神经网络学习动力学模型,其中运动学模型作为物理先验;3) 使用学习到的动力学模型,通过强化学习训练Loco-Manipulation的控制策略;4) 在真实机器人平台上进行实验验证。
关键创新:最重要的技术创新点在于将先验知识(运动学模型)融入到基于贝叶斯神经网络的动力学模型学习中。这种方法能够显著提高数据效率,使得在数据有限的情况下也能学习到精确的动力学模型。与传统的黑盒模型学习方法相比,该方法具有更好的可解释性和泛化能力。
关键设计:论文中,贝叶斯神经网络被用于建模动力学模型的不确定性,并利用变分推理进行训练。损失函数包括数据拟合项和正则化项,其中正则化项用于约束模型的复杂度,防止过拟合。强化学习算法采用Trust Region Policy Optimization (TRPO) 或 Proximal Policy Optimization (PPO) 等算法,以保证训练的稳定性。
🖼️ 关键图片

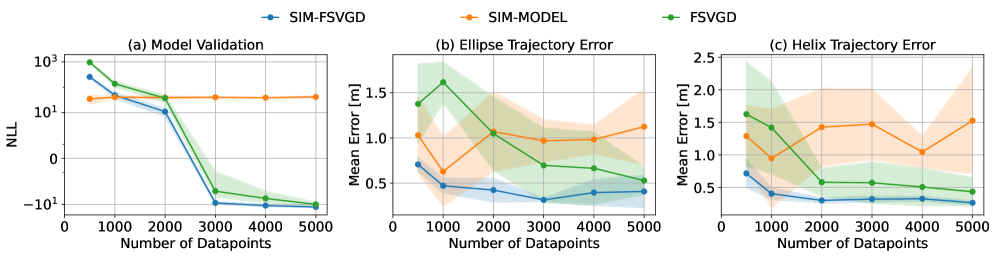
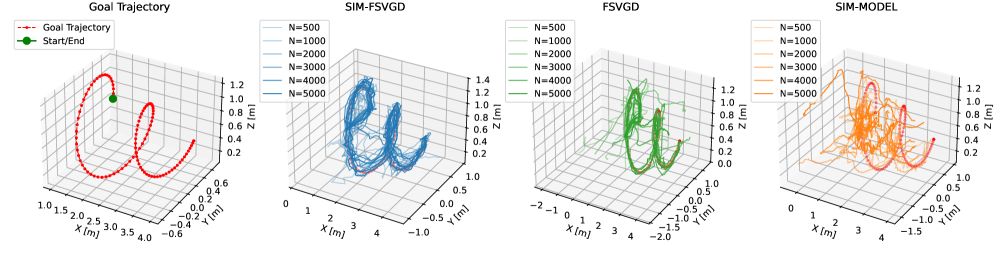
📊 实验亮点
实验结果表明,该方法在Boston Dynamics Spot上能够准确地执行动态末端执行器轨迹跟踪任务,即使在数据量较少的情况下也能取得良好的控制效果。与没有使用先验知识的传统方法相比,该方法能够显著提高数据效率,并在相同数据量下获得更高的控制精度。具体性能数据和对比基线在论文中进行了详细展示。
🎯 应用场景
该研究成果可应用于各种需要Loco-Manipulation能力的场景,例如:复杂环境下的搜救任务、工业自动化中的物料搬运、以及家庭服务机器人等。通过提高Loco-Manipulation平台的控制精度和鲁棒性,可以使其在更广泛的实际应用中发挥作用,并降低对大量训练数据的依赖,加速算法落地。
📄 摘要(原文)
By combining the agility of legged locomotion with the capabilities of manipulation, loco-manipulation platforms have the potential to perform complex tasks in real-world applications. To this end, state-of-the-art quadrupeds with manipulators, such as the Boston Dynamics Spot, have emerged to provide a capable and robust platform. However, the complexity of loco-manipulation control, as well as the black-box nature of commercial platforms, pose challenges for deriving accurate dynamics models and robust control policies. To address these challenges, we turn to model-based reinforcement learning (RL). We develop a hand-crafted kinematic model of a quadruped-with-arm platform which - employing recent advances in Bayesian Neural Network (BNN)-based learning - we use as a physical prior to efficiently learn an accurate dynamics model from limited data. We then leverage our learned model to derive control policies for loco-manipulation via RL. We demonstrate the effectiveness of our approach on state-of-the-art hardware using the Boston Dynamics Spot, accurately performing dynamic end-effector trajectory tracking even in low data regimes. Project website and videos: https://sites.google.com/view/learning-more-with-less.