Shake-VLA: Vision-Language-Action Model-Based System for Bimanual Robotic Manipulations and Liquid Mixing
作者: Muhamamd Haris Khan, Selamawit Asfaw, Dmitrii Iarchuk, Miguel Altamirano Cabrera, Luis Moreno, Issatay Tokmurziyev, Dzmitry Tsetserukou
分类: cs.RO
发布日期: 2025-01-12
备注: Accepted to IEEE/ACM HRI 2025
💡 一句话要点
Shake-VLA:基于视觉-语言-动作模型的双臂机器人调酒系统
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人调酒 视觉语言动作模型 双臂机器人 力矩传感器 检索增强生成 异常检测 自动化
📋 核心要点
- 现有机器人调酒系统缺乏对复杂环境的适应性和精确的液体控制。
- Shake-VLA通过VLA模型整合视觉、语言和动作,实现智能配方检索和精确操作。
- 实验表明,Shake-VLA在嘈杂环境和复杂配料识别方面表现出色,整体成功率达100%。
📝 摘要(中文)
本文介绍了一种基于视觉-语言-动作(VLA)模型的系统Shake-VLA,旨在实现用于自动鸡尾酒制备的双臂机器人操作。该系统集成了视觉模块,用于检测配料瓶并读取标签;语音转文本模块,用于解释用户命令;以及语言模型,用于生成特定于任务的机器人指令。采用力矩(FT)传感器来精确测量倾倒的液体量,从而确保混合过程中配料比例的准确性。系统架构包括用于访问和调整配方的检索增强生成(RAG)模块、用于解决配料可用性问题的异常检测机制以及用于灵巧操作的双臂机器人。实验评估表明,系统各组件的成功率很高:语音转文本模块在嘈杂环境中实现了93%的成功率,视觉模块在杂乱环境中实现了91%的物体和标签检测成功率,异常模块成功识别了95%的检测到的配料与配方要求之间的差异,并且该系统在从配方制定到动作生成的鸡尾酒制备中实现了100%的总体成功率。
🔬 方法详解
问题定义:现有机器人调酒系统通常依赖于预定义的固定流程,难以适应动态变化的环境和用户个性化需求。它们在精确控制液体倾倒量、处理配料缺失或替换等异常情况方面存在不足,限制了其在实际应用中的灵活性和可靠性。
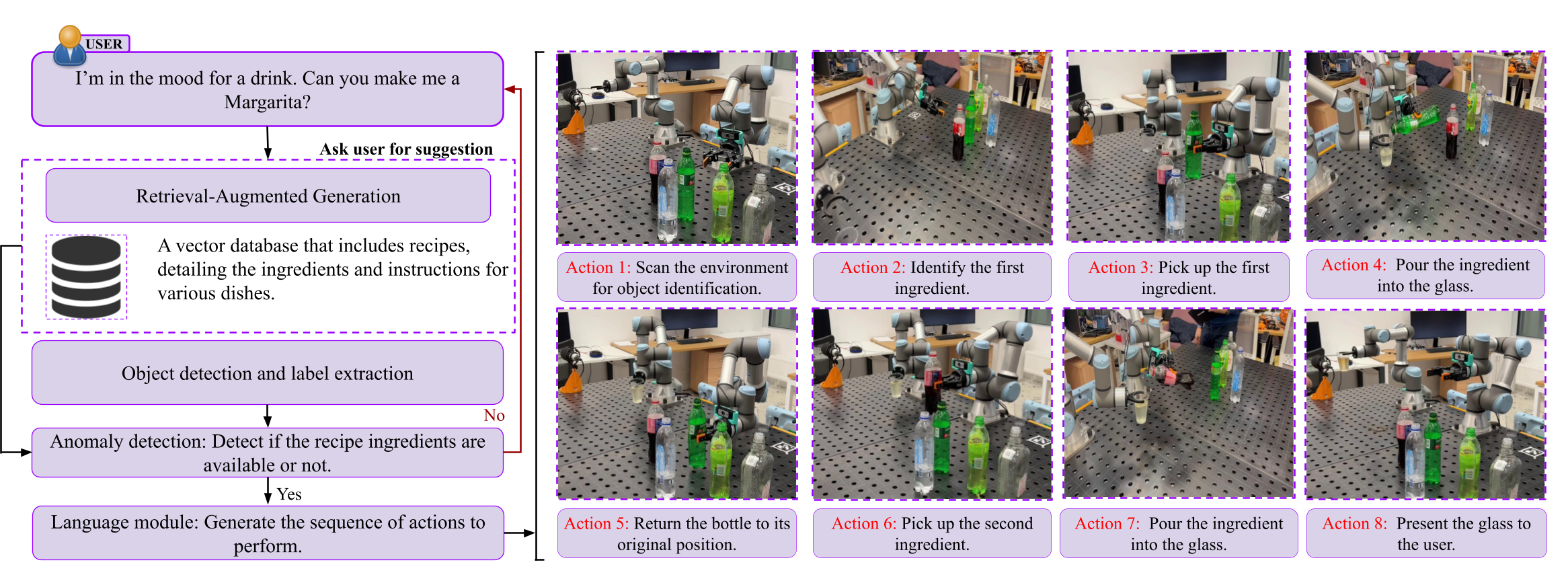
核心思路:Shake-VLA的核心在于利用视觉-语言-动作模型,将用户的语音指令转化为机器人可执行的动作序列。通过视觉模块感知环境,识别配料和标签;通过语言模型理解用户意图,并结合检索增强生成模块获取合适的配方;最后,通过双臂机器人执行精确的倾倒和混合操作。这种设计旨在提高系统的智能化程度和适应性。
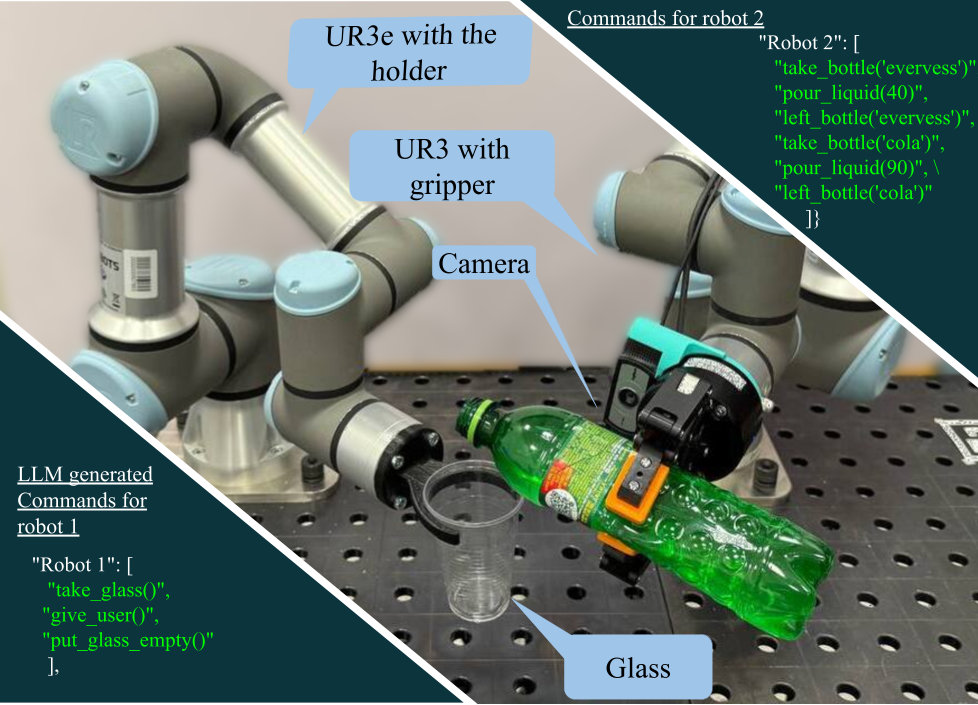
技术框架:Shake-VLA系统主要包含以下几个模块:1) 视觉模块:用于检测配料瓶和读取标签。2) 语音转文本模块:用于将用户语音命令转换为文本。3) 语言模型:用于理解用户意图并生成机器人指令。4) 检索增强生成(RAG)模块:用于访问和调整配方。5) 异常检测模块:用于检测配料可用性问题。6) 双臂机器人:用于执行倾倒和混合操作。力矩传感器用于精确测量液体倾倒量。
关键创新:该系统的关键创新在于将视觉、语言和动作模型集成到一个统一的框架中,实现了机器人对复杂任务的自主理解和执行。RAG模块的引入使得系统能够灵活地适应不同的配方和用户需求。异常检测模块增强了系统的鲁棒性,使其能够处理配料缺失或替换等意外情况。
关键设计:视觉模块采用深度学习模型进行物体检测和OCR识别。语言模型基于预训练的Transformer架构进行微调,以适应调酒领域的特定词汇和语法。RAG模块使用向量数据库存储配方信息,并通过相似度搜索快速检索相关配方。力矩传感器用于实时监测倾倒力度,确保液体量的精确控制。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Shake-VLA系统在各个模块均取得了较高的成功率。语音转文本模块在嘈杂环境中达到了93%的成功率,视觉模块在杂乱环境中达到了91%的物体和标签检测成功率,异常检测模块成功识别了95%的配料差异。最重要的是,该系统在完整的鸡尾酒制备过程中实现了100%的成功率,验证了其在实际应用中的可行性和可靠性。
🎯 应用场景
Shake-VLA系统具有广泛的应用前景,不仅可以应用于酒吧、餐厅等商业场所,实现自动化调酒服务,还可以应用于家庭环境,为用户提供个性化的饮品定制。此外,该系统还可以扩展到其他需要精确液体控制和复杂操作的领域,如化学实验、药物配制等。
📄 摘要(原文)
This paper introduces Shake-VLA, a Vision-Language-Action (VLA) model-based system designed to enable bimanual robotic manipulation for automated cocktail preparation. The system integrates a vision module for detecting ingredient bottles and reading labels, a speech-to-text module for interpreting user commands, and a language model to generate task-specific robotic instructions. Force Torque (FT) sensors are employed to precisely measure the quantity of liquid poured, ensuring accuracy in ingredient proportions during the mixing process. The system architecture includes a Retrieval-Augmented Generation (RAG) module for accessing and adapting recipes, an anomaly detection mechanism to address ingredient availability issues, and bimanual robotic arms for dexterous manipulation. Experimental evaluations demonstrated a high success rate across system components, with the speech-to-text module achieving a 93% success rate in noisy environments, the vision module attaining a 91% success rate in object and label detection in cluttered environment, the anomaly module successfully identified 95% of discrepancies between detected ingredients and recipe requirements, and the system achieved an overall success rate of 100% in preparing cocktails, from recipe formulation to action generation.