Motion Tracks: A Unified Representation for Human-Robot Transfer in Few-Shot Imitation Learning
作者: Juntao Ren, Priya Sundaresan, Dorsa Sadigh, Sanjiban Choudhury, Jeannette Bohg
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-01-13 (更新: 2025-10-10)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于运动轨迹的统一表示,用于少样本模仿学习中的人机迁移
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 模仿学习 人机协作 运动轨迹 跨具身迁移 少样本学习
📋 核心要点
- 现有模仿学习方法依赖大量机器人数据,收集成本高,而直接利用人类视频训练机器人策略面临动作标签缺失的挑战。
- 论文提出将动作表示为图像上的短时程2D运动轨迹,构建统一的跨具身动作空间,实现人类视频到机器人策略的迁移。
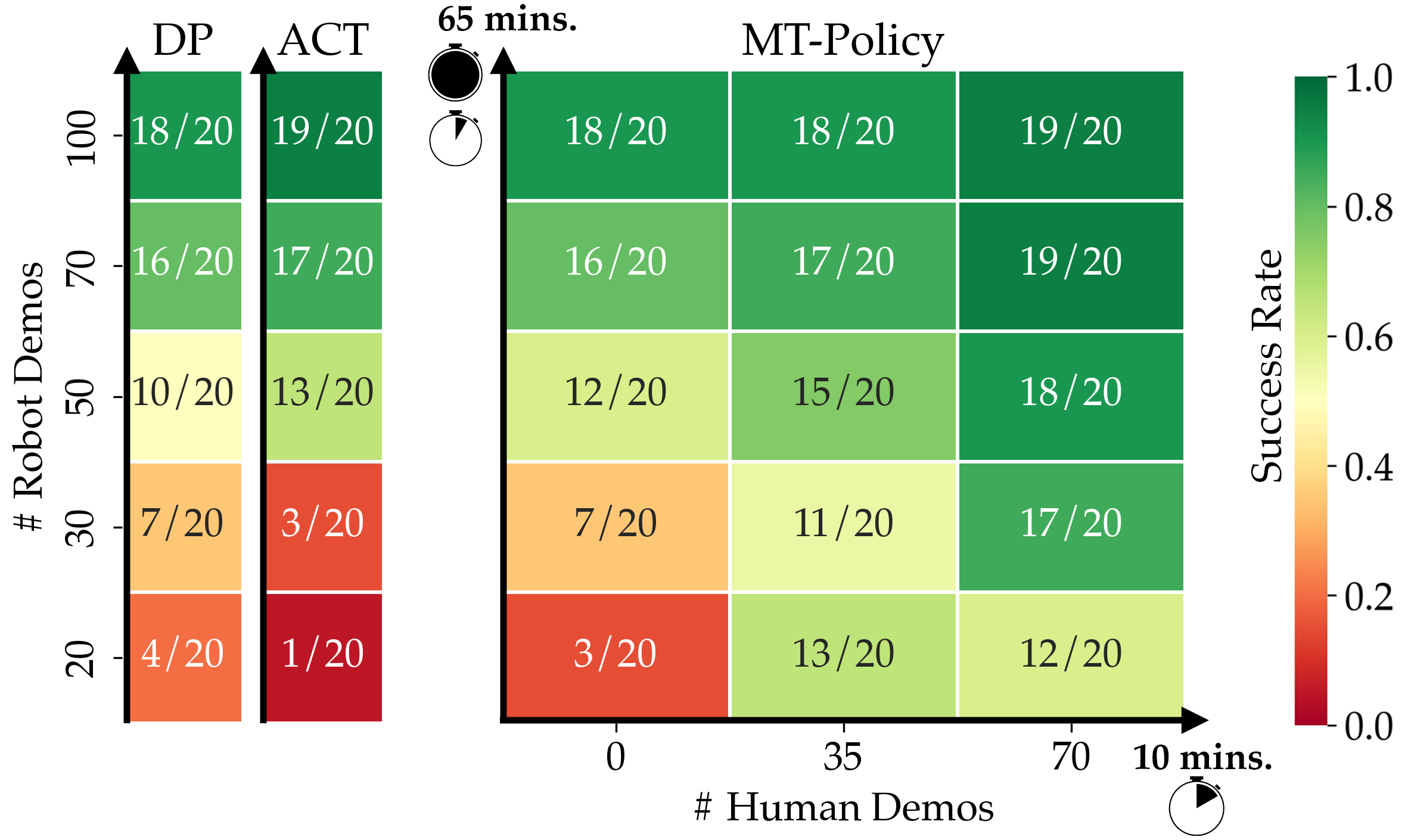
- 实验结果表明,该方法仅需少量人类视频和机器人演示,即可在真实世界任务中取得显著的成功率提升,并具备良好的泛化能力。
📝 摘要(中文)
本文提出了一种基于模仿学习(IL)的方法,旨在解决机器人自主完成日常任务的挑战。传统的模仿学习依赖于大量人工遥操作的机器人数据,成本高昂。本文利用人类视频作为可扩展的替代方案,但直接从人类视频训练IL策略面临缺乏机器人动作标签的问题。为此,本文将动作表示为图像上的短时程2D轨迹,称为运动轨迹,用于捕捉人类手部或机器人末端执行器的运动方向。本文实例化了一个名为运动轨迹策略(MT-π)的IL策略,该策略接收图像观测并输出运动轨迹作为动作。通过利用这种统一的、跨具身动作空间,MT-π仅需少量人类视频和有限的机器人演示即可高成功率地完成任务。在测试时,从两个摄像机视角预测运动轨迹,并通过多视角合成恢复6DoF轨迹。在4个真实世界任务中,MT-π实现了86.5%的平均成功率,优于不利用人类数据或本文提出的动作空间的现有IL基线40%,并且能够泛化到仅在人类视频中出现的场景。
🔬 方法详解
问题定义:现有模仿学习方法在机器人学习日常任务时,依赖于大量的机器人演示数据,获取成本高昂。利用人类视频作为替代方案,可以降低数据收集成本,但由于人类和机器人之间的具身差异以及缺乏对应的机器人动作标签,直接从人类视频中训练机器人策略非常困难。
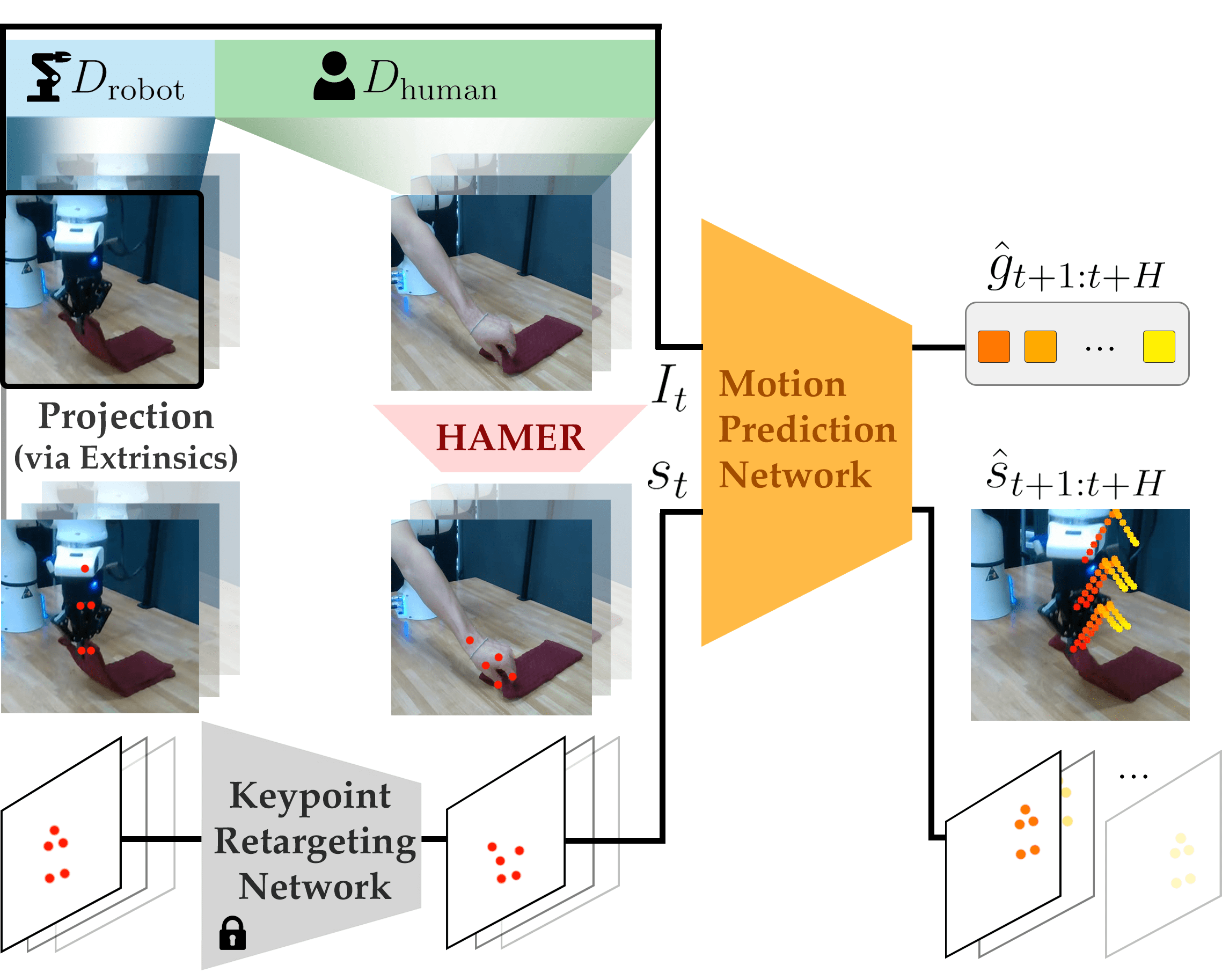
核心思路:论文的核心思路是将人类和机器人的动作都表示为图像上的短时程2D运动轨迹(Motion Tracks)。这种表示方式具有跨具身不变性,即无论是人类的手部还是机器人的末端执行器,其运动都可以用图像上的轨迹来描述。通过学习预测这种统一的动作表示,可以实现从人类视频到机器人策略的迁移。
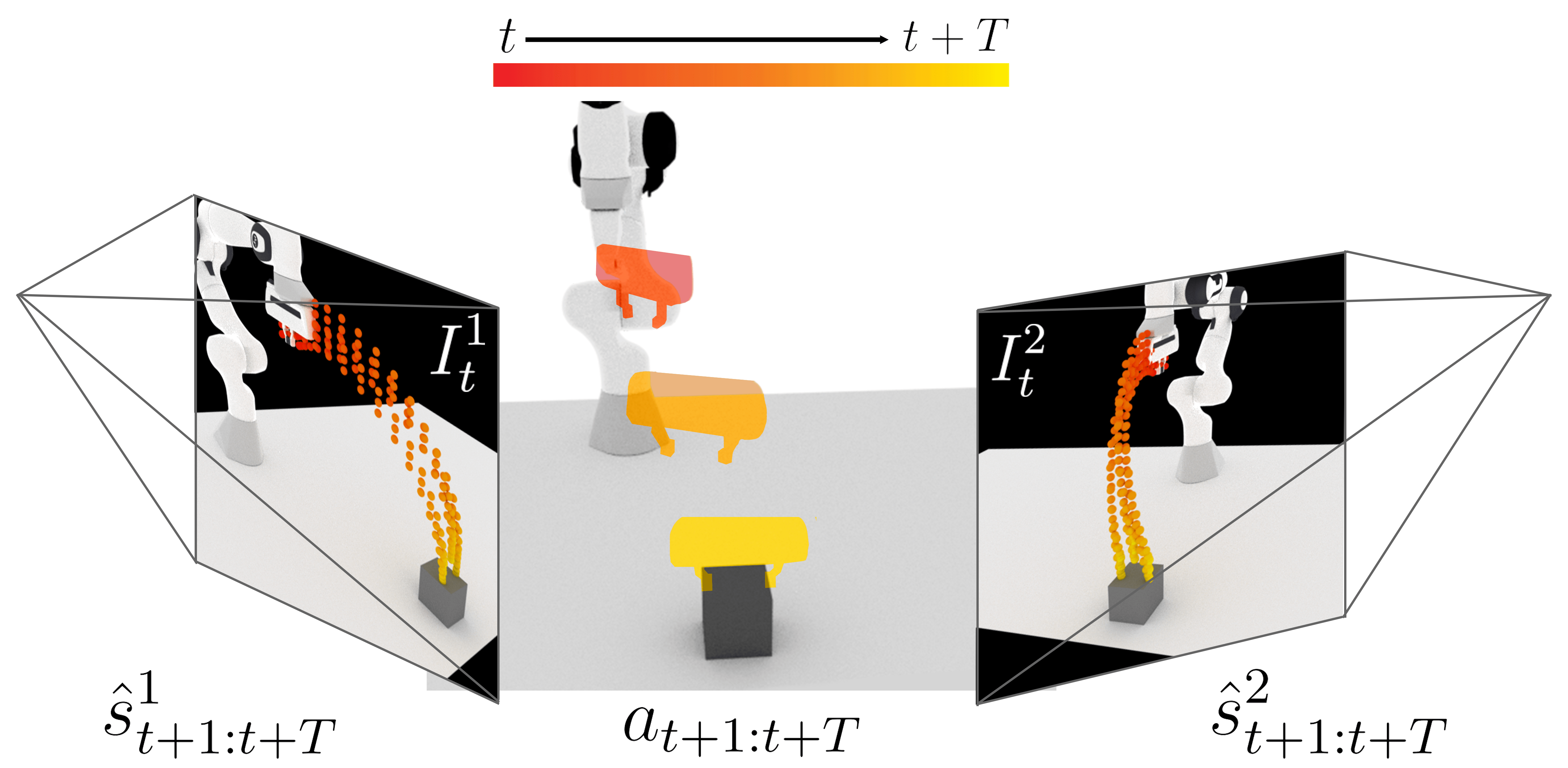
技术框架:整体框架包含以下几个主要模块:1) 运动轨迹提取:从人类视频和机器人演示中提取运动轨迹。2) 运动轨迹策略(MT-π)训练:使用模仿学习方法,训练一个策略网络,该网络接收图像观测作为输入,输出运动轨迹作为动作。3) 多视角轨迹合成:在测试时,从两个摄像机视角预测运动轨迹,并通过多视角几何方法恢复6DoF轨迹。
关键创新:最重要的创新点在于提出了运动轨迹作为统一的动作表示。与直接预测机器人关节角度或末端执行器位置相比,运动轨迹更加抽象,能够更好地捕捉动作的本质,从而实现跨具身的迁移学习。此外,利用多视角信息进行轨迹合成,可以有效地恢复3D空间中的运动轨迹。
关键设计:运动轨迹策略(MT-π)使用卷积神经网络提取图像特征,然后使用循环神经网络预测运动轨迹。损失函数采用L2损失,用于衡量预测轨迹与真实轨迹之间的差异。多视角轨迹合成采用三角化方法,将两个视角下的2D轨迹投影到3D空间中,从而恢复6DoF轨迹。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MT-π在四个真实世界任务中取得了显著的性能提升,平均成功率达到86.5%,相比于不利用人类数据或本文提出的动作空间的现有IL基线,性能提升了40%。此外,MT-π还能够泛化到仅在人类视频中出现的场景,表明其具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于机器人自动化领域,例如家庭服务机器人、工业机器人等。通过利用人类视频数据,可以降低机器人学习新任务的成本,提高机器人的智能化水平。未来,该方法有望扩展到更复杂的任务和环境,实现更广泛的应用。
📄 摘要(原文)
Teaching robots to autonomously complete everyday tasks remains a challenge. Imitation Learning (IL) is a powerful approach that imbues robots with skills via demonstrations, but is limited by the labor-intensive process of collecting teleoperated robot data. Human videos offer a scalable alternative, but it remains difficult to directly train IL policies from them due to the lack of robot action labels. To address this, we propose to represent actions as short-horizon 2D trajectories on an image. These actions, or motion tracks, capture the predicted direction of motion for either human hands or robot end-effectors. We instantiate an IL policy called Motion Track Policy (MT-pi) which receives image observations and outputs motion tracks as actions. By leveraging this unified, cross-embodiment action space, MT-pi completes tasks with high success given just minutes of human video and limited additional robot demonstrations. At test time, we predict motion tracks from two camera views, recovering 6DoF trajectories via multi-view synthesis. MT-pi achieves an average success rate of 86.5% across 4 real-world tasks, outperforming state-of-the-art IL baselines which do not leverage human data or our action space by 40%, and generalizes to scenarios seen only in human videos. Code and videos are available on our website https://portal-cornell.github.io/motion_track_policy/.