RoboHorizon: An LLM-Assisted Multi-View World Model for Long-Horizon Robotic Manipulation
作者: Zixuan Chen, Jing Huo, Yangtao Chen, Yang Gao
分类: cs.RO
发布日期: 2025-01-11 (更新: 2025-01-24)
备注: Under review
💡 一句话要点
RoboHorizon:一种LLM辅助的多视角世界模型,用于长时程机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 长时程机器人操作 多视角世界模型 LLM辅助 强化学习 关键帧发现 密集奖励 视觉模型
📋 核心要点
- 长时程机器人操作面临复杂表征和策略学习的挑战,尤其是在稀疏奖励和复杂视觉特征下。
- RoboHorizon利用LLM生成密集奖励,并结合多视角MAE的关键帧发现,增强机器人对任务的理解和感知。
- 实验表明,RoboHorizon在长短时程任务上均显著优于现有方法,提升了任务成功率。
📝 摘要(中文)
本文提出了一种名为RoboHorizon的LLM辅助多视角世界模型,旨在解决长时程机器人操作中高效控制的挑战。该方法基于Recognize-Sense-Plan-Act (RSPA) 流程,利用预训练LLM根据任务语言指令生成密集奖励结构,从而帮助机器人更好地识别长时程任务。同时,将关键帧发现集成到多视角掩码自编码器(MAE)架构中,增强机器人感知关键任务序列的能力。利用这些密集奖励和多视角表示,构建机器人世界模型,并通过强化学习算法高效规划长时程任务。在RLBench和FurnitureBench上的实验表明,RoboHorizon优于最先进的视觉模型强化学习方法,在RLBench的4个短时程任务上成功率提高了23.35%,在RLBench的6个长时程任务和FurnitureBench的3个家具组装任务上成功率提高了29.23%。
🔬 方法详解
问题定义:长时程机器人操作任务由于其复杂性和长期依赖性,在稀疏奖励环境下难以有效学习。现有的基于视觉模型的强化学习方法在处理长时程任务时,面临着奖励信号稀疏、视觉特征复杂以及难以捕捉关键任务序列等问题,导致学习效率低下和泛化能力不足。
核心思路:RoboHorizon的核心思路是利用预训练的大语言模型(LLM)的强大语义理解能力,为机器人操作任务生成密集的奖励信号,从而缓解稀疏奖励问题。同时,通过多视角感知和关键帧发现,增强机器人对任务关键步骤的理解和感知能力,从而提高学习效率和泛化能力。
技术框架:RoboHorizon采用Recognize-Sense-Plan-Act (RSPA) 流程。首先,Recognize阶段利用LLM根据任务指令生成密集奖励结构,将长时程任务分解为多个子任务并分配奖励。Sense阶段通过多视角MAE和关键帧发现,提取关键的任务序列特征。Plan阶段构建机器人世界模型,利用学习到的奖励和特征进行长时程任务规划。Act阶段通过强化学习算法执行规划的动作。
关键创新:RoboHorizon的关键创新在于将预训练的LLM引入到机器人操作任务中,利用LLM的语义理解能力生成密集奖励,从而克服了稀疏奖励问题。此外,将关键帧发现集成到多视角MAE架构中,增强了机器人对关键任务序列的感知能力。
关键设计:在奖励生成方面,LLM根据任务指令生成多阶段子任务的奖励函数。在多视角MAE中,使用掩码自编码器学习多视角图像的联合表示,并通过关键帧发现机制选择最具代表性的帧。在世界模型构建中,使用Transformer网络学习状态转移模型,并使用强化学习算法进行策略优化。
🖼️ 关键图片
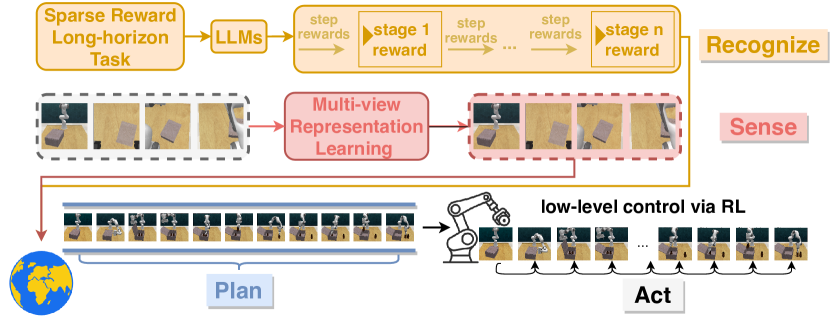
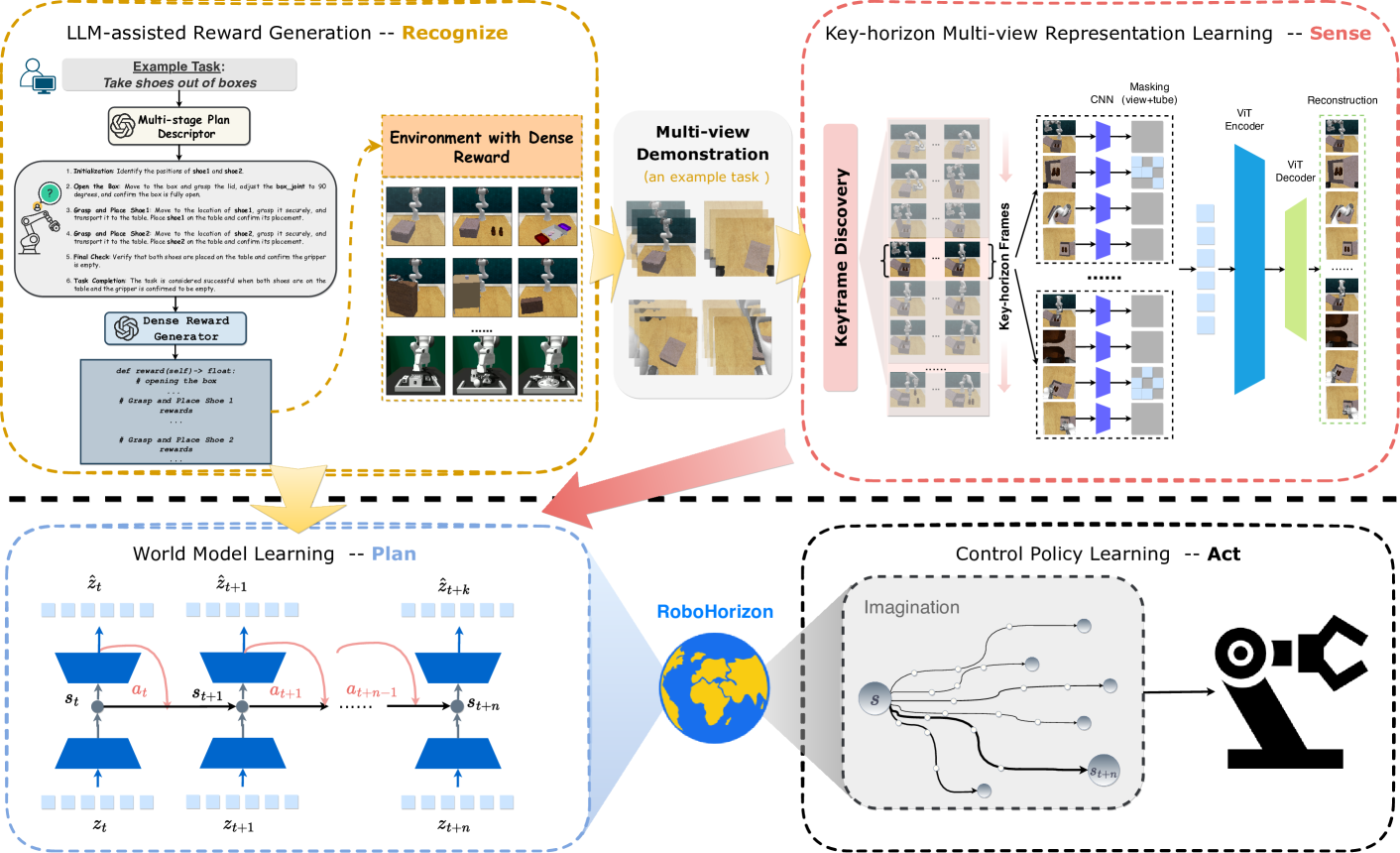

📊 实验亮点
RoboHorizon在RLBench和FurnitureBench两个基准测试中取得了显著的性能提升。在RLBench的4个短时程任务上,成功率提高了23.35%。在RLBench的6个长时程任务和FurnitureBench的3个家具组装任务上,成功率提高了29.23%。这些结果表明,RoboHorizon在长时程机器人操作任务中具有显著的优势。
🎯 应用场景
RoboHorizon具有广泛的应用前景,可应用于自动化装配、家庭服务机器人、医疗机器人等领域。通过提高机器人对长时程任务的理解和执行能力,可以实现更智能、更高效的自动化操作,从而降低人工成本,提高生产效率,并改善人们的生活质量。未来,该技术有望应用于更复杂的机器人任务,例如灾难救援、太空探索等。
📄 摘要(原文)
Efficient control in long-horizon robotic manipulation is challenging due to complex representation and policy learning requirements. Model-based visual reinforcement learning (RL) has shown great potential in addressing these challenges but still faces notable limitations, particularly in handling sparse rewards and complex visual features in long-horizon environments. To address these limitations, we propose the Recognize-Sense-Plan-Act (RSPA) pipeline for long-horizon tasks and further introduce RoboHorizon, an LLM-assisted multi-view world model tailored for long-horizon robotic manipulation. In RoboHorizon, pre-trained LLMs generate dense reward structures for multi-stage sub-tasks based on task language instructions, enabling robots to better recognize long-horizon tasks. Keyframe discovery is then integrated into the multi-view masked autoencoder (MAE) architecture to enhance the robot's ability to sense critical task sequences, strengthening its multi-stage perception of long-horizon processes. Leveraging these dense rewards and multi-view representations, a robotic world model is constructed to efficiently plan long-horizon tasks, enabling the robot to reliably act through RL algorithms. Experiments on two representative benchmarks, RLBench and FurnitureBench, show that RoboHorizon outperforms state-of-the-art visual model-based RL methods, achieving a 23.35% improvement in task success rates on RLBench's 4 short-horizon tasks and a 29.23% improvement on 6 long-horizon tasks from RLBench and 3 furniture assembly tasks from FurnitureBench.