AutoLoop: Fast Visual SLAM Fine-tuning through Agentic Curriculum Learning
作者: Assaf Lahiany, Oren Gal
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-01-15
💡 一句话要点
AutoLoop:通过Agent智能课程学习快速微调视觉SLAM系统
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉SLAM 闭环检测 强化学习 自动课程学习 DDPG 参数优化 机器人导航
📋 核心要点
- 现有视觉SLAM系统难以兼顾计算效率和鲁棒的闭环检测,手动调参耗时且计算开销大。
- AutoLoop利用DDPG智能体动态调整闭环权重,结合自动课程学习和高效微调,无需手动搜索超参数。
- 实验表明,AutoLoop在多个数据集上达到或超过现有性能,同时训练时间显著减少。
📝 摘要(中文)
现有的视觉SLAM系统在计算效率和鲁棒的闭环检测之间面临着巨大的挑战。传统方法需要仔细的手动调整,并产生大量的计算开销,而基于学习的方法要么缺乏显式的闭环能力,要么通过计算成本高昂的方法来实现。我们提出了AutoLoop,一种新颖的方法,它结合了自动课程学习和高效的视觉SLAM系统微调。我们的方法采用DDPG(深度确定性策略梯度)智能体来动态调整训练期间的闭环权重,无需手动超参数搜索,同时显著减少所需的训练步骤。该方法离线预先计算潜在的闭环对,并通过智能体引导的课程来利用它们,使模型能够有效地适应新的场景。在TartanAir上进行训练,并在包括KITTI、EuRoC、ICL-NUIM和TUM RGB-D在内的多个基准上验证的实验表明,AutoLoop实现了可比或更优越的性能,同时与传统方法相比,训练时间减少了一个数量级。AutoLoop为视觉SLAM系统的快速适应提供了一个实用的解决方案,自动执行传统上需要多次手动迭代的权重调整过程。我们的结果表明,这种自动课程策略不仅加速了训练,而且保持或提高了模型在各种环境条件下的性能。
🔬 方法详解
问题定义:视觉SLAM系统需要在计算效率和闭环检测的鲁棒性之间取得平衡。传统方法依赖于手动调整参数,这既耗时又需要大量的计算资源。基于学习的方法虽然可以自动化一些过程,但通常缺乏显式的闭环检测机制,或者使用计算成本高昂的方法来实现,限制了其在实际应用中的可行性。
核心思路:AutoLoop的核心思路是利用强化学习(特别是DDPG算法)训练一个智能体,该智能体能够动态地调整视觉SLAM系统中闭环检测相关的权重参数。通过这种方式,系统可以自动适应不同的环境和场景,从而在保证计算效率的同时,提高闭环检测的准确性和鲁棒性。
技术框架:AutoLoop的整体框架包括以下几个主要模块:1) 离线闭环候选对预计算模块,用于预先计算潜在的闭环候选对,减少在线计算量;2) DDPG智能体,负责根据当前SLAM系统的状态动态调整闭环权重;3) 视觉SLAM系统,使用调整后的权重进行闭环检测和位姿优化;4) 奖励函数,用于评估SLAM系统的性能,并反馈给DDPG智能体,指导其学习。
关键创新:AutoLoop的关键创新在于将强化学习引入到视觉SLAM系统的参数优化过程中,实现了闭环检测权重的自动调整。与传统的手动调参方法相比,AutoLoop能够显著减少训练时间和人工干预,并提高系统的适应性。此外,通过离线预计算闭环候选对,进一步降低了在线计算的负担。
关键设计:AutoLoop使用DDPG算法作为智能体的学习算法,DDPG是一种适用于连续动作空间的强化学习算法。奖励函数的设计至关重要,需要综合考虑SLAM系统的位姿精度、闭环检测的准确率和计算效率等因素。此外,网络结构的设计也需要仔细考虑,以保证智能体能够有效地学习到最优的权重调整策略。具体参数设置未知。
🖼️ 关键图片
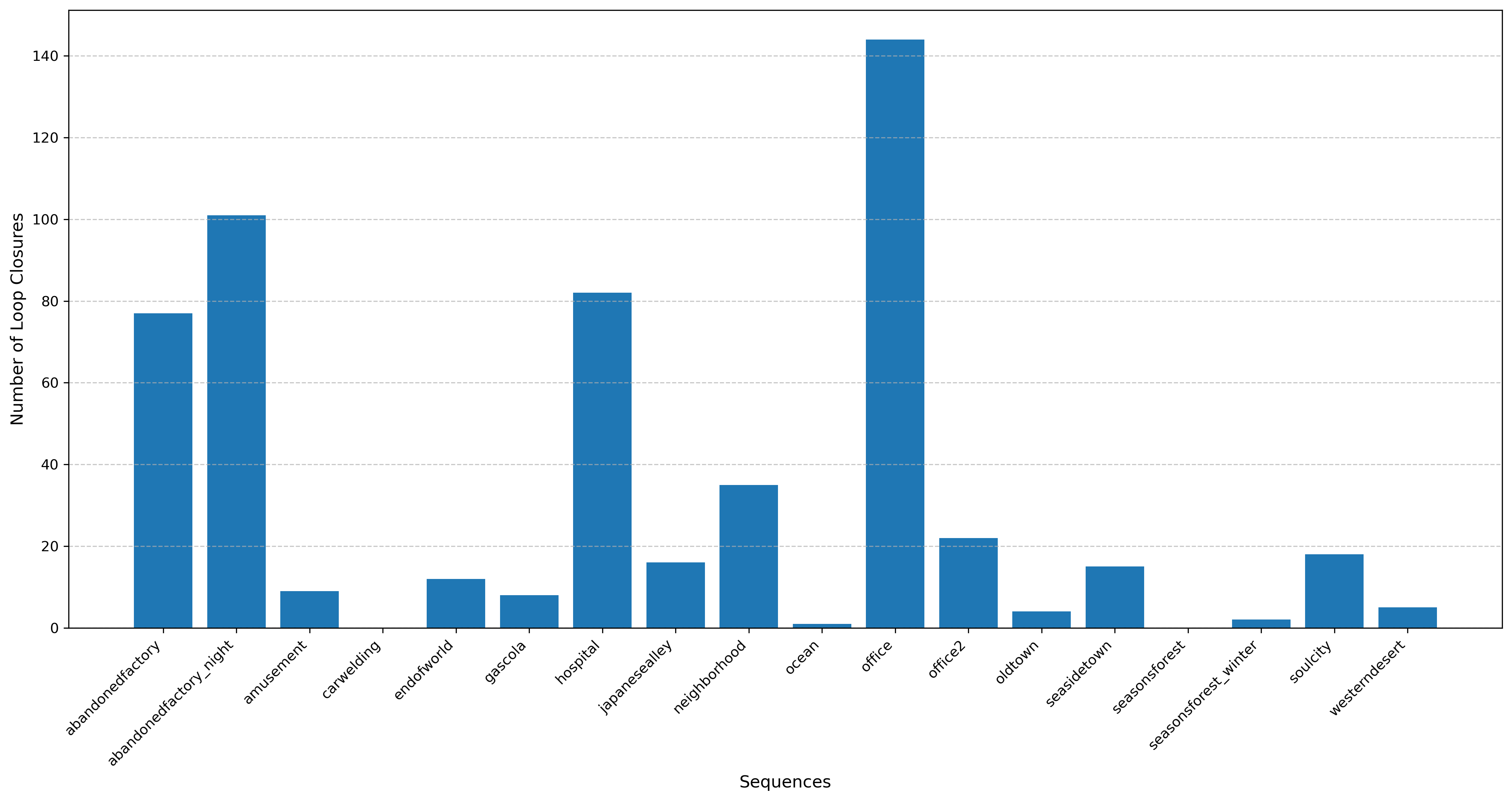
📊 实验亮点
AutoLoop在多个数据集(包括KITTI、EuRoC、ICL-NUIM和TUM RGB-D)上进行了验证,结果表明,与传统方法相比,AutoLoop在保持或提高性能的同时,训练时间减少了一个数量级。具体性能提升数据未知,但整体效果显著。
🎯 应用场景
AutoLoop可应用于机器人导航、自动驾驶、增强现实等领域,尤其是在需要快速部署和适应新环境的场景下。该方法能够显著降低视觉SLAM系统的开发和维护成本,提高其在复杂环境中的鲁棒性和可靠性,加速相关技术的落地和应用。
📄 摘要(原文)
Current visual SLAM systems face significant challenges in balancing computational efficiency with robust loop closure handling. Traditional approaches require careful manual tuning and incur substantial computational overhead, while learning-based methods either lack explicit loop closure capabilities or implement them through computationally expensive methods. We present AutoLoop, a novel approach that combines automated curriculum learning with efficient fine-tuning for visual SLAM systems. Our method employs a DDPG (Deep Deterministic Policy Gradient) agent to dynamically adjust loop closure weights during training, eliminating the need for manual hyperparameter search while significantly reducing the required training steps. The approach pre-computes potential loop closure pairs offline and leverages them through an agent-guided curriculum, allowing the model to adapt efficiently to new scenarios. Experiments conducted on TartanAir for training and validated across multiple benchmarks including KITTI, EuRoC, ICL-NUIM and TUM RGB-D demonstrate that AutoLoop achieves comparable or superior performance while reducing training time by an order of magnitude compared to traditional approaches. AutoLoop provides a practical solution for rapid adaptation of visual SLAM systems, automating the weight tuning process that traditionally requires multiple manual iterations. Our results show that this automated curriculum strategy not only accelerates training but also maintains or improves the model's performance across diverse environmental conditions.