FDPP: Fine-tune Diffusion Policy with Human Preference
作者: Yuxin Chen, Devesh K. Jha, Masayoshi Tomizuka, Diego Romeres
分类: cs.RO, cs.LG
发布日期: 2025-01-14
💡 一句话要点
FDPP:通过人类偏好微调扩散策略,提升机器人操作任务适应性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 模仿学习 强化学习 偏好学习 扩散策略 策略微调 KL正则化
📋 核心要点
- 现有模仿学习方法难以适应新偏好或环境变化,限制了机器人的泛化能力。
- FDPP通过偏好学习获取奖励函数,并使用强化学习微调预训练策略,使其符合人类偏好。
- 实验表明,FDPP在定制策略行为的同时,保持了原始任务的性能,并利用KL正则化防止过拟合。
📝 摘要(中文)
模仿学习通过人类演示使机器人能够执行复杂的操纵任务,并且最近取得了巨大的成功。然而,这些技术通常难以使行为适应新的偏好或环境变化。为了解决这些限制,我们提出了基于人类偏好的微调扩散策略(FDPP)。FDPP通过基于偏好的学习来学习奖励函数。然后,该奖励用于通过强化学习(RL)微调预训练的策略,从而使预训练的策略与新的人类偏好对齐,同时仍然解决原始任务。我们在各种机器人任务和偏好上的实验表明,FDPP有效地定制了策略行为,而不会影响性能。此外,我们表明,在微调期间加入Kullback-Leibler(KL)正则化可以防止过度拟合,并有助于保持初始策略的能力。
🔬 方法详解
问题定义:现有模仿学习方法在机器人操作任务中,虽然能通过人类演示学习复杂行为,但难以适应新的用户偏好或动态变化的环境。这限制了策略的泛化性和实用性,用户需要花费大量精力重新训练模型以适应新的需求。
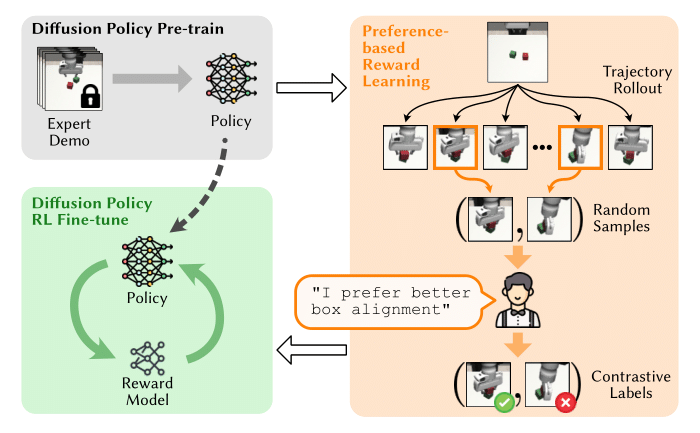
核心思路:FDPP的核心思路是利用人类偏好学习一个奖励函数,然后使用该奖励函数通过强化学习微调预训练的扩散策略。这样可以在保留预训练策略原有能力的基础上,使其适应新的偏好,避免从头开始训练,提高效率和泛化性。
技术框架:FDPP包含两个主要阶段:1) 偏好学习阶段:通过人类对不同轨迹的偏好数据,学习一个奖励函数,该奖励函数能够反映人类对机器人行为的期望。2) 策略微调阶段:使用学习到的奖励函数,通过强化学习算法(例如PPO),对预训练的扩散策略进行微调。在微调过程中,引入KL散度正则化,以防止策略过度偏离原始策略,保持其解决原始任务的能力。
关键创新:FDPP的关键创新在于将偏好学习与扩散策略微调相结合,实现对机器人行为的个性化定制。与传统的模仿学习方法相比,FDPP能够更好地适应用户偏好和环境变化。与直接使用强化学习训练策略相比,FDPP利用预训练的扩散策略作为先验知识,加速了学习过程,并提高了策略的鲁棒性。
关键设计:在偏好学习阶段,可以使用不同的模型来学习奖励函数,例如神经网络。奖励函数的输入可以是状态、动作或状态-动作对。在策略微调阶段,KL散度正则化的系数是一个重要的超参数,需要根据具体任务进行调整。此外,强化学习算法的选择也会影响微调效果。论文中使用了PPO算法,并取得了较好的效果。扩散策略的具体结构和训练方式也需要根据任务进行选择。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FDPP能够有效地定制策略行为,使其符合人类偏好,同时不会影响原始任务的性能。通过引入KL正则化,可以防止过拟合,并保持初始策略的能力。具体性能数据未知,但摘要强调了FDPP在各种机器人任务和偏好上的有效性。
🎯 应用场景
FDPP可应用于各种机器人操作任务,例如家庭服务机器人、工业机器人等。它可以根据用户的个性化需求,定制机器人的行为,使其更好地完成任务。例如,可以根据用户对抓取物体稳定性的偏好,调整机器人的抓取策略。未来,FDPP有望应用于更复杂的机器人系统,例如自动驾驶汽车、无人机等,实现更智能、更个性化的控制。
📄 摘要(原文)
Imitation learning from human demonstrations enables robots to perform complex manipulation tasks and has recently witnessed huge success. However, these techniques often struggle to adapt behavior to new preferences or changes in the environment. To address these limitations, we propose Fine-tuning Diffusion Policy with Human Preference (FDPP). FDPP learns a reward function through preference-based learning. This reward is then used to fine-tune the pre-trained policy with reinforcement learning (RL), resulting in alignment of pre-trained policy with new human preferences while still solving the original task. Our experiments across various robotic tasks and preferences demonstrate that FDPP effectively customizes policy behavior without compromising performance. Additionally, we show that incorporating Kullback-Leibler (KL) regularization during fine-tuning prevents over-fitting and helps maintain the competencies of the initial policy.