DexForce: Extracting Force-informed Actions from Kinesthetic Demonstrations for Dexterous Manipulation
作者: Claire Chen, Zhongchun Yu, Hojung Choi, Mark Cutkosky, Jeannette Bohg
分类: cs.RO
发布日期: 2025-01-17 (更新: 2025-03-27)
备注: Videos can be found here: https://clairelc.github.io/dexforce.github.io/
💡 一句话要点
DexForce:从触觉示教中提取力感知的动作,用于灵巧操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 灵巧操作 模仿学习 触觉示教 力感知 机器人控制
📋 核心要点
- 现有灵巧操作演示方法在处理富含接触的任务时存在困难,主要原因是人-机器人运动重定向不直观且缺乏触觉反馈。
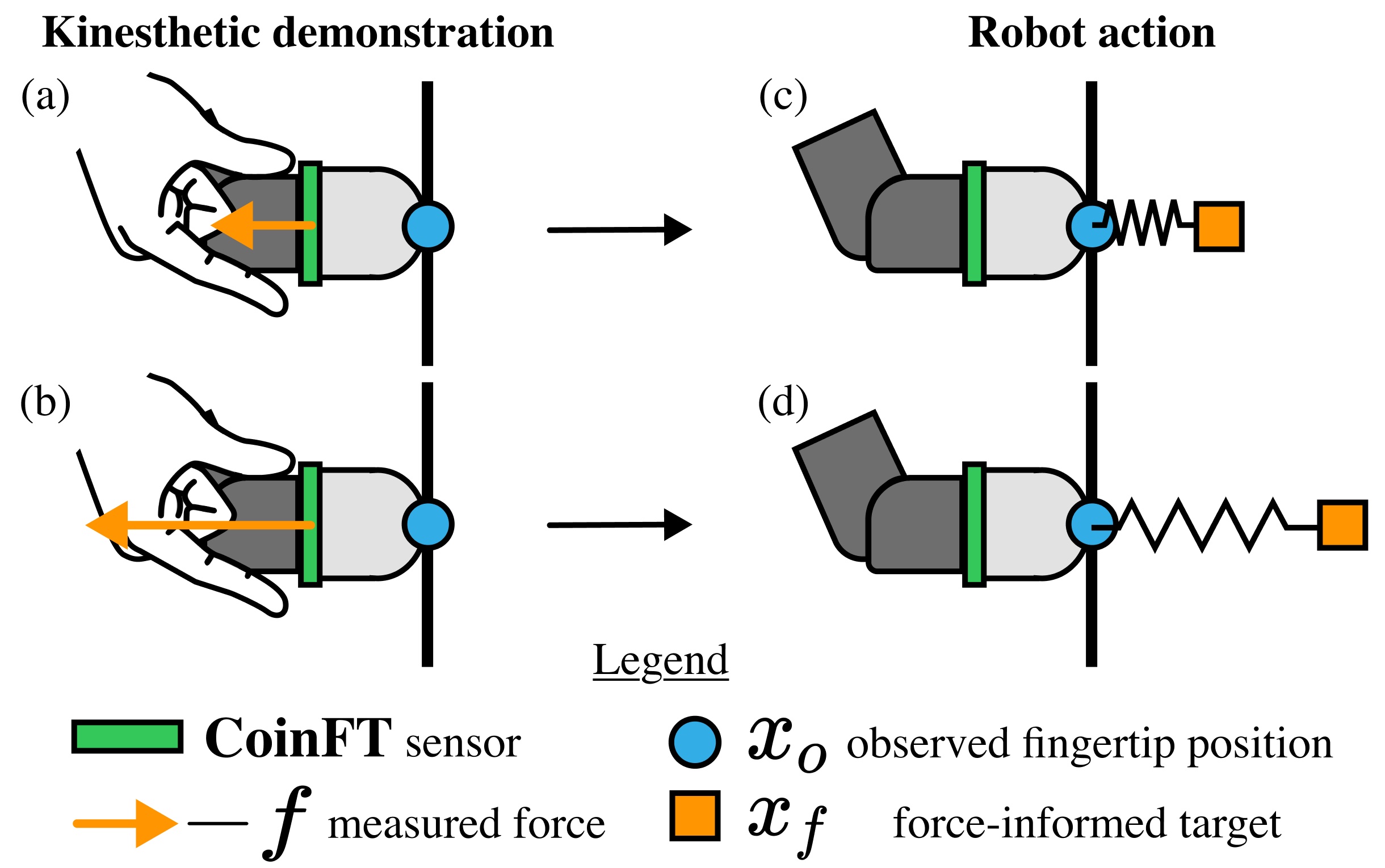
- DexForce利用触觉示教中测量的接触力来计算力感知的动作,从而为策略学习提供更有效的训练数据。
- 实验表明,基于DexForce生成的力感知动作训练的策略在多个任务上取得了显著的成功率提升,平均成功率达到76%。
📝 摘要(中文)
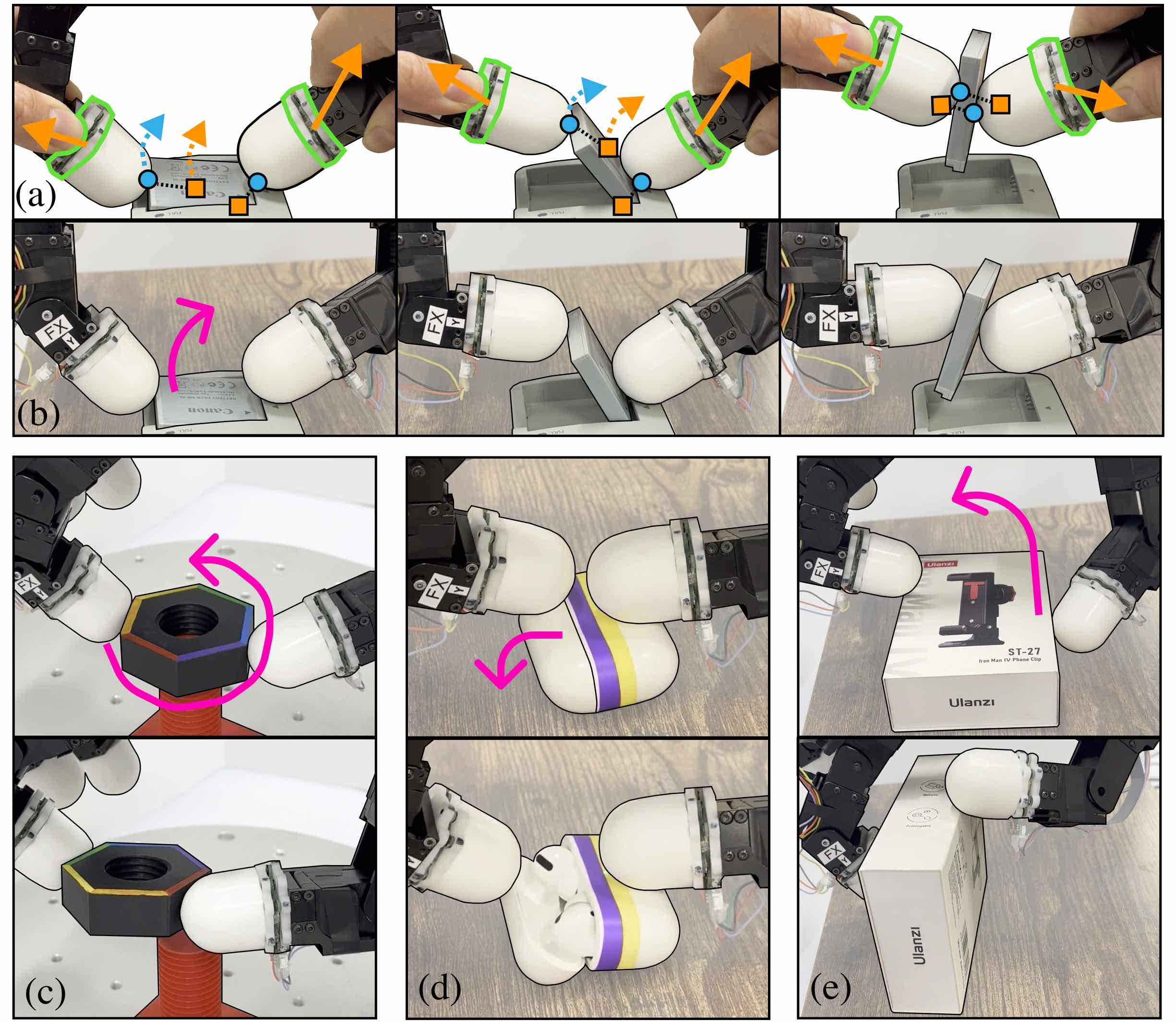
模仿学习需要高质量的演示数据,包含状态-动作序列。对于需要灵巧性的、富含接触的灵巧操作任务,这些状态-动作对中的动作必须产生正确的力。目前广泛使用的灵巧操作演示收集方法难以用于演示富含接触的任务,因为人-机器人运动重定向不直观,并且缺乏直接的触觉反馈。为了解决这些问题,我们提出了DexForce。DexForce利用在触觉示教期间测量的接触力来计算力感知的动作,用于策略学习。我们收集了六个任务的演示数据,并表明基于我们的力感知动作训练的策略在所有任务中实现了平均76%的成功率。相比之下,直接基于未考虑接触力的动作训练的策略的成功率接近于零。我们还进行了一项研究,消融了策略观察中包含力数据的影响。我们发现,使用力数据永远不会损害策略的性能,但对于需要高级精度和协调的任务(如打开AirPods外壳和拧开螺母)的帮助最大。
🔬 方法详解
问题定义:论文旨在解决灵巧操作任务中,现有模仿学习方法难以有效利用触觉示教数据的问题。现有方法在处理富含接触的任务时,由于缺乏直接的触觉反馈和不直观的运动重定向,导致学习到的策略难以产生正确的力,从而影响任务成功率。
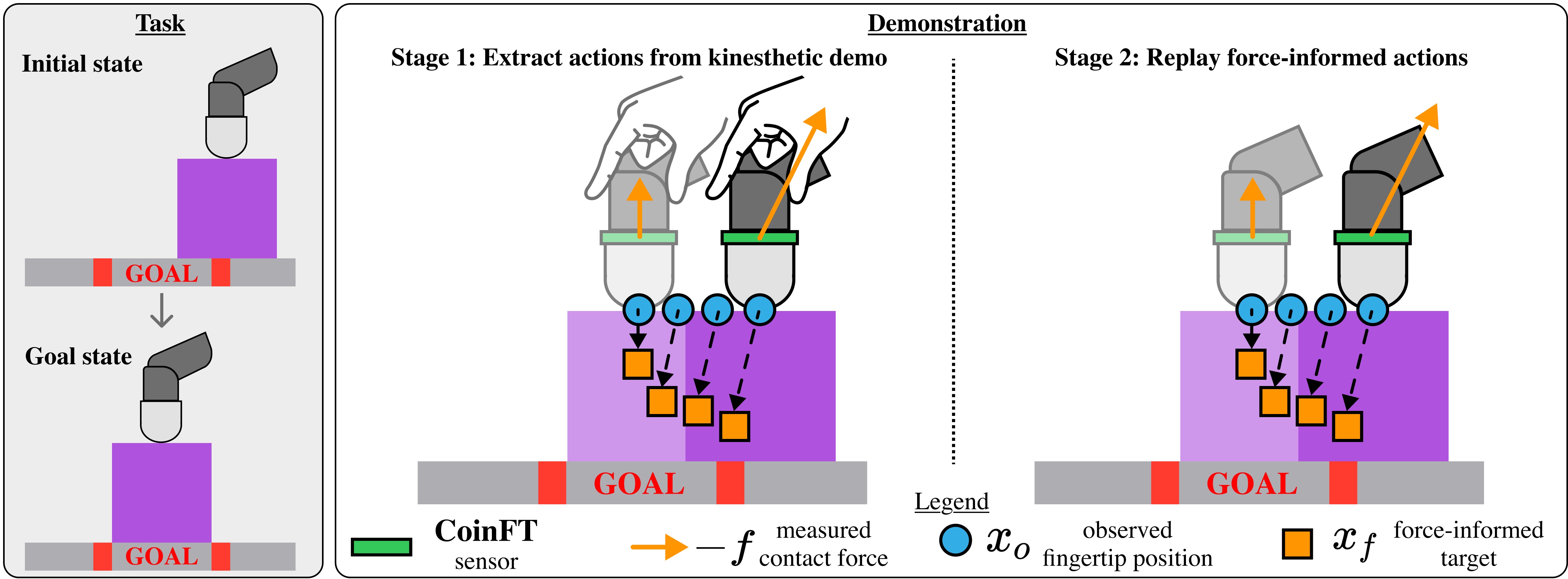
核心思路:论文的核心思路是利用触觉示教过程中采集到的接触力信息,将其融入到动作的表示中,从而使学习到的策略能够更好地理解和控制与环境的交互力。通过这种方式,策略可以学习到更精确和有效的动作,从而提高任务的成功率。
技术框架:DexForce的技术框架主要包含以下几个阶段:1) 触觉示教数据采集:通过触觉传感器记录人操作过程中的运动轨迹和接触力信息。2) 力感知动作计算:利用采集到的接触力信息,计算出包含力信息的动作表示。3) 策略学习:使用包含力信息的动作表示作为训练数据,训练模仿学习策略。4) 策略评估:在真实机器人平台上评估学习到的策略的性能。
关键创新:论文的关键创新在于提出了力感知的动作表示方法,该方法能够有效地将接触力信息融入到动作中,从而使学习到的策略能够更好地理解和控制与环境的交互力。与现有方法相比,DexForce能够更有效地利用触觉示教数据,从而提高灵巧操作任务的成功率。
关键设计:论文中关于力感知动作计算的具体方法未知,摘要中没有详细描述。但是,可以推测其设计可能涉及到将接触力作为额外的输入特征,或者设计特定的损失函数来鼓励策略学习产生正确的力。具体的网络结构和参数设置未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于DexForce生成的力感知动作训练的策略在六个不同的灵巧操作任务中取得了显著的成功率提升,平均成功率达到76%。相比之下,直接基于未考虑接触力的动作训练的策略的成功率接近于零。此外,消融实验表明,在策略观察中包含力数据可以进一步提高策略的性能,尤其是在需要高级精度和协调的任务中。
🎯 应用场景
DexForce的研究成果可以应用于各种需要灵巧操作的机器人任务,例如装配、抓取、操作工具等。该方法可以提高机器人在复杂环境中的操作能力,使其能够更好地完成需要精确力和位置控制的任务。未来,该技术有望应用于工业自动化、医疗机器人等领域,提高生产效率和服务质量。
📄 摘要(原文)
Imitation learning requires high-quality demonstrations consisting of sequences of state-action pairs. For contact-rich dexterous manipulation tasks that require dexterity, the actions in these state-action pairs must produce the right forces. Current widely-used methods for collecting dexterous manipulation demonstrations are difficult to use for demonstrating contact-rich tasks due to unintuitive human-to-robot motion retargeting and the lack of direct haptic feedback. Motivated by these concerns, we propose DexForce. DexForce leverages contact forces, measured during kinesthetic demonstrations, to compute force-informed actions for policy learning. We collect demonstrations for six tasks and show that policies trained on our force-informed actions achieve an average success rate of 76% across all tasks. In contrast, policies trained directly on actions that do not account for contact forces have near-zero success rates. We also conduct a study ablating the inclusion of force data in policy observations. We find that while using force data never hurts policy performance, it helps most for tasks that require advanced levels of precision and coordination, like opening an AirPods case and unscrewing a nut.