Fast Multi-Party Open-Ended Conversation with a Social Robot
作者: Giulio Antonio Abbo, Maria Jose Pinto-Bernal, Martijn Catrycke, Tony Belpaeme
分类: cs.HC, cs.RO
发布日期: 2025-01-15 (更新: 2025-12-12)
备注: 15 pages, 5 figures, 4 tables; 2 appendices
💡 一句话要点
提出基于多模态感知与LLM的社交机器人多方开放式对话系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多方对话 社交机器人 人机交互 大型语言模型 多模态感知
📋 核心要点
- 多方开放式对话中,机器人需识别说话人、分配发言权并连贯响应,现有方法难以应对对话重叠或快速转换。
- 结合声音方向、说话人分离、面部识别等多模态感知与大型语言模型,实现机器人对多方对话的理解与生成。
- 实验表明,该系统在并行对话中寻址准确率达92.6%,面部识别可靠性达80-94%,提升了社交存在感与参与度。
📝 摘要(中文)
本文提出了一种用于社交机器人的多方开放式对话系统,旨在解决人机交互中多方对话的挑战,尤其是在机器人需要识别说话者、分配发言权以及在对话重叠或快速转换时做出连贯响应的情况下。该系统结合了多模态感知(声音到达方向、说话人分离、面部识别)与大型语言模型(LLM)以生成回复。该系统在Furhat机器人上实现,并通过两个场景对30名参与者进行了评估:(i)并行、独立的对话;(ii)共享的小组讨论。结果表明,该系统能够保持连贯且引人入胜的对话,在并行设置中实现了较高的寻址准确率(92.6%),并具有强大的面部识别可靠性(80-94%)。参与者报告了清晰的社交存在感和积极的参与度,但基于音频的说话人识别错误和响应延迟等技术障碍影响了小组互动的流畅性。研究结果突出了基于LLM的多方交互的潜力和局限性,并概述了改进未来社交机器人中多模态线索集成和响应能力的具体方向。
🔬 方法详解
问题定义:论文旨在解决社交机器人参与多方开放式对话时面临的挑战。现有方法在处理复杂场景(如多人同时发言、快速切换话题)时,难以准确识别说话者、合理分配发言权,并生成连贯自然的回复,导致交互体验不佳。现有方法痛点在于多模态信息融合不足,以及对动态对话上下文的理解能力有限。
核心思路:论文的核心思路是利用多模态感知技术(声音、视觉)来增强机器人对对话场景的理解,并结合大型语言模型(LLM)来生成更自然、更符合语境的回复。通过多模态信息的融合,机器人可以更准确地识别说话者,并根据对话历史和当前语境生成合适的回复,从而提高交互的流畅性和参与度。
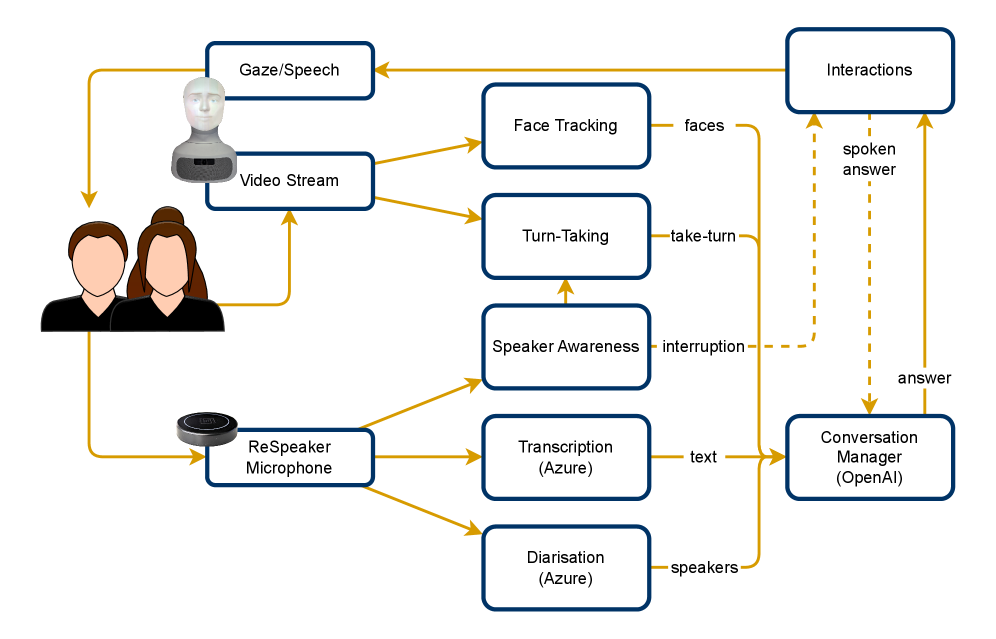
技术框架:该系统的整体架构包含以下几个主要模块:1) 多模态感知模块:负责收集和处理来自不同模态的信息,包括声音到达方向(DOA)、说话人分离(Speaker Diarization)和面部识别。2) 上下文理解模块:融合多模态信息,构建对话上下文表示,包括说话人身份、对话历史和当前话题。3) 回复生成模块:利用大型语言模型(LLM)根据上下文表示生成回复。4) 机器人控制模块:控制机器人的语音输出和面部表情,实现自然的交互。
关键创新:该论文的关键创新在于将多模态感知与大型语言模型相结合,用于解决社交机器人的多方开放式对话问题。与传统方法相比,该方法能够更准确地识别说话者,并生成更自然、更符合语境的回复。此外,该系统还能够处理对话重叠和快速切换话题等复杂场景,提高了交互的鲁棒性和流畅性。
关键设计:在多模态感知方面,论文采用了基于麦克风阵列的声音到达方向估计方法,以及基于深度学习的说话人分离和面部识别技术。在回复生成方面,论文使用了预训练的大型语言模型,并通过微调使其适应社交机器人的对话场景。此外,论文还设计了一种基于规则的发言权分配机制,以确保对话的公平性和流畅性。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
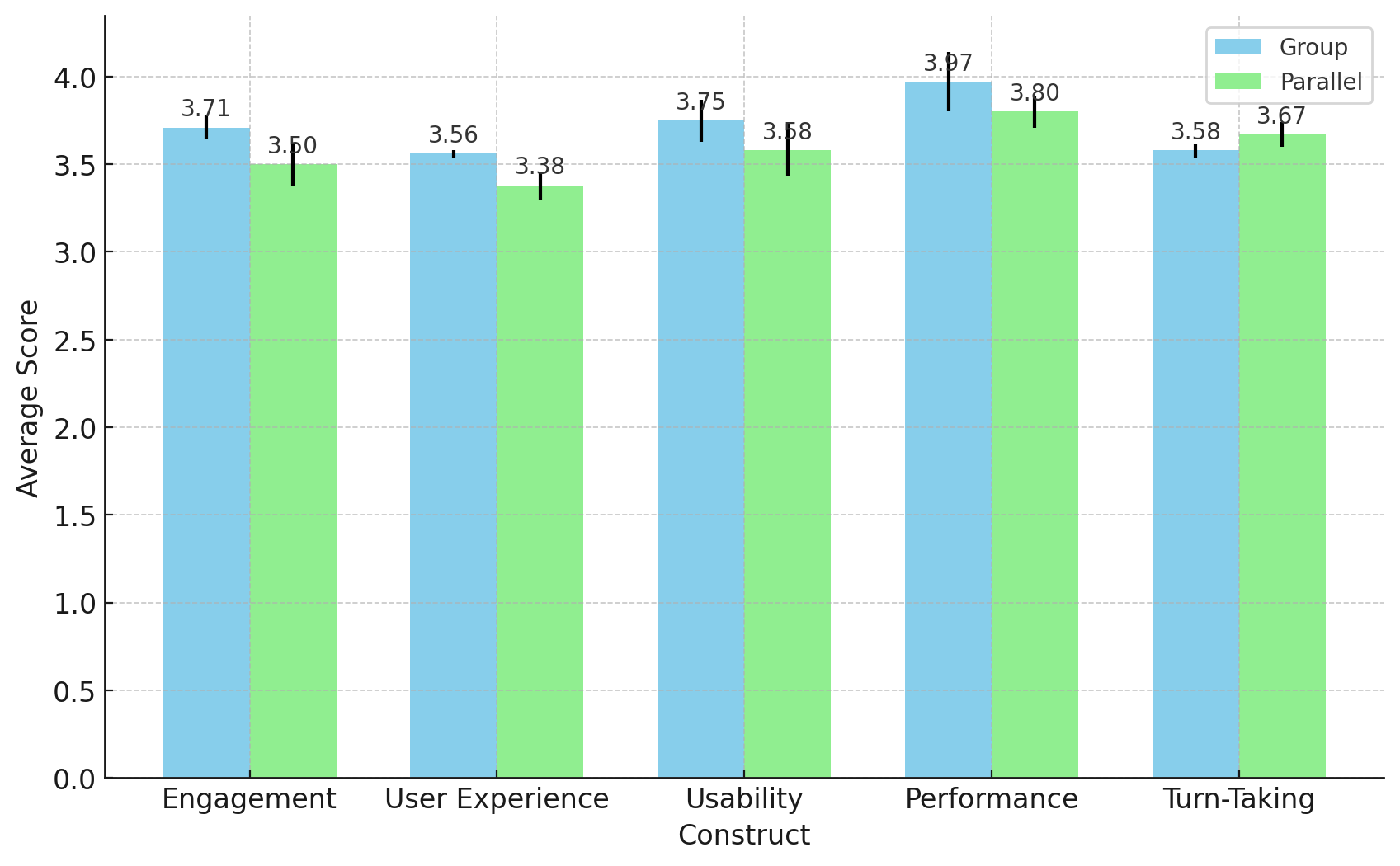
实验结果表明,该系统在并行对话场景中实现了92.6%的寻址准确率,面部识别可靠性达到80-94%。参与者反馈该系统具有清晰的社交存在感和积极的参与度。这些结果表明,该系统在多方开放式对话方面具有良好的性能和潜力。虽然音频识别错误和响应延迟影响了流畅性,但整体效果积极。
🎯 应用场景
该研究成果可应用于多种场景,如家庭服务机器人、教育机器人、医疗辅助机器人等。通过提升机器人与多人进行自然对话的能力,可以改善人机交互体验,提高机器人的实用性和接受度。未来,该技术有望应用于更复杂的社交场景,如会议、社交聚会等,使机器人能够更好地融入人类社会。
📄 摘要(原文)
Multi-party open-ended conversation remains a major challenge in human-robot interaction, particularly when robots must recognise speakers, allocate turns, and respond coherently under overlapping or rapidly shifting dialogue. This paper presents a multi-party conversational system that combines multimodal perception (voice direction of arrival, speaker diarisation, face recognition) with a large language model for response generation. Implemented on the Furhat robot, the system was evaluated with 30 participants across two scenarios: (i) parallel, separate conversations and (ii) shared group discussion. Results show that the system maintains coherent and engaging conversations, achieving high addressee accuracy in parallel settings (92.6%) and strong face recognition reliability (80-94%). Participants reported clear social presence and positive engagement, although technical barriers such as audio-based speaker recognition errors and response latency affected the fluidity of group interactions. The results highlight both the promise and limitations of LLM-based multi-party interaction and outline concrete directions for improving multimodal cue integration and responsiveness in future social robots.