Robotic World Model: A Neural Network Simulator for Robust Policy Optimization in Robotics
作者: Chenhao Li, Andreas Krause, Marco Hutter
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-01-17 (更新: 2025-12-14)
💡 一句话要点
提出一种基于神经网络模拟器的机器人世界模型,用于鲁棒策略优化。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人控制 世界模型 强化学习 模型预测控制 Sim-to-Real 自监督学习 双自回归 策略优化
📋 核心要点
- 现有机器人控制方法难以在真实环境中高效扩展,主要挑战在于学习鲁棒且泛化的世界模型。
- 论文提出一种基于双自回归机制和自监督训练的世界模型,实现可靠的长时程预测,提升泛化能力。
- 提出的策略优化框架利用世界模型进行高效训练,并在真实机器人系统中实现无缝部署。
📝 摘要(中文)
本文提出了一种新的世界模型学习框架,旨在准确捕捉复杂、部分可观测和随机的动力学特性,从而实现高效且可扩展的机器人控制。该方法采用双自回归机制和自监督训练,无需领域特定的归纳偏置即可实现可靠的长时程预测,确保了在各种机器人任务中的适应性。此外,还提出了一个策略优化框架,利用世界模型在想象环境中进行高效训练,并无缝部署到真实系统中。本研究通过解决长时程预测、误差累积和sim-to-real迁移等挑战,推进了基于模型的强化学习。所提出的方法提供了一个可扩展且鲁棒的框架,为现实应用中自适应和高效的机器人系统铺平了道路。
🔬 方法详解
问题定义:现有机器人控制方法在真实环境中面临挑战,因为真实环境通常具有复杂、部分可观测和随机的动力学特性。传统的基于模型的强化学习方法难以进行长时程预测,容易出现误差累积,并且在sim-to-real迁移过程中性能下降。因此,需要一种能够准确捕捉环境动力学特性,并能有效进行策略优化的世界模型。
核心思路:论文的核心思路是构建一个基于神经网络的模拟器,即机器人世界模型,该模型能够学习环境的动力学特性,并用于策略优化。通过在模拟环境中进行训练,可以避免在真实环境中进行大量试错,从而提高训练效率和安全性。双自回归机制和自监督训练的结合,旨在提升模型预测的准确性和鲁棒性,从而实现更好的sim-to-real迁移。
技术框架:整体框架包含两个主要部分:世界模型学习和策略优化。世界模型学习阶段,利用双自回归机制和自监督训练,从机器人与环境交互的数据中学习环境的动力学特性。策略优化阶段,利用学习到的世界模型,在模拟环境中进行策略训练,然后将训练好的策略部署到真实机器人系统中。该框架通过世界模型连接了模拟环境和真实环境,实现了高效的sim-to-real迁移。
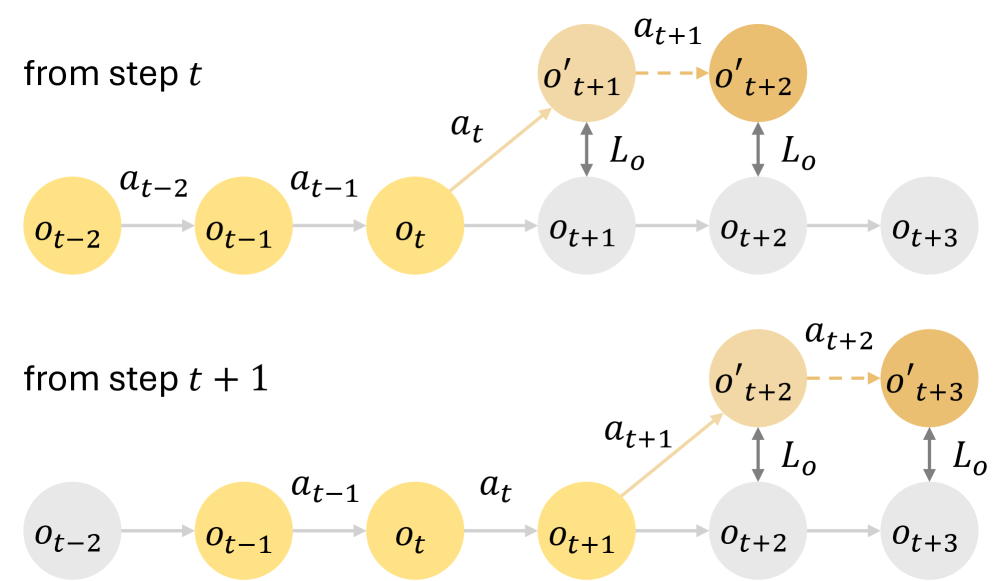
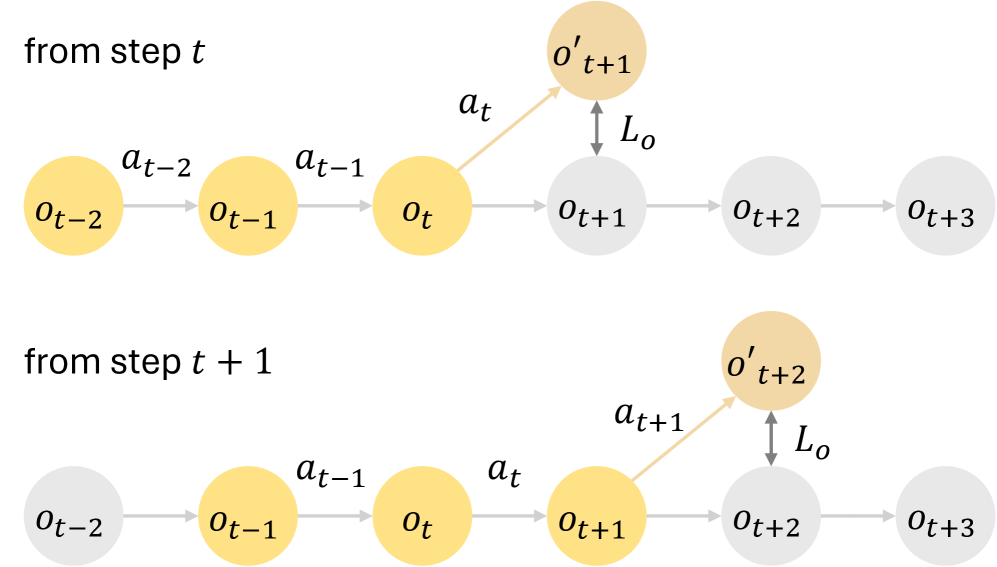
关键创新:论文的关键创新在于提出了双自回归机制和自监督训练相结合的世界模型学习方法。双自回归机制能够更好地捕捉环境的长期依赖关系,从而提高长时程预测的准确性。自监督训练则能够利用大量的无标签数据进行训练,从而提高模型的泛化能力。此外,该框架还提出了一个策略优化方法,能够有效地利用学习到的世界模型进行策略训练。
关键设计:双自回归机制的具体实现方式未知,但可以推测其可能包含两个自回归模型,分别用于预测不同的状态变量或使用不同的时间尺度。自监督训练可能包括重构损失、对比学习损失等。策略优化方法可能采用TRPO、PPO等算法,并针对世界模型的特点进行调整。具体的网络结构、损失函数和参数设置等细节在论文中可能有所描述,但在此处未知。
🖼️ 关键图片

📊 实验亮点
论文提出的方法在多个机器人控制任务上进行了实验验证,结果表明,该方法能够显著提高策略的鲁棒性和泛化能力。具体的性能数据和对比基线未知,但摘要中提到该方法解决了长时程预测、误差累积和sim-to-real迁移等挑战,表明该方法在这些方面取得了显著的提升。
🎯 应用场景
该研究成果可广泛应用于各种机器人控制任务,例如自主导航、操作、抓取等。通过学习真实环境的动力学特性,机器人可以在复杂和不确定的环境中更加鲁棒和高效地完成任务。该方法还可以用于机器人设计和优化,通过模拟不同设计方案的性能,从而选择最佳的设计方案。此外,该方法还可以应用于自动驾驶、游戏AI等领域。
📄 摘要(原文)
Learning robust and generalizable world models is crucial for enabling efficient and scalable robotic control in real-world environments. In this work, we introduce a novel framework for learning world models that accurately capture complex, partially observable, and stochastic dynamics. The proposed method employs a dual-autoregressive mechanism and self-supervised training to achieve reliable long-horizon predictions without relying on domain-specific inductive biases, ensuring adaptability across diverse robotic tasks. We further propose a policy optimization framework that leverages world models for efficient training in imagined environments and seamless deployment in real-world systems. This work advances model-based reinforcement learning by addressing the challenges of long-horizon prediction, error accumulation, and sim-to-real transfer. By providing a scalable and robust framework, the introduced methods pave the way for adaptive and efficient robotic systems in real-world applications.