Toward Zero-Shot User Intent Recognition in Shared Autonomy
作者: Atharv Belsare, Zohre Karimi, Connor Mattson, Daniel S. Brown
分类: cs.RO, cs.HC
发布日期: 2025-01-14
备注: 10 pages, 6 figures, Accepted to IEEE/ACM International Conference on Human-Robot Interaction (HRI), 2025. Equal Contribution from the first three authors
💡 一句话要点
提出VOSA零样本框架,利用末端视觉提升共享自主系统中用户意图识别
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 共享自主 人机协作 零样本学习 用户意图识别 末端视觉 机器人操纵 混合控制
📋 核心要点
- 现有共享自主方法依赖大量先验知识或交互学习,难以适应未知或动态变化的环境。
- VOSA框架利用末端视觉估计零样本人类意图,结合混合控制辅助完成操纵任务。
- 用户研究表明,VOSA性能媲美oracle模型,且在未知意图场景下优于基线方法。
📝 摘要(中文)
共享自主的一个根本挑战是使用高自由度机器人来辅助人类,而不是阻碍人类。这需要首先推断用户的意图,然后帮助用户实现他们的意图。虽然之前的方法取得了一些成功,但它们要么严重依赖于对所有可能的人类意图的先验知识,要么需要大量演示和与人类的交互来学习这些意图,然后才能辅助用户。我们提出并研究了一个零样本、纯视觉共享自主(VOSA)框架,旨在允许机器人使用末端执行器视觉来估计零样本人类意图,并结合混合控制来帮助人类完成具有未知和动态变化物体位置的操纵任务。为了证明我们的VOSA框架的有效性,我们在Kinova Gen3机械臂上实例化了一个简单的VOSA版本,并通过对三个桌面操纵任务进行用户研究来评估我们的系统。VOSA的性能与接收可能的人类意图的特权知识的oracle基线模型相匹配,同时比无辅助遥操作需要更少的努力。在更现实的设置中,当可能的人类意图集完全或部分未知时,我们证明VOSA比基线方法需要更少的人力和时间,并且受到大多数参与者的青睐。我们的结果证明了使用现成的视觉算法来实现机器人机械臂的灵活和有益的共享控制的有效性和效率。
🔬 方法详解
问题定义:现有共享自主系统在理解用户意图方面存在局限性。它们通常需要预先知道所有可能的意图,或者需要大量的用户交互来学习这些意图。这使得它们难以适应新的、动态变化的环境,例如物体位置未知或用户意图事先未定义的情况。因此,需要一种能够零样本识别用户意图的共享自主方法。
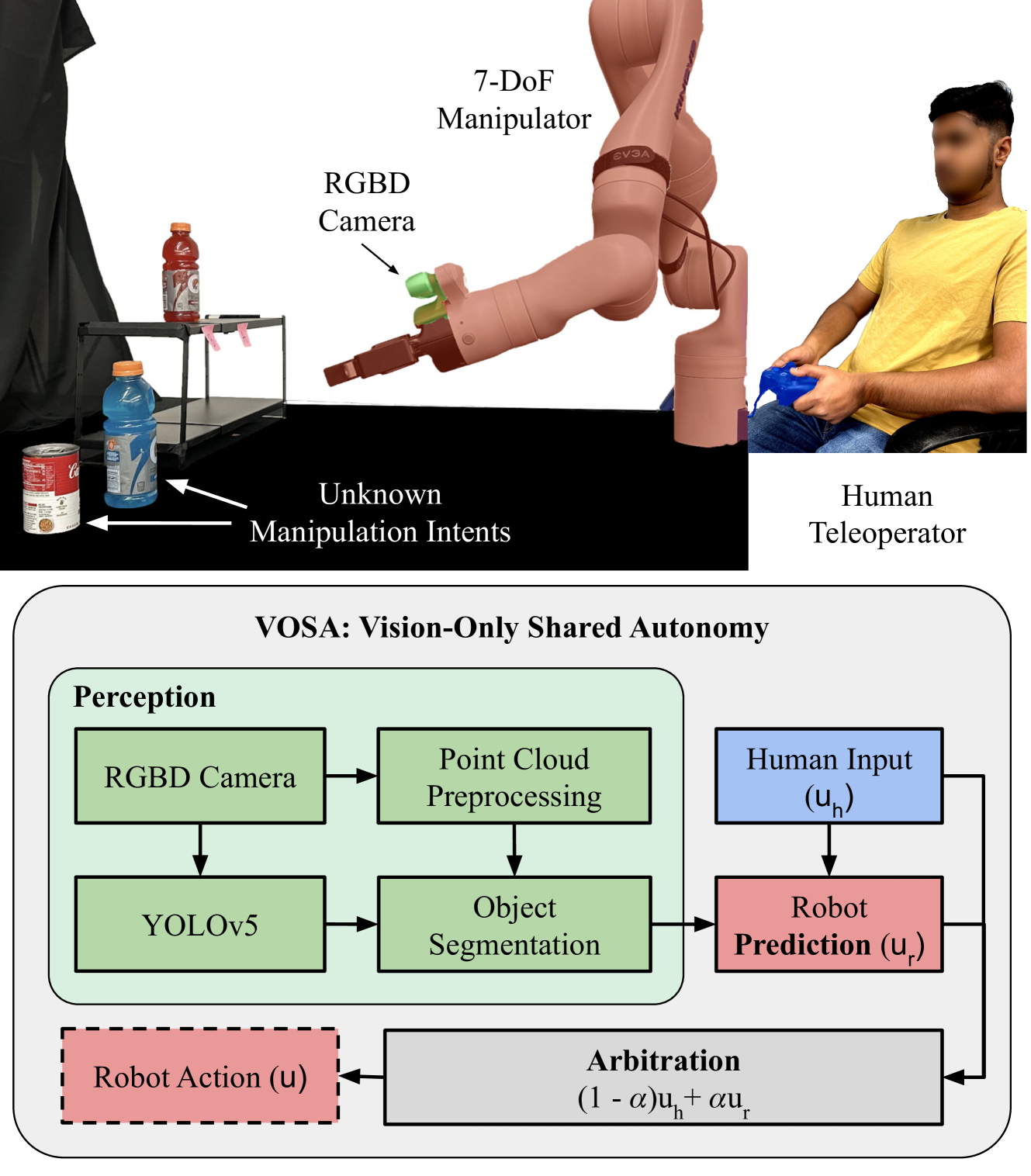
核心思路:VOSA的核心思路是利用机器人末端执行器的视觉信息来推断用户的意图。通过分析末端执行器周围的视觉场景,机器人可以理解用户想要做什么,即使它之前没有见过这个特定的任务或物体。这种方法避免了对大量先验知识或用户交互的需求,从而提高了系统的灵活性和适应性。
技术框架:VOSA框架包含以下主要模块:1) 末端视觉感知模块,负责获取末端执行器周围的视觉信息;2) 意图识别模块,利用视觉信息估计用户的意图;3) 混合控制模块,结合用户的控制输入和机器人自主控制,共同完成任务。整个流程是:用户发出控制指令,机器人通过末端视觉感知环境,意图识别模块推断用户意图,混合控制模块融合用户指令和机器人自主控制,驱动机器人执行动作。
关键创新:VOSA最重要的技术创新点在于其零样本意图识别能力。与传统的需要大量训练数据或先验知识的方法不同,VOSA能够仅通过视觉信息来推断用户的意图,而无需事先见过该任务或物体。这种零样本能力使得VOSA能够适应新的、动态变化的环境,从而提高了共享自主系统的实用性。
关键设计:VOSA的关键设计包括:1) 使用现成的视觉算法(具体算法未知)进行物体识别和场景理解;2) 设计合适的意图表示方法,将视觉信息映射到用户意图空间;3) 设计混合控制策略,平衡用户控制和机器人自主控制,确保任务的顺利完成。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VOSA在三个桌面操纵任务中表现出色,性能与oracle基线模型相匹配,同时比无辅助遥操作需要更少的努力。在更现实的、可能的人类意图集完全或部分未知的设置中,VOSA比基线方法需要更少的人力和时间,并且受到大多数参与者的青睐。这些结果证明了VOSA框架的有效性和效率。
🎯 应用场景
VOSA框架可应用于各种需要人机协作的场景,例如:远程操作、医疗机器人辅助手术、家庭服务机器人等。该研究降低了共享自主系统对先验知识和交互学习的依赖,使得机器人能够更好地理解和辅助人类,从而提高工作效率和安全性。未来,VOSA有望在更复杂的环境中实现更智能、更灵活的人机协作。
📄 摘要(原文)
A fundamental challenge of shared autonomy is to use high-DoF robots to assist, rather than hinder, humans by first inferring user intent and then empowering the user to achieve their intent. Although successful, prior methods either rely heavily on a priori knowledge of all possible human intents or require many demonstrations and interactions with the human to learn these intents before being able to assist the user. We propose and study a zero-shot, vision-only shared autonomy (VOSA) framework designed to allow robots to use end-effector vision to estimate zero-shot human intents in conjunction with blended control to help humans accomplish manipulation tasks with unknown and dynamically changing object locations. To demonstrate the effectiveness of our VOSA framework, we instantiate a simple version of VOSA on a Kinova Gen3 manipulator and evaluate our system by conducting a user study on three tabletop manipulation tasks. The performance of VOSA matches that of an oracle baseline model that receives privileged knowledge of possible human intents while also requiring significantly less effort than unassisted teleoperation. In more realistic settings, where the set of possible human intents is fully or partially unknown, we demonstrate that VOSA requires less human effort and time than baseline approaches while being preferred by a majority of the participants. Our results demonstrate the efficacy and efficiency of using off-the-shelf vision algorithms to enable flexible and beneficial shared control of a robot manipulator. Code and videos available here: https://sites.google.com/view/zeroshot-sharedautonomy/home.